

带有饱和处理功能的并行乘加单元设计
FPGA/ASIC技术
描述
带有饱和处理功能的并行乘加单元设计
本文介绍了一种48bit+24bit×24bit带饱和处理的MAC单元设计。在乘法器的设计中,采用改进的booth 算法来减少部分积的数目,用由压缩单元组成的Wallace tree将产生的部分积相加,并将被加数作为乘法器的一个部分积参与到Wallace tree阵列中来完成乘加运算,同时增加了饱和检测和饱和值运算逻辑来实现饱和处理。
关键词:booth算法; Wallace tree ;饱和处理;饱和检测
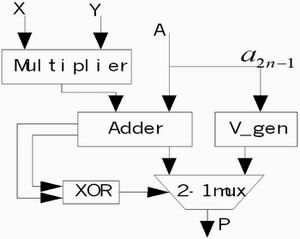
图1 饱和MAC结构框图
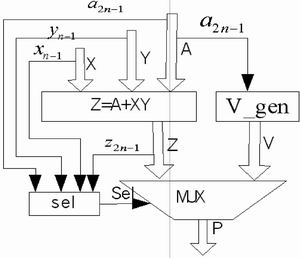
图2 优化后的饱和MAC结构框图
引言
在一些数字信号处理应用,如数字滤波、语音编码、图形处理等领域中,要大量反复地进行饱和处理操作。所谓饱和处理操作,是指当两个n位操作数相运算时,如果结果发生溢出,则取其饱和值。对于用补码表示的n位二进制数,正的饱和值为011…11,负的饱和值为100…00。饱和处理操作一般要用到两个周期,在第一个周期中处理算术运算操作,在第二个周期中处理饱和操作。更加复杂的操作,例如MAC操作,一般是在分别完成乘法和加法运算之后再进行饱和处理,这通常需要更多的周期。而并行饱和运算操作则是在一个周期之内取得串行操作的结果,这需要更多的硬件电路来实现。
本文设计了一种MAC单元,实现
=
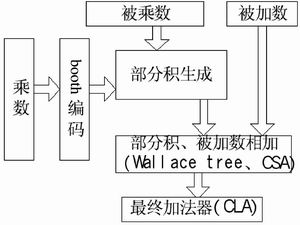
图3 24×24高速乘加器的结构框图
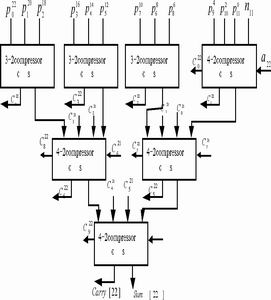
图4 并行乘加器中最大的Wallace tree 结构
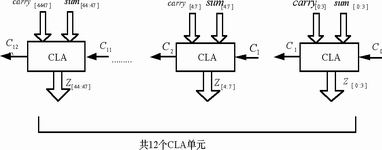
图5 最终加法器的实现
饱和乘加单元基本结构
为了实现
=
为了提高MAC单元的性能,本文对上面提到的结构进行了优化, 优化后的结构如图2所示。 将MAC单元的被加数作为乘法器的一个部分积,参与到部分积加法阵列中,这样就可以省去完成乘法计算后再进行加法计算的操作,缩短关键路径上的延时。
高速并行乘加单元结构
本文选用修正booth算法和Wallace tree结构实现24×24高速并行乘法器。图3是24×24高速乘加器的结构框图,主要由booth编码、部分积阵列、Wallace tree以及最终加法器构成。
booth编码
被乘数、乘数分别为n位补码表示的有符号数,在MBA(修正booth算法)中:
部分积的数目=,不失一般性,在这里只讨论n为偶数的情况。
设: X=-an-12n-1+2i;
Y=-bn-12n-1+2i;
根据MBA,对乘数进行以下变换:
Y=-bn-12n-1+2i
=
在这里a-1=0;
令其中i=0,1,2,…(n/2-1);则
;
;
由上式可以看到加法计算量减少了一半,同时可以看出Ki+1X相对于KiX需要左移两位。
在MBA中,乘数被划分成2位的块,对于第j个块,块中的2位(b2j+1,b2j)和前一个块中的高位b2j-1重新进行编码,编码真值表为:
符号扩展及部分积产生
在部分积生成过程中,符号位的扩展随部分积一起产生,我们将所有的扩展符号位相加:
由于和是48位的,故将上式中第一项舍掉,得:
;
对于部分积的产生,如果乘数经booth重编码后Ki为负,则需将部分积取反后加1,如表1所示。因此,在设计中可将每一个部分积的最后一位与ni相加,booth编码值为负时ni=1;编码值为正时ni=0。
部分积及被加数相加
Wallace tree是通过提高电路的并行度来提高电路速度的一种实现结构,它将所有的部分积在同一时刻相互独立地并行加到电路中,从而提高运算速度。在Wallace tree结构里面,我们用压缩单元将乘法操作过程中产生的部分积以及被加数相加。在本设计中,我们把被加数作为一个部分积,加到Wallace tree阵列中,这样就可以省去完成乘法运算后再进行加法运算的操作延迟,提高MAC单元速度。
