

一种解偶人脸属性与化妆属性的妆容解偶迁移器
电子说
描述
在美颜软件必不可少的今天,自动化妆和妆容美化已经深入了每一个拍照、直播甚至是购物软件中。貌美如花的背后是人工智能和视觉技术的不断发展,面部妆容迁移是其中一项重要的技术,可以目标图像的化妆迁移到没有化妆的照片上,比如在挑选化妆品时就可以输入图像尝试模特的妆容是否适合。
但目前的算法大多集中于固定的场景和输出,无法适应多种多样的应用场景。为了灵活地进行妆容迁移,实现不同图像间妆容的迁移、互换、混合,平滑的调节妆容的浓度甚至生成新的样式,来自上海交大和浙大的研究人员提出了一种解偶人脸属性与化妆属性的妆容解偶迁移器,实现了任意图像间的妆容迁移、互换、混合与生成。

针对妆容迁移,目前的方法大多针对两幅图像间固定的妆容迁移,而在现实生活中对于美颜的需求缺不仅仅于此。不仅需要能够调节妆容的浓淡、融合不同的妆容效果,甚至还需要在没有参考图像的情况下为面部添加合适的妆。
在这篇文章中,研究人员提出了一种称为解偶妆容迁移器(disentangled makeup transer,DMT)的模型,基于解偶表示利用编码器将图像中涉及个人属性的特征和涉及妆容的特征进行分离,随后利用解码器对于妆容和人脸的编码重建出面部图像。
解偶表示使得任意妆容迁移称为可能,同时让妆容的强度可调、也可以通过采样化妆编码来实不同妆容的生成。DMT模型一共分为了四个部分:人脸身份编码器Ei、妆容编码器Em,生成器G和判别器D。模型架构如下图所示:
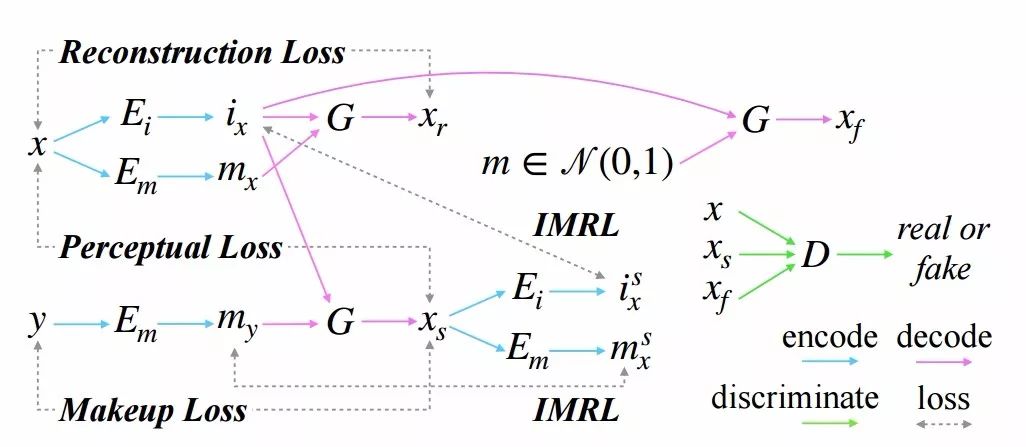
模型中一共包含了五个部分的损失,除了通常的对抗损失外,生成器G还包括图像的重建损失Lrec、妆容迁移后的感知损失Lper、迁移后的妆容损失Lmak以及保证一对一人脸化妆编码的重建损失Limr。
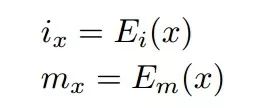
针对某一张输入的图像x,编码器首先从其中抽取出了人脸编码ix和妆容编码mx。基于解偶表示,我们得到的ix是与化妆不相关的人脸特征、衣着与背景,而mx则是独立的表示化妆的编码。通过ix与mx的重建首先得到了第一个损失函数,来表达生成器对于输入图像的重建能力:
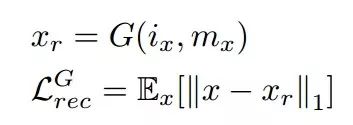
在重建损失后就需要利用其他额外的损失来控制妆容迁移的质量了。我们假设有另一张图像y,利用妆容编码器得到了对应的化妆编码my,这时候就可以利用上一步生成的人脸编码ix与这里的新的妆容my合成新的图像xs,这就是换妆后的图像。此时可以利用这张合成妆容的图像得到三个损失。首先利用预训练的模型抽取出高层次特征,将合成的图像xs与原始人物x的面部特征进行比较得到人物面部的感知损失:
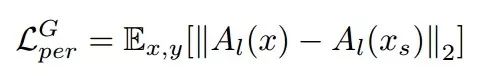
随后需要利用化妆损失来约束模型,看看生成的图像xs中是否得到了y的妆容。
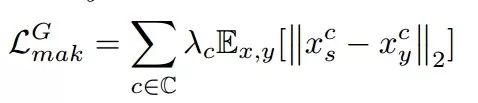
这时候研究人员针对面部的不同区域进行的损失计算,利用语义分割来得到各个感兴趣的区域。

