

作为一个快速简便的数据仓库,Snowflake可以动态扩展
描述
作为一个快速简便的数据仓库,Snowflake可以动态扩展,以便在企业需要时为其提供所需的性能。
数据仓库,也称为企业数据仓库(EDW),是用于分析的高度并行的SQL或NoSQL数据库。它们允许企业从多个源导入数据,并从数PB的数据中快速生成复杂的报告。
数据仓库和数据集市之间的区别在于,数据集市通常仅限于单个主题和单个部门。数据仓库和数据湖之间的区别在于数据湖以其自然格式(通常是blob或文件)存储数据,而数据仓库将数据存储为数据库。
Snowflake简介
Snowflake是一个完全关联的ANSI SQL数据仓库,它是从头开始为云计算而构建的。它的架构将计算与存储分开,这样即使在查询运行时,用户也可以在不延迟或中断的情况下动态地扩展。当用户需要的时候,就能得到其所需要的性能,而且只需要为其所使用的计算资源支付费用。Snowflake目前运行在亚马逊网络服务和微软Azure云平台上。
Snowflake是一个具有矢量化执行的全列数据库,使它能够处理最苛刻的分析工作负载。Snowflake的自适应优化可以确保查询自动获得最佳性能,而无需管理索引、分发键或优化参数。
Snowflake凭借其独特的多集群共享数据架构可以支持无限制的并发性。这允许多个计算集群在同一数据上同时运行,而不会降低性能。Snowflake甚至可以自动扩展以通过其多集群虚拟仓库功能处理不同的并发需求,在峰值负载期间透明地添加计算资源,并在负载减少时缩小规模。
Snowflake的竞争对手
Snowflake在云端的竞争对手包括Amazon Redshif、Google BigQuery和Microsoft Azure SQL数据仓库。其他主要竞争对手,如Teradata、Oracle Exadata,MarkLogic和SAP BW/4HANA,可以安装在云端、内部部署和设备上。
Amazon Redshift
Amazon Redshift是一个快速可扩展的数据仓库,可让用户分析数据仓库和Amazon S3数据湖中的所有数据。用户使用SQL查询Redshift。Redshift数据仓库是一个可以使用并发查询负载自动部署和删除容量的集群。但是,所有集群节点都在同一可用区中进行配置。
Microsoft Azure SQL数据仓库