最大的树由3个3-2压缩单元和4个4-2压缩单元组成,树的高度只有3级,这比只用全加器实现时的高度要小得多,延时也小得多。对于其他较小的树,可以通过减少压缩单元的数目来实现。图4为本MAC单元中最大的Wallace tree 结构(其中a22为被加数的相应位)。
最终加法器
在Wallace tree阵列中,Wallace tree的每一列都产生一个初步的进位项和一个初步的加法结果,最后必须使用一个快速加法器将所有的进位项和加法结果加起来。为了获得较高性能,一般采用先行进位加法器(CLA),它可以同时产生所有的进位项,因而可以获得极高的速度,在最坏情况下的延迟正比于n。但是随着位数的增加,进位项变得越来越复杂,相应地消耗的面积越来越大,同时速度也无法得到保证。研究表明,CLA的最佳位数是4位,这时可以在速度与面积之间取得最优的折衷。在本设计中,加数共有48位,因此将它分成12块,每块4位,块与块之间通过块间进位串联,每一块的进位只影响本块中的位,不影响更高块的位。图5为最终加法器的实现。
饱和检测和饱和值的产生
在本设计中,通过下式来检测结果是否发生溢出:
其中(Xn-1)为XY的符号。在发生溢出的情况下,通过48位2选1的MUX将饱和修正值输出。修正的饱和值可以由下面的公式计算:
V=
(a2n-1为被加数的符号位)
结语
考察整个MAC单元的实现,优化后的设计将被加数作为部分积的一部分加入到Wallace tree阵列中,从而在关键路径上减少了一级串联的先行进位加法器;采用特殊的饱和检测逻辑,可以不用再等待和的产生,使得饱和检测操作可以和乘加操作并行进行,将饱和检测逻辑的延时排除在关键路径延时之外。与优化以前的设计实现相比,MAC单元的速度有了很大提高。优化以后的设计实现,其面积和时延都集中消耗在部分积产生、Wallace tree阵列、最终加法器和2选1的MUX这四部分上。
表2是优化前后的面积和时延的比较,从表中可以看出不论是在速度还是在面积方面,优化后比优化前都有了很大的改进。
参考文献
1 Michael J.Schulte, Pablo I. Balzola, Ahmet Akkas,and Robert W.Brocato. Inter Multiplication with Overflow Detection or Saturation. IEEE TRANSACTIONS ON COMPUTERS,VOL 49,NO.7,JULY 2000
2 Fayez Elguibaly. ast Parallel Multiplier-Accumulator Using the Modified Booth algorithm. IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS-II: ANALOG AND DIGITAL SIGNAL PROCESSIONG, VOL.47,NO.9, SEPTEMBER 2000
-
ARM公司推出面向音频处理的高性能低功耗数据引擎2011-03-12 0
-
BF60x系列PVP模块功能2018-08-28 0
-
什么是DSP,DSP处理器有什么特点?2020-09-04 0
-
机器学习处理器单元支持浮点的乘加运算2020-11-26 0
-
基于51单片机的4乘4计算器有哪些功能2021-07-15 0
-
并行可配置ECC专用指令协处理器2009-03-20 511
-
带有集成传感器的轴承单元2009-07-06 428
-
带有饱和处理功能的并行乘加单元设计2006-03-24 840
-
SoC集成中的处理单元性能评估及功能划分2017-01-12 391
-
并行处理在计算全息中的应用_简献忠2017-03-19 527
-
利用NI LabVIEW实现真正的并行化处理和并行化测量2017-11-16 8979
-
基于GPU的数字图像并行处理研究2017-12-01 480
-
基于FPGA的VLIW微处理器基本功能实现设计2020-01-31 954
全部0条评论

快来发表一下你的评论吧 !