包括面部、额头、眼睛、嘴唇等区域,并通过直方图匹配来得到与y对应的x作为gt进行计算:
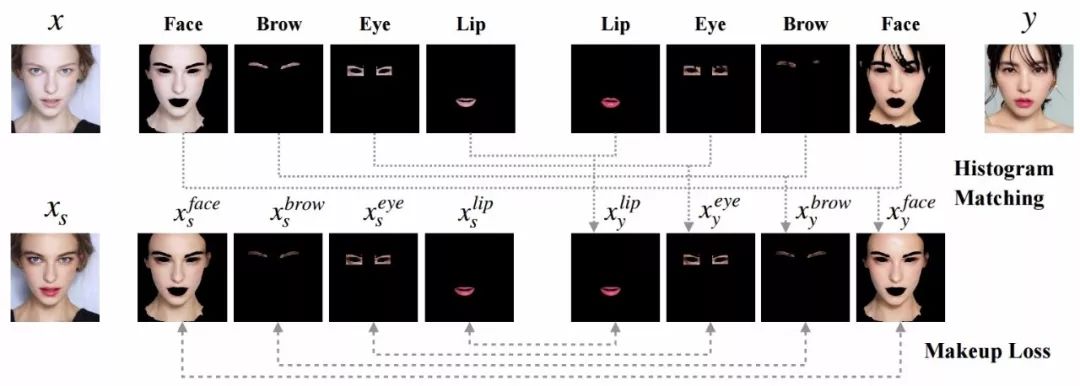
图中可以看到,首先将输入图像根据不同区域,与目标妆容图像进行直方图匹配作为基准,随后利用生成的图像与这一基准进行比较得到化妆损失。
最后为了保证图像与面部编码/化妆编码一一对应,研究人员还引入了IMRL(identity makeup reconstruction loss)损失,解偶的表达在编解码过程中保持一致:
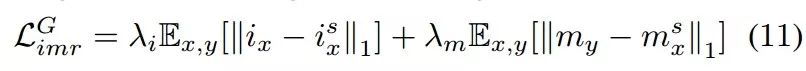
在一对一妆容迁移的基础上,研究人员还探索了妆容浓淡插值算法,利用一个强度因子将化妆编码mx,my进行插值,就可以得到在x,y妆容间平滑渐变的妆容了。
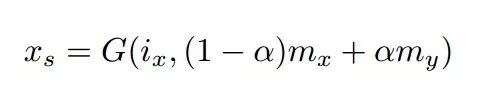
如果要混合多个妆容,只需要将多个化妆编码进行加权并利用生成器解码即可:
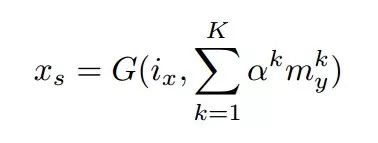
如果想生成新的妆容而不依赖于任何参考图像,就可以从化妆编码m所在的分布中进行采样,并将采样得到的编码与人脸编码一起进行解码实现随机的妆容输出。
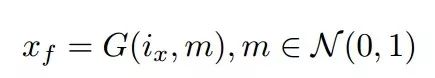
为了更为精细化地处理图像的妆容迁移,研究人员提出了一种掩膜注意力机制,使得模型在合成图像的时候只针对眼部、嘴唇等特定的感兴趣区域进行操作,而保留背景、衣着和与妆容无关的区域,在生成合成图像时同时也会得到一张掩膜,最终根据掩膜、原始图像与合成妆容图像实现了精细化的妆容迁移图像输入:
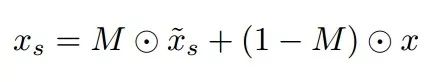

