

实时计算在贝壳的实践
今日头条
描述
摘要:Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。本文由贝壳找房的资深工程师刘力云将带来Apache Flink技术在贝壳找房业务中的应用,通过企业开发的实时计算平台案例的分享帮助用户了解Apache Flink的技术特性与应用场景。
业务规模及演进
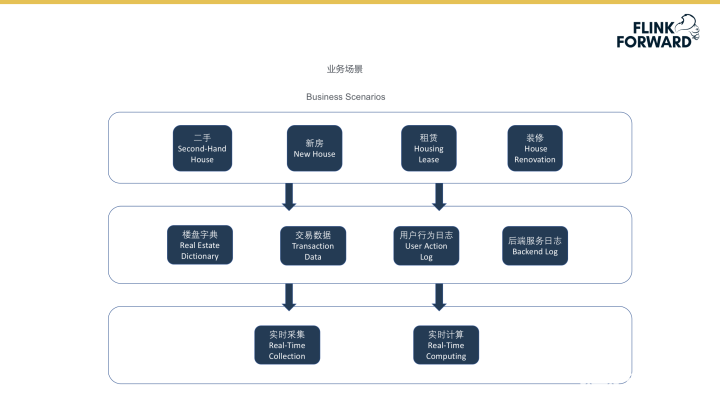
下图为贝壳找房的业务场景示意图。最上层为贝壳找房公司最为主体的四大业务:二手房交易、新房交易、租赁业务及装修业务。四大业务运营将产生图示中间部分的四大数据即楼盘字典、交易数据、用户行为日志与后端服务日志。图示最下部分代表公司实时数据采集、实时数据计算的业务模块,本文中的案例将重点介绍数据实时计算部分的设计、实现及应用内容。
发展历程
在2018年初,随着公司埋点治理规范的推进,我们建设了DP实时数据总线,统一承接各种埋点数据流的标准化处理,并对外提供清洗后的实时数据。随着维护的实时任务增加,面临着实时数据流稳定性以及任务管理方面的挑战,于是贝壳大数据部着手研发了Hermes实时计算平台,提供统一的实时任务管理平台。
在2018年10月,我们推出了SQL V1编辑器来方便用户开发实时计算任务。SQL V1基于Spark Structured Streaming技术,用户可以使用SQL完成需求的开发,同时以界面拖拽的形式呈现给用户,使用户的操作更加便捷。在2019年5月,经过调研对比,我们引入了Flink技术栈,研发的SQL V2编辑器正式上线,SQL V2全面支持Flink SQL的各种语法并设计了大量的自定义函数,兼容hive UDF以及用户常用函数。目前我们已经在公司内进行实时数仓业务场景的探索应用。

应用规模
