

为什么将AI注入到IT运营中比数据本身更多的是数据
电子说
描述
我与之交谈的几乎每个CIO都大胆地宣称他们的企业是“数据驱动的企业”。但是,毕马威会计师事务所(KPMG)最近进行的 全球CEO前景 调查却截然不同:全球67%的CEO(美国的这一数字跃升至78%)表明,他们忽略了由CIO /他们提供的数据驱动的分析和预测模型IT团队,因为这与他们自己的经验相矛盾;他们根据自己的直觉做出了重大的企业决策。
忽略了数据驱动的见解而遵循直觉的CEO
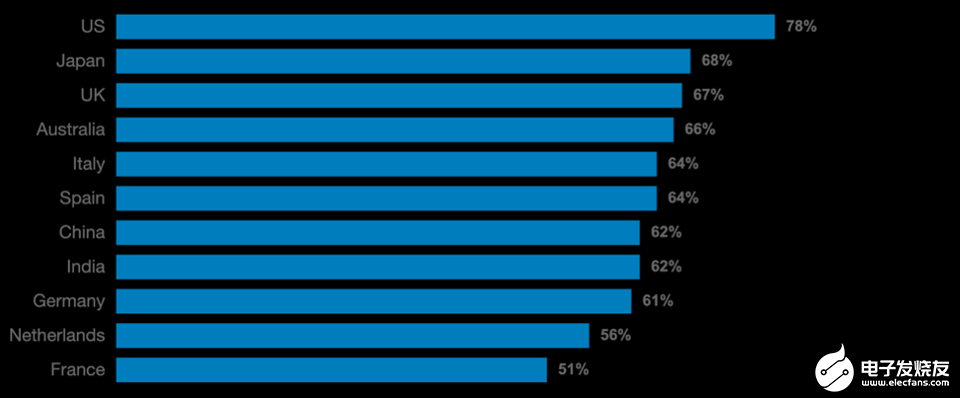
虽然结果有些令人震惊,但可以很容易地解释它。首先,尽管企业生产的数据量足够多,但是数据仍然在业务单元,域,平台和实现(例如云与私有数据中心)之间非常分散。根据Forrester的说法,多达73%的公司数据未用于分析和见解。难怪首席执行官仅使用总数据的27%生成的模型就获得了可怕的结果!其次,大多数当前的预测模型仅使用历史数据,而不使用流(实时)数据。这两个重要因素导致预测的准确性不高。首席执行官如果不信任模型,就无法做出决策,因为他们业务的成败取决于他们做出的决策。
更多数据可以带来更好的预测
尽管是IT运营使其他企业AI计划保持平稳运行,但实施AI以改善其自身的运营速度却很慢。原因之一是上述数据零散。当向AI / ML模型提供部分数据时,您只会获得企业的部分视图。另一个主要原因是因为当前大多数AI / ML实施都是为了创新,并且通常由BU资助。传统上,企业将IT视为成本中心,因此他们不愿意花钱来使用AI来改善运营。但是,随着大量的数据,以及当前的大流行病产生了更多的未连接的远程数据,这种感觉在开始淹没Ops团队时发生了变化。IT运营团队正在达到一个临界点,要处理的数据过多,这是AI的理想方案。这是AI和ML的最佳选择。人工智能在大量数据上蓬勃发展。实际上,向AI算法馈送的数据越多,模型就越好。
传统上,IT运营团队多年来一直监视IT基础结构监视(ITIM)和网络性能监视与诊断(NPMD)层。在过去的十年中,应用程序性能管理(APM)帮助提高了每个应用程序的可见性。但是,即使所有这些系统都表明它们正常工作,客户仍会根据位置,连接类型(移动/互联网),所使用的缓存/ CDN提供程序的类型等而遇到问题。现代应用程序及其组件的复杂性加载到客户视图中会使其变得非常复杂。数字体验监视(DEM)的概念已获得可见性,可以专门监视,分析和优化客户体验。但是,它们更像是监视工具,而不是诊断工具。
AIOps(IT运营中的人工智能)解决方案可以帮助解决此问题。一个好的AIOps解决方案应该能够从多个来源获取数据,消除噪声,关联事件序列并基于历史数据和实时数据的组合产生可行的见解。
数据采集
可以说,这是最重要的一步。不仅需要将历史数据馈送给AI进行模型创建,而且还需要将实时数据馈给AI进行推理和更新模型。仅像过去那样收集日志或SNMP并不能提供企业的全面情况。收集尽可能多的信息,包括事件,日志,时间序列数据,应用程序数据,性能数据,利用率数据等。新的基于事件的范式转移到发布/订阅或基于事件的消息传递。尽管这些消息非常重要,但它们对于收集实时数据以提供企业的完整视图并做出准确的预测绝对至关重要。大多数基于云的系统,无论是基于容器的还是基于虚拟机的,都通过API提供大量信息。
收集结构化,半结构化和非结构化数据。尽管现有的BI和分析系统在处理非结构化数据时遇到困难,但AI还是喜欢它。它可以解析几乎所有内容,包括音频,视频,文本文件,图像,配置文件,文档,PDF文件等。
最后,大多数团队忘记将配置记录,变更管理系统,CMBD等作为等式的一部分。这对于每天有时会推动多个发布周期的敏捷团队尤其重要。除非IT运营团队意识到最近的变化,否则他们将浪费大量时间试图找出问题的根本原因。
数据质量和数据摄取