Microsoft Azure SQL数据仓库是一个基于云计算的数据仓库,它使用Microsoft SQL引擎和MPP(大规模并行处理)快速运行跨PB数据的复杂查询。通过使用简单的PolyBase T-SQL查询将大数据导入SQL数据仓库,然后使用大规模并行处理(MPP)的强大功能运行高性能分析,用户可以将Azure SQL数据仓库用作大数据解决方案的关键组件。
Azure SQL数据仓库在全球40个Azure云区域中可用,但给定的仓库服务器仅存在于单个云区域中。用户可以按需扩展数据仓库性能,但任何正在运行的查询都将被取消并回滚。
Google BigQuery
Google BigQuery是一个无服务器,高度可扩展且经济高效的云计算数据仓库,内置GIS查询、内置BI引擎和内置的机器学习功能。BigQuery可以快速运行数PB的SQL查询,并且可以直接加入公共或包含数据的商业数据集。
用户只能在创建时设置BigQuery数据集的地理位置。查询中引用的所有表必须存储在同一位置的数据集中。这也适用于外部数据集和存储桶。外部Google Cloud Bigtable数据的位置还有其他限制。在默认情况下,查询与数据在同一区域中运行。
其运行的地点可以是特定的地方,如弗吉尼亚州北部,也可以是更大的地理区域,如欧盟或美国。要将BigQuery数据集从一个区域移动到另一个区域,用户必须将其导出到与数据集位于同一位置的Google云存储桶,将存储桶复制到新位置,然后将其加载到新位置的BigQuery中。
Snowflake架构
Snowflake使用虚拟计算实例来满足其计算需求,并使用存储服务来持久存储数据。 Snowflake无法在私有云基础设施(内部部署或托管)上运行。
没有要执行的安装,也没有配置。所有维护和调整均由Snowflake处理。
Snowflake使用中央数据存储库来存储可从数据仓库中的所有计算节点访问的持久数据。同时,Snowflake使用大规模并行处理(MPP)计算集群处理查询,其中集群中的每个节点在本地存储整个数据集的一部分。
当数据加载到Snowflake中时,Snowflake会将该数据重新组织为其内部压缩的列式格式。内部数据对象只能通过SQL查询访问。用户可以通过其Web UI、CLI(SnowSQL),来自Tableau等应用程序的ODBC和JDBC驱动程序,通过编程语言的本机连接器以及BI和ETL工具的第三方连接器连接到Snowflake。
Snowflake架构图。需要注意,虚拟仓库的CPU资源可以独立于数据库存储进行扩展。