下图所示为目前实时计算在贝壳找房企业中的应用规模。目前平台支持30余个业务项目,流计算任务数达到400个,随着数仓的不断扩充,实时流计算的任务数将不断上升。每日处理的消息条数达到了800亿级别,效率十分可观。

支持的项目
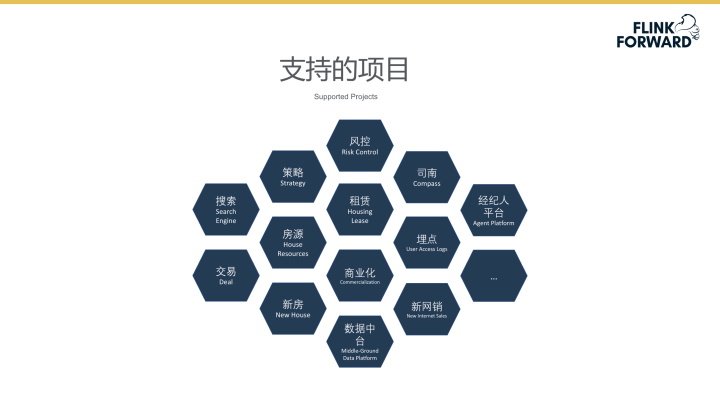
从下图所示实时计算在企业中的支持项目可以看出,目前实时计算平台支持从风控、租赁到策略搜索再到新房交易等一系列业务项目,从各个维度支持起了企业运营产生出数据实时计算业务需求。
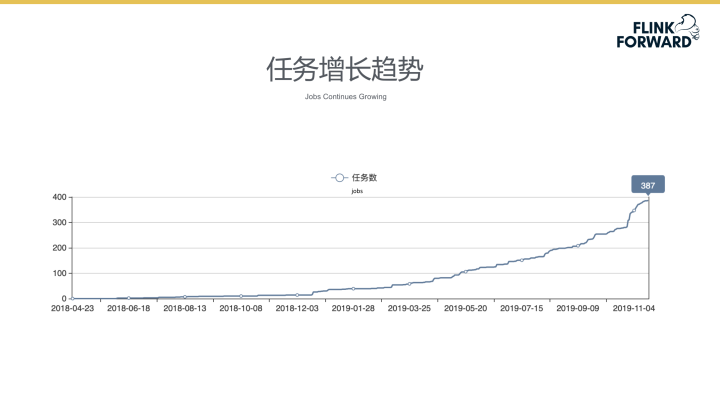
任务增长趋势
最开始平台上线时支持的任务增长较为缓慢,在2019年6月初,平台升级到Flink并全面支持SQL开发后,任务数量开始大规模的增长,在2019年11月份实时数仓建成后,平台所支持的任务数量有了十分明显的增长趋势。
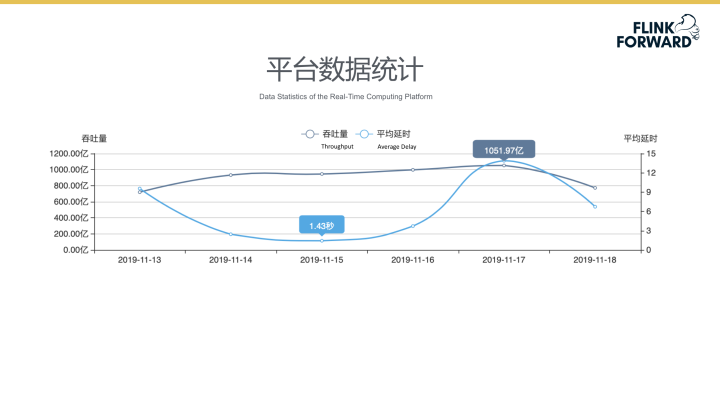
平台数据统计
下图所示为平台每日数据统计。目前平台每日可以处理1000亿条数据,一般数据任务的处理延迟在40毫秒左右。
Hermes实时计算平台介绍
平台概览
Hermes平台目前支持着公司实时任务的开发、编辑、部署、启停等管理功能及丰富的监控报警等服务。平台支持Java、Scala、Python等多种语言开发的实时任务,支持自定义任务、模板任务及场景任务三大任务类型,同时做到了各个项目的资源隔离,每个项目均有项目的专有队列,防止与其他项目在资源上发生竞争。平台同时为资源需求较小的项目提供了公共队列,通过公共队列对该种项目进行支持的方式,更为方便的实现任务的开发。

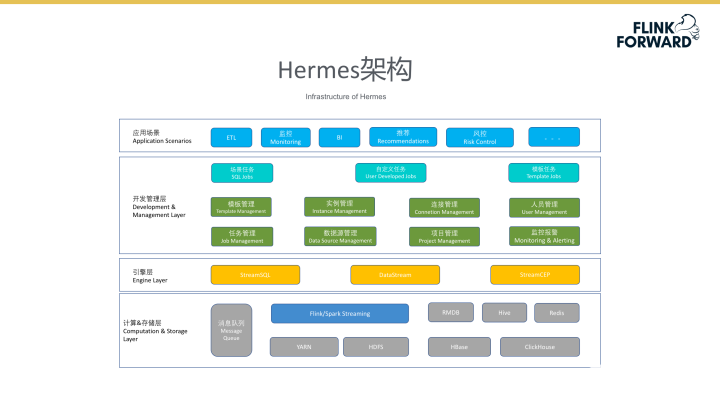
Hermes架构
