

基于FPGA器件实现微波接力机中的FFT模块设计
可编程逻辑
描述
1、引言
对于地面上的远距离微波通信,当通信距离超过一定范围时,电磁波传播会受到地面的阻挡,随着通信距离的增加通信信号则会衰减。为了延长通信距离和提高通信质量,需要在通信二地之间设立若干微波中继设备(例如微波接力机),进行电磁波转接并对信号进行逐段接收和放大后再发送给下一段。在微波接力通信中,通常采用扩频方式提高系统的抗干扰能力。但是,扩频系统过宽的频带带宽很容易在通信设备密集的地方受到其他设备的干扰(窄带干扰)。所以在微波接力机工作过程中,需要对接收信号中的窄带干扰信号进行快速识别并利用相应的自适应陷波等技术对窄带干扰进行抑制。由于在频域上窄带干扰的功率谱呈现尖峰状,而扩频信号大致呈现平坦特性且并容易识别。所以要在微波接力机中设计FFT模块用于计算信号的功率谱。
对实现FFT的工程,目前通用的方法是采用DSP、FFT处理电路及FPGA。用DSP实现FFT的处理速度较慢,不能满足某些高速信号实时处理的要求;专用的FFT处理器件虽然速度较快,但是价格相对昂贵且外围电路相对复杂;采用新一代的FP-GA来实现FFT兼有二者的优点。FPGA资源丰富、易于借助并行流水的特点来实现FFT,不但性能稳定、经济性好,而且可以大大缩短计算的耗时。以Altera公司的Stratix系列FPGA为例,它具有多达79 040个逻辑单元、7 MB的嵌入式存储器、优化的数字信号处理器和高性能的I/O能力,非常方便以全并行流水方式进行FFT处理。
选用Stratix系列中的EPlS25型FPGA来实现FFT,在系统主频大于52 MHz的环境下稳定工作后,完成1次256点的FFT所需要的时间小于5μs,完成1次1024点的FFT所需时间小于20μs,完全满足实时处理的要求。
2、模块的设计与实现
2.1 FFT算法选择
自从1965年J.W.Tuky和T.W.Coody在《计算机数学》上发表了著名的《机器计算傅立叶级数的一种算法》论文后,经过几十年来的不断改进,形成了很多FFT的高效算法。这些算法基本上分为二大类:时域抽取法FFT(DIT-FFT)和频域抽取法FFT(DIF-FFT)。时域抽取法是把变换模块的输入数据在时域上按一定的倒序规则打乱,经过变换后,输出的FFT频域信号是顺序排列的。而频域抽取法是把变换模块的输入数据在时域上按顺序输入,经过变换后,输出的FFT频域信号按照倒序列规则输出。根据运算基的不同,又可以分为基2、基4、基8及混合基算法等。
在该变换模块的处理过程中,可以在预加窗单元方便地完成倒序操作,而且在全并行流水方式处理的过程中,采用时域抽取可以充分利用原址存储,节省内存。所以,在设计中选择简单实用的时域抽取基2FFT算法。
2.2 FFT模块与外部电路的接口
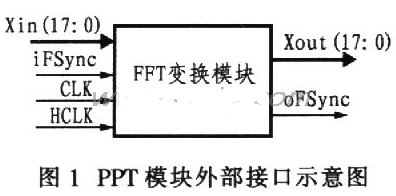
FFT模块与外部电路的接口如图1所示。图中,输入信号Xin为复数零中频信号,数据宽度为18bit,编码格式为二进制补码。Xout是复数变换输出信号,数据宽度为18 bit,编码格式也是二进制补码。CLK和HCLK分别是系统的主时钟和2倍时钟。HCLK主要用于数据的输入、输出。当CLK为‘1’时,由Xin在HCLK的上升沿输入实部数据并在Xout输出变换数据的实部;当CLK为‘O’时,由Xin在HCLK的上升沿输入虚部数据并在Xout输出变换数据的虚部。iFSyne为变换输入帧同步控制信号,oFSync为变换输出帧同步控制信号。2个信号为‘1’时分别表示模块输入/输出变换帧的第1个数据开始输入/输出。
2.3 全并行流水方式的实现
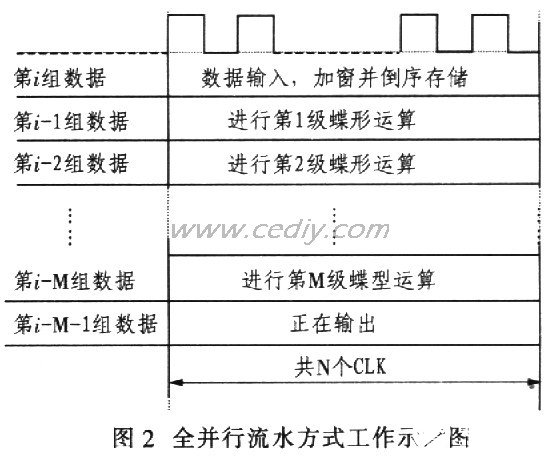
在FFT工作方式的设计上,充分利用FPGA内嵌乘法器和存储器资源丰富的特点.采用全并行的流水工作方式。如图2所示,图中N为进行FFT运算的点数,M=log2N。以N=256,M=8为例,当系统稳定工作之后,在256个时钟之内,同时有lO组数据在做不同的运算。当第1组数据输入的时候,第10组数据正在输出,而中间的8组数据正在进行各级蝶形运算。因此,当模块进入稳定工作状态后,每隔256个时钟就有一组数据完成256点的FFT,从输出RAM中输出。
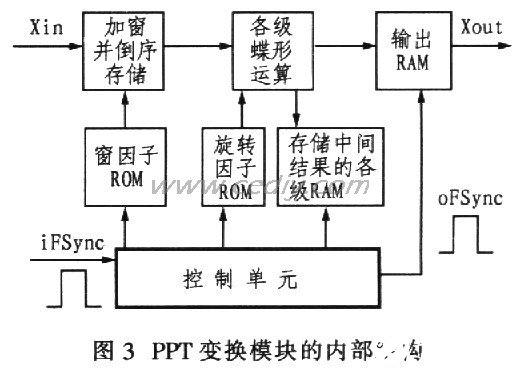
2.4 FFT变换模块的内部设计
FFT内部变换模块的设计如图3所示。下面以N=256点的FFT为例分别予以说明。
2.4.1 加窗并倒序存储单元