Snowflake功能
安全和数据保护。Snowflake提供的安全功能因版本而异。甚至标准版也提供所有数据的自动加密功能,并支持多因素身份验证和单点登录。企业版增加了加密数据的定期重新密钥,企业版增加了对HIPAA和PCI DSS的支持。用户可以选择数据的存储位置,这有助于符合欧盟GDPR法规。
标准和扩展SQL支持。Snowflake支持SQL:1999中定义的大多数DDL和DML,以及事务,一些高级SQL功能以及SQL:2003分析扩展(窗口函数和分组集)的部分内容。它还支持横向和物化视图、聚合函数、存储过程和用户定义的函数。
工具和接口。值得注意的是,Snowflake允许用户从GUI或命令行控制虚拟仓库。这包括创建、调整大小(零停机时间)、暂停和删除仓库。在查询运行时调整仓库大小非常方便,尤其是当用户需要加速花费太多时间的查询时。然而,任何其他EDW软件都没有实现。
连接Snowflake具有Python、Spark、Node.js、Go、.Net、JDBC、ODBC和dplyr-snowflakedb的连接器和/或驱动程序,这是在GitHub上维护的开源dplyr包扩展。
数据导入和导出。Snowflake可以加载各种数据和文件格式。那包括压缩文件;分隔数据文件;JSON、Avro、ORC、Parquet和XML格式;Amazon S3数据源;本地文件。它可以批量加载和卸载表格,以及从文件中连续批量加载。
数据共享。Snowflake支持与其他Snowflake帐户安全地共享数据。通过使用零拷贝表克隆简化了这一过程。
Snowflake的价格因版本和地点而异。其功能因版本而异,VPS实例目前仅在AWS上可用。
Snowflake教程
Snowflake提供了不少教程和视频。一些教程帮助用户入门,一些教程探索特定主题,还有一些可以演示功能。
建议用户完成《Snowflake免费试用实践实验室指南》中描述的实践。这应该足以导入一些真实数据,并测试一些查询。
这个教程大量使用Snowflake工作表,这是在Web UI中运行命令和SQL的便捷方式。除其他外,其中包括数据加载、查询、结果缓存和克隆、半结构化数据以及恢复数据库对象的时间旅行。
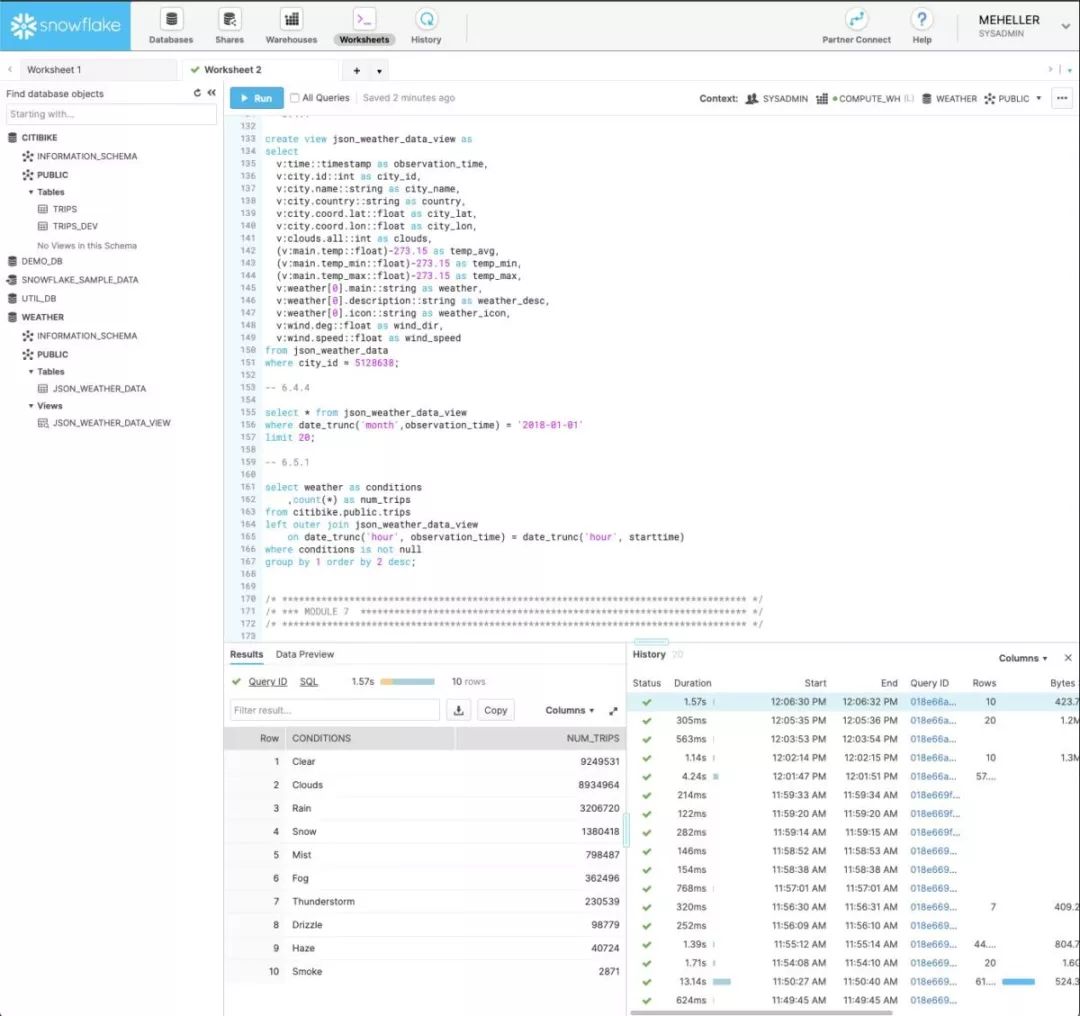
实践教程中的Snowflake工作表(右上角)。模式信息位于左上角,查询结果位于左下角,带有时序的查询历史记录位于右下角。