下图所示为Hermes平台的整体架构,架构分为4个层次,图中最下层深蓝条目代表架构中的计算引擎,目前计算引擎支持Flink与Spark Streaming技术,并通过消息队列、离线存储等技术辅助完成数据实时的存储。在引擎层方面,架构采用StreamSQL、DataStream、StreamCEP等技术搭建,其中StreamCEP技术很好的支持了经纪人平台业务实时监控报警的需求。功能组件层方面包括了任务实例的管理、项目管理及数据源管理等。平台目前可以在同一任务中的不同任务快照间进行相互切换,当发现上线任务有问题时,可以回退到之前的快照。
SQL V1编辑器
下图所示为SQL V1编辑器示意图。该编辑器对于大部分数据清洗及数据处理的业务场景可以实现简洁高效的编辑处理。用户在编辑器左侧可以定义编辑数据源、操作符及目标源等数据信息。中央面板上呈现的数据为SQL V1支持编辑的操作类型,选中面板中央的过滤器,即可在编辑器右侧添加相关的过滤条件,实现数据的相关过滤。在目标源层面,编辑器目前支持Kafka、Druid等多种目标源,大大提升了编辑器的兼容性。

SQL V2编辑器
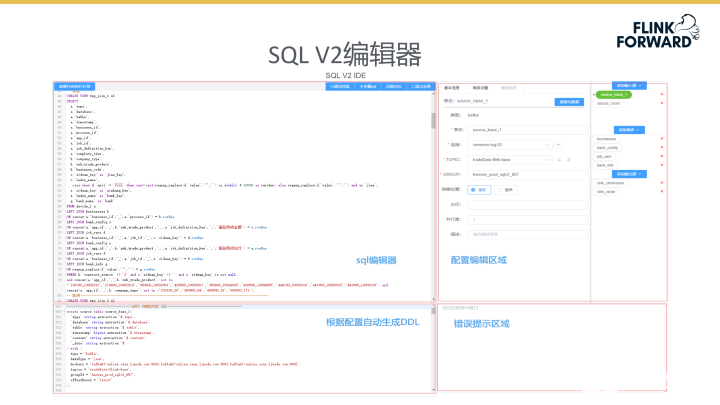
下图所示为SQL V2编辑器示意图。目前SQL V2是基于Flink SQL技术较为完善的编辑器,左侧为用户进行代码编辑的部分,用户在此处可以编辑大量SQL语句以此助力不同业务场景。左下栏目中的数据为用户选中数据源自动生成的DDL,通过DDL编辑器将操作数据的样式更清晰的展示给用户。SQL V2支持了三大类型的数据表,分别是source表、sink表及维表,以此方便用户的开发。编辑器右下角可以呈现SQL语法的检测情况,以此提示用户在编辑时出现的语法错误。
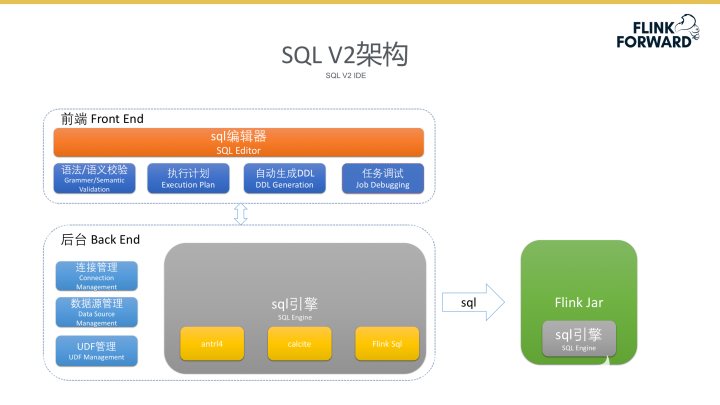
SQL V2架构