M是模型生成掩膜,M'是标注的化妆相关区域掩膜
最终的损失函数就是以上各项与对抗损失的加和形式,其中不同的权重代表了不同项目在模型中对应的重要性。最终提出的模型架构如下:
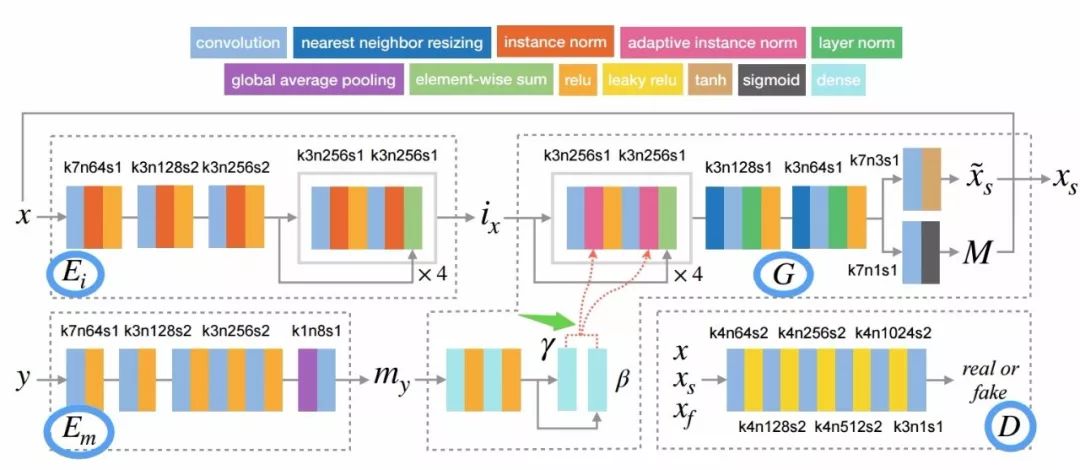
其中包含了人脸属性编码器、化妆编码器、生成器和判别器等。为了保证原始的妆容属性,在化妆编码器中没有使用归一化层。因为归一化会改变妆的均值和方差,而这些对于妆容属性特别重要。
此外为了融合人脸编码ix与妆容编码my,研究人员将妆容编码my转换成了两个隐变量γ和β,作为动态均值和方差输入生成器G中。研究人员Makeup Transfer(MT)数据上进行了训练和测试,这一数据集包含了1115张无妆和2719张化妆照片。同时还分别检验了前面提到的各项损失对于网络整体性能的影响,下图可以看到人脸各个部分的妆容损失函数对于妆容的影响特别明显:

同时注意力机制和感知损失也会显著影响图像妆容迁移的质量。在不使用mask和注意力机制的情况下背景会受到比较大的改变。上图中现实了妆容迁移后与原图的差分图像结果。

研究人员将提出的算法DMT与其他的算法进行了充分的对比,DMT可以在充分迁移妆容的基础上保留与妆容无关的内容:
随后还充分比较了表现较好的BeautyGAN,虽然BG可以实现和逼真自然的妆容迁移,但是不可避免的对于不相关区域造成改变,而专注于化妆区域学习的DMT在多个指标上都呈现了更好的效果。
研究人员还对不同妆容的图像进行了降为的可视化分析,基于妆容编码向量在二维空间中进行显示。可以看到妆容相似的图像被分类在了一起,红唇都在左上方,小清新都集中在了左下方的图片中,而欧美烟熏妆和韩式妆容也各自聚集在了一起,这证明了妆容编码器的表示有效区分了不同数据妆容属性,具有很强的可解释性。
最后让我们一起来看看这个模型得到的惊艳效果吧!
妆容编码线性插值下的变妆女神:
混合妆容也魅力十足:
人脸妆容插值下的无穷变幻
妆容、面容都在变换,哪个妆才是你的最爱?
多模态下的混合采样
化妆创意从此不再是问题!
在实验中研究人员还探究了妆容编码中的每一个分量各自的影响,可以看到m向量中不同的分量负责化妆不同的属性。例如m7与嘴唇的颜色和面部的黄白色调有着直接的联系,这样就可以针对性的调节向量分量来实现更多美妆效果了。
-
[推荐][原创]影视化妆/影视化妆学校/影视化妆课程/影视化妆班2010-01-20 0
-
属性节点和调用节点的使用教程2012-01-05 0
-
一种基于FPGA的高速导航解算方法设计2019-07-03 0
-
一种基于滑模观测器的电流偏差解耦控制方法2021-08-27 0
-
DigiPCBA 库迁移系列 - 属性面板2022-07-22 0
-
中文专利属性值对抽取技术及应用2017-12-01 498
-
一种多属性匹配决策方法2017-12-14 821
-
一种统计属性约简的定义2017-12-25 863
-
基于节点连接结构和属性值的属性图聚类匿名化方法2017-12-26 557
-
一种基于属性的LSSS密钥加密方案2021-05-11 911
-
一种基于多任务学习的人脸属性识别方法2021-05-27 681
-
如何访问库迁移器的相关属性面板2022-07-22 699
-
placeholder属性和value属性的差别2023-11-30 462
全部0条评论

快来发表一下你的评论吧 !