总的来说,发现Snowflake令人印象深刻。原以为它会很笨重,但事实并非如此。实际上,它的许多数据仓库操作都比人们预期的要快得多,当有一个数据仓库似乎在缓步前行时,可以在不中断正在发生的事情的情况下进行干预,并增加数据仓库的大小。
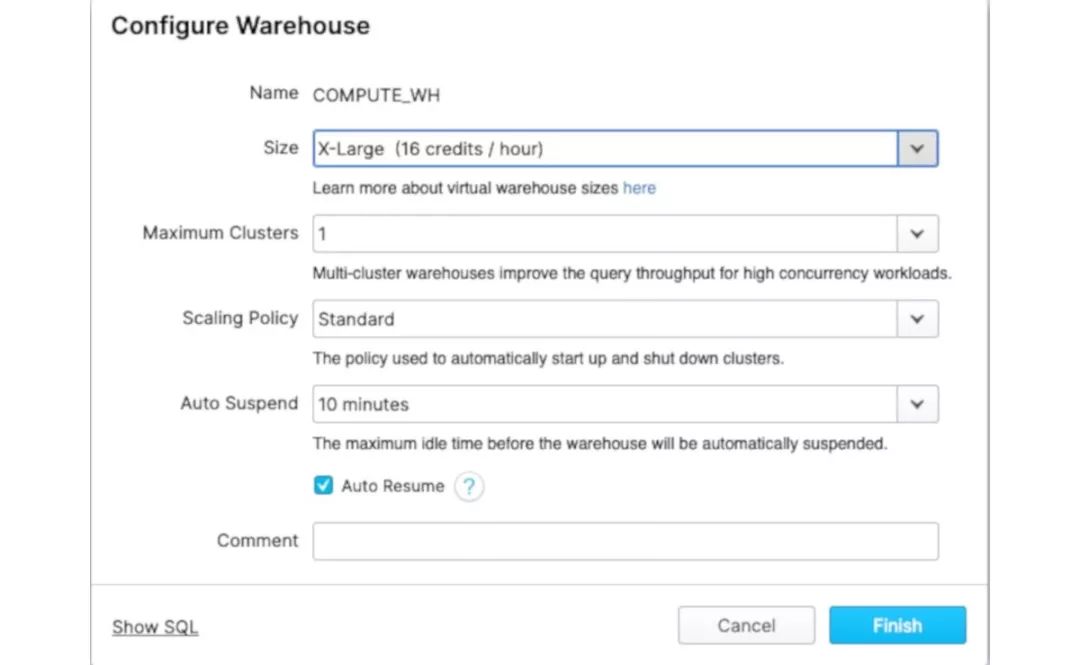
Snowflake数据仓库配置对话框。有各种各样的大小,有几种选项可以自动进行集群扩展。
大部分扩展都可以自动化。在创建数据仓库时(参见上面的屏幕截图),可以选择允许多个集群,设置扩展策略的选项、自动挂起的选项,以及自动恢复选项。默认的自动挂起时间为10分钟,这使得数据仓库在空闲时间超过该时间时不会消耗资源。自动恢复几乎是即时的,只要对数据仓库进行查询就会发生。
考虑到Snowflake提供30天的免费试用期,有400美元的信用额度,而且不需要安装任何软件,用户应该能够确定Snowflake是否适合其目的,而无需任何现金支出。
费用:2美元/信用额外加上23美元/TB/月的存储空间,并且存储空间需要预付费。一个信用额度等于一个节点*小时,按秒计费。更高级别的计划成本更加昂贵。
-
数据仓库解决方案的实施过程是什么?#数据仓库 #光点科技光点科技 2023-06-19
-
基于阿里云数加MaxCompute的企业大数据仓库架构建设思路2018-03-15 0
-
大数据之Hive数据仓库2019-03-19 0
-
数据仓库的概述以及创建步骤简介2020-06-09 0
-
统计行业数据仓库构建及应用2009-09-16 460
-
电信数据仓库设计2009-12-18 760
-
基于XML的数据仓库概念模型设计2009-12-18 614
-
OLAP在电信数据仓库中的设计2010-12-29 924
-
保护MySQL数据仓库的最佳实践2017-09-27 704
-
数据仓库是什么_数据仓库的特点_数据仓库与数据库区别2018-02-11 23680
-
数据仓库是什么_数据仓库有什么特点_数据库和数据仓库区别分析2018-02-24 19270
-
如何搭建数据仓库2019-06-25 1962
-
大数据数据仓库应该如何建设2020-03-10 820
-
什么是数据仓库?数据仓库的优势分析2020-11-01 9407
-
玉米赤霉烯酮检测仪,快速简便2021-12-09 327
全部0条评论

快来发表一下你的评论吧 !