SQL V2工具整体架构如下图所示。前端SQL编辑器模块包括语法语义的检查、执行计划的查看、自动DDL的生成及任务调试的功能。用户通过任务调试功能可以查看任务执行结果。后台将引擎提交到Yarn集群上执行,引擎通过任务id回调后台接口获取需要执行的SQL,对SQL做语法校验和语法解析,若出现维表关联则会额外对SQL做一层转换。
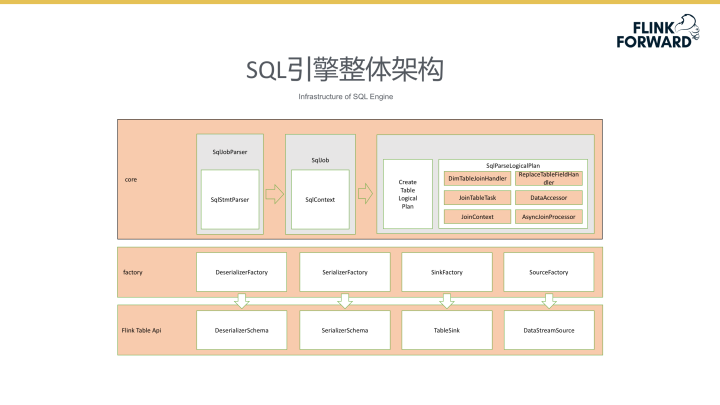
SQL引擎整体架构
下图所示为SQL引擎的整体架构。整体架构分为三个层次,最底层为Flink Table API。在Flink层之上企业设计了代码的封装,以factory的形式方便最上层的方法调用。最上层的core层负责整个系统的SQL解析。
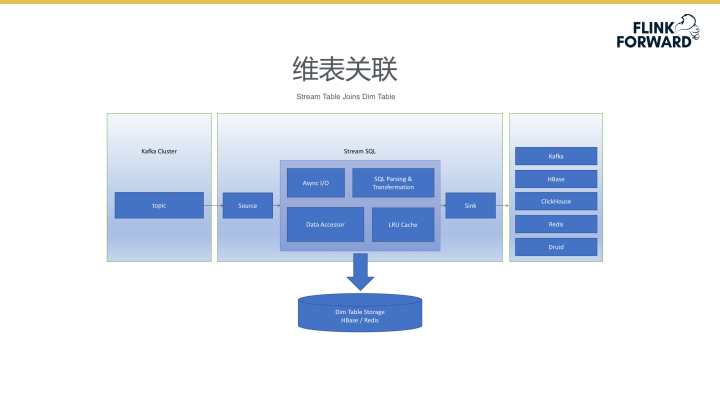
维表关联
在SQL解析过程中,最为复杂的是维表的表格关联,下图为维表关联系统架构图。数据从数据源导入后,系统使用Async I/O技术访问后端,系统后端使用Data Accessor接口访问后端的存储。系统后端存储支持HBase与Redis存储技术,同时后端会将数据缓存于LRU Cache模块中。维表关联后的数据支持多种大数据工具的存储,从而大大增加了系统的兼容性。
丰富的内置函数
系统同时为用户提供了丰富的内置函数,包括时间函数、集合函数、Json处理函数及字符串函数。丰富的内置函数可以方便用户的开发,省去用户自己去开发的时间。
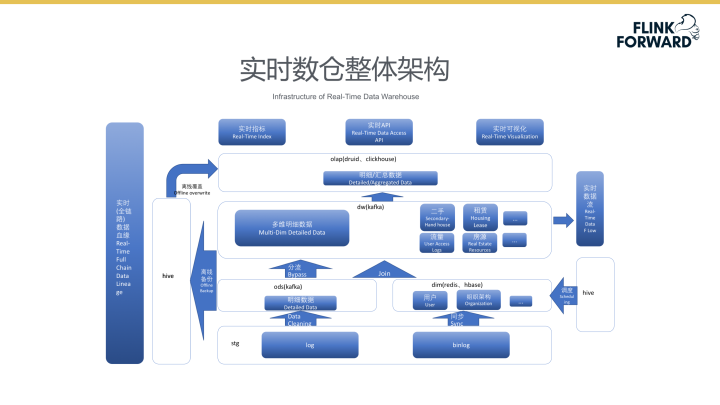
实时数仓整体架构
下图所示为实时数仓的整体架构,同时也是SQL V2系统落地的应用场景。各个层级间产生的数据被储存在了Kafka Topic中,同时数据也将被同步到hive中备份。业务方可以查询实时备份数据进行数据验证及分析等操作。目前数仓的实时计算部分可以计算当天或过往几天的数据,实时计算平台正在与其他组件合作,开发实时与离线联合的分析查询,以此扩展实时数仓的使用范围。