AI存在数据质量问题。创建AI / ML模型时,“垃圾填埋,垃圾填埋”是非常正确的。您的算法有多好或数据科学家有多好都无关紧要。如果您没有提供足够的质量数据,那么您将一无所获。当企业收集大量数据时,它仍然是不完整,不正确和/或不一致的。您还需要收集相邻和相关的数据。您可能会认为它们无关紧要,但是对于AI使用看似无关的数据所能找到的东西,您会感到惊讶。一个例子是,当NASA卫星破裂时,IBM的AI工程师和NASA科学家找到了一种方法,可以利用太阳光以98%的准确度来计算紫外线强度。我最近写了一篇关于此的文章,可以在这里看到。
如果您与数据科学家交谈,他们会告诉您他们花了多少时间准备数据。他们多达80%的时间用于准备数据,而不是分析数据或创建和微调模型。
数据分类和标签
数据需要正确分类,分类和标记,以便AI / ML从中学习。对于监督学习模型尤其如此。在训练,验证和调整模型之前,这是重要的一步。标签的准确性和质量是最重要的两件事。准确性衡量的是标签与真实情况之间的接近程度,或与您的企业事实和/或实际条件匹配的程度。质量与用于模型的整个数据集的标注准确性有关。当您结合使用自动,外包和内部标签工作时,尤其如此。所有组都会在整个数据集中一致地标记吗?
数据清理
如果使用偏差数据训练AI模型,则无疑会产生偏差模型。我写了一篇有关如何避免这种情况并使您的数据失偏的文章。原始数据可能包含隐性偏见信息,例如种族,性别,出身,政治,社会或其他意识形态偏见。消除它们的唯一方法是分析不平等并在创建模型之前对其进行修复。如果不从数据中消除歧视性做法,该模型将倾向于产生有偏见的结果。
仅当数据来自经验证,权威,经过验证和可靠的来源时,才应包括在内。来自不可靠来源的数据应该完全消除,或者在输入模型时应给予较低的置信度。另外,通过控制分类精度,可以以最小的增量成本来大大减少辨别力。这种数据预处理优化应集中在控制区分,限制数据集中的失真和保留实用程序上。
资料储存库
考虑到数据的数量,速度和种类,用于数据存储和数据管理的传统现场解决方案不适用于数字本机解决方案。许多公司已采用数据湖解决方案来解决此问题。尽管单个集中的数据源可以提供帮助,但需要对其进行适当的安全保护,管理和定期更新。它应该能够无缝处理结构化和非结构化数据。
结论
人工智能需要大量数据。正如我最喜欢的《短路》中的角色Johnny V(基于AI的机器人)说:“我需要更多的输入……”。如果您的高管要基于此做出重大的企业决策,请确保为AI提供正确数量和质量的数据。如果没有,他们将忽略您的模型输出/建议并做出自己的决定,从而最大程度地降低您的价值,并最终使您获得数字化和改善业务所需的资金。
-
NanoEdge AI的技术原理、应用场景及优势2024-03-12 0
-
labview将数据按列写入到Excel中?2016-01-03 0
-
LabVIEW将STM32采集到的阵列数据绘制分布云图,应用队列处理数据2018-04-22 0
-
tps61221效率比数据手册中给出的要低2019-04-26 0
-
请问画元件封装时候焊盘的宽度要比数据手册上规定的要大一点吗?2019-05-20 0
-
硬件帮助将AI移动到边缘2019-05-29 0
-
如何在模拟时将数据注入pin2020-04-29 0
-
如何在fpga本身生成数据?2020-07-20 0
-
如何加速电信领域AI开发?2021-02-25 0
-
运营商的数据资源2021-08-31 0
-
如何去提高数据中心的运营效率呢2021-09-09 0
-
防止数据被读取或注入系统的方法2022-02-11 0
-
AI算法中比较常用的模型都有什么?2022-08-27 0
-
探索运营商大数据AI能力层的构建方案2019-02-26 5685
-
AD9467:16位,200 MSPS/250 MSPS类比数字Converator数据Sheet2021-04-18 517
全部0条评论

快来发表一下你的评论吧 !