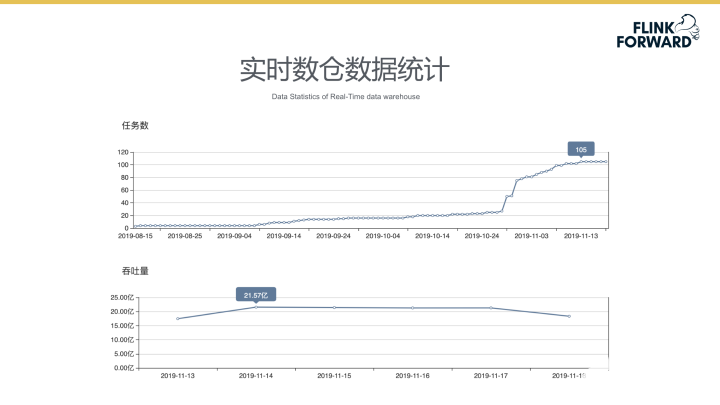
实时数仓数据统计
下图所示为企业实时数仓的数据统计。从2019年8月,SQL V2正式上线运营,至2019年10月平台开始支持实时数仓开发,系统的数据量开始加速增长。目前,实时数仓已经有100余个任务,数据吞吐量也达到了21亿条/天的数据级别,数据规模较为可观。
实时数仓案例
下图列举出实时数仓平台已经实现提供数据支持的应用案例。
1. 交易平台
交易平台实时大屏实时展示大区内的交易状况。在交易平台的建设中,开发团队通过数据回环将还未关联的数据返回储存模块进行重新关联,并通过检验该数据的生命周期判断是否关联成功,团队通过此种方式使得数据维表与事实表数据最终一致。
2. 经纪人行程量
经纪人行程量可以动态的展示当前经纪人对客户的维护情况,使企业可以掌握经纪人实时的工作状态。
3. 实时用户画像
实时用户画像可以实时地向企业呈现来自各个系统用户的数据信息,通过组合各个平台上用户的行为信息,提供全面、精准的用户画像。企业的算法策略部门将根据用户的实时画像进行相关信息、内容的推荐。

监控报警
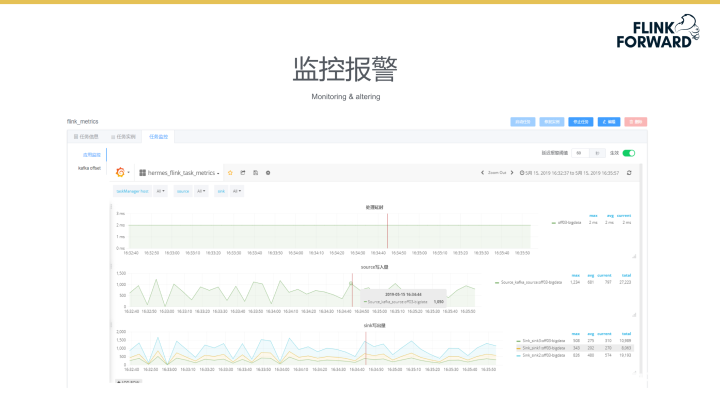
下图为平台的监控报警页面截图。监控系统会实时监控平台任务的处理延时、source写入量及sink写出量三大指标。系统中同时可以设置平台数据的无心跳时间,当超出设置时限后,系统将会进行报警。
监控报警架构
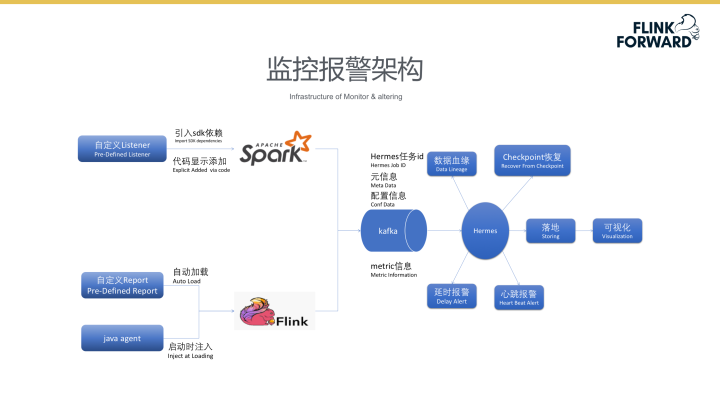
下图为监控报警架构图。监控系统通过自定义的Listener对Spark进行监控,Listener引入SDK收集Spark任务的信息及运行中的日志数据。用户在此处需要进行手动SDK的导入。在Flink应用模块中,系统设计支持了自定义Report数据的获取,并通过自动加载的方式直接载入Flink中进行数据的分析与计算,同时通过任务启动是注入java探针的方式获取任务的相关信息。所有的监控信息将被统一送到Kafka Topic中,经Hermes平台分析处理,触发相应的延时报警及心跳报警。
未来发展与规划
整体架构
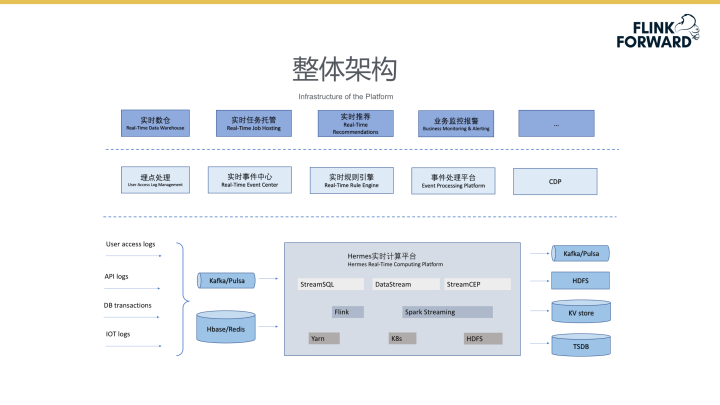
实时计算平台的整体架构如下图所示。在架构中间部分,平台包含了实时事件中心、事件处理平台等系统来更好的处理未来企业中的业务场景需求,以通用服务平台的方式为更多的业务方提供统一的业务支撑。在引擎方面,未来会深入研究Flink的状态管理、端到端的精确一次等技术,提高数据处理的准确性和一致性。
-
实时定时计数器中断2018-01-24 0
-
ARMS: 原来实时计算可以这么简单!2018-06-19 0
-
怎么实时计算模拟信号的FFT?2019-04-25 0
-
Spark Streaming和Kafka做实时计算的注意点2020-04-17 0
-
云计算在电信中应用思考2010-05-10 1943
-
单片机延时计算小程序2016-12-01 770
-
下一代大数据处理引擎,阿里云实时计算独享模式重磅发布2018-11-15 161
-
雾计算在物联网中的应用2020-09-01 972
-
腾讯云大数据平台d的算力资源池达500万核,日实时计算量超40万亿2020-09-11 670
-
基于赛灵思提供的实时计算平台的超低时延视频流解决方案2021-04-16 2059
-
实时计算机控制系统原理及应用综述2021-08-31 748
-
金融机构如何构建实时计算能力2022-01-20 1598
-
网易传媒基于Arctic的低成本准实时计算实践2022-11-15 514
-
实时计算汽车数量开源分享2023-06-28 192
全部0条评论

快来发表一下你的评论吧 !