为了减少时域截断造成的频谱泄漏误差,在进行FFT变换前应对模块输入的数据进行加窗处理。考虑到本模块主要用来分析叠加有窄带干扰的扩频信号,它要求精确给出每个窄带干扰的中心频率及其干扰强度的相对大小,所以,这里选用带外衰减为80 dB的Chebyshev窗以获取良好的频谱效果。经过加窗之后的数据按照倒序的规则存储在RAM中,等待进入蝶形运算单元进行运算。
2.4.2 控制单元
控制单元是整个FFT变换模块的核心。它主要负责以下二方面的工作。
(1)提供各个模块的运算使能
当检测到输入口的iFSync信号为高电平后,立即启动“加窗并倒序存储单元”和“窗因子ROM”单元进行数据输入、加窗、倒序存储处理。在256个时钟之后,启动“各级蝶形运算”单元,并控制地址产生单元产生当前需要的各类地址。中间各级蝶形运算的使能由上l级蝶算单元产生。在第8级运算结束时,提供数据输出的标志oFSync,并控制输出RAM同步输出数据。
(2)产生各级运算过程中所需的地址
倒序地址:用模为N的同步计数器的输出来实现,把当前计数器输出的高位与低位的对应位进行全部对调即可得到当前数据的倒序地址。
各级运算的地址:把RAM取数地址和ROM取数地址对应起来。原则是先把1个旋转因子所对应的所有数据计算完毕再转到下1个旋转因子所对应的数据上。这样的话,可以在产生ROM地址的同时产生所有RAM取数的地址。把二者的地址建立关联之后,可以使RAM数据和ROM数据严格对应起来。
2.4.3 RAM模块
在256点的FFT中,要进行8级蝶算,对全并行的工作方式而言需要8个不同的RAM来存储各级的中间结果。其中,第8级的RAM可以作为输出RAM。再加上前面加窗和倒序的1个RAM,整个系统共需要9个RAM。对于256点的复数,把实部和虚部分开共需要512个存储单元。在某一级的蝶算中,由于信号及运算的延迟,不可能就在256个时钟之内完成本级运算,而下一组的数据在256个时钟之后就要进行本级运算并将结果存储在该RAM中,这样就有可能造成数据还没有被完全读取就被新数据覆盖的冲突。为了确保在全并行工作方式中实现数据的准确存取,可以把9个RAM都设置成1024×18 bit的存储格式,即:把每个RAM分为二部分,地址为0~511的为前半部分,地址为512~l 023的为后半部分,用一个MSB的信号作为地址最高位来控制前后二部分存储器。当第1组数据进行本级运算时,其结果保存在RAM的前半部分;256个时钟之后,对MSB求反,并以此控制把第I+1组数据进行本级运算的结果写入RAM的后半部分,此时对第1组数据的读取在前半部分进行,互不冲突。Altera的FPGA器件里有丰富的RAM资源,采用双端口RAM可以很方便地实现上述操作。
2.4.4 ROM模块
整个模块共需3个ROM,一个用来存储Chebyshev窗因子,另外二个分别用来存储旋转因子的实部和虚部。事先在MATLAB中计算出这些因子,并将它们按照*.mif文件格式输出。在QuartusⅡ软件中,例化3个ROM,并把由MATLAB产生的*.mif文件写入各自ROM的初始化文件中,完成对ROM的初始化工作。
2.4.5 蝶形运算单元
(1)基本蝶形运算单元。把复数运算分解为实数运算之后,每个基本的蝶形运算单元都可由4个乘法器、1个加法器和1个减法器构成。其中,乘法器是决定系统运算速度的关键因素。对256点FFT在全并行的工作方式下,最多要求在同一时钟并行完成33个18x18 bit的乘法运算。而EPlS25系列FPGA有非常丰富的乘法器资源,仅DSP就可以并行完成40个18x18 bit的乘法运算,完全满足系统的要求。
(2)可化简的蝶形运算单元。在对各级蝶形进行研究的基础上发现,第1级和第2级的蝶形经过化简完全可以不用进行乘法操作。
第1级只有1个旋转因子won,其实部为1、虚部为O,代入基本蝶形运算单元化简之后可得:
mx1=xl+x2;my1=yl+y2
mx2=x1-x2;my2=y1-y2
其中:x1、x2为输入数据实部,y1、y2为输入数据虚部,mx1、mx2为变换之后的数据实部,my1、my2为变换之后的数据虚部。
第2级有2个旋转因子,won和w64n,对won可以沿用第一级的简化方法。
对于w64n,其实部为0、虚部为-l,代入基本蝶算单元化简之后可得:mx1=x1+y2;my1=y1+x2;mx2=x1-xz;my2=y1+x2这样,总共8级的蝶形运算有2级可以不用乘法器和存储旋转因子的ROM,节省了25%的乘法器和ROM资源。
2.5 误差的分析与控制
对FPGA而言,采用浮点运算带来的硬件开销太大。而如果采用文献[3]所提出的块浮点防溢出方案,在每一级蝶形运算结束之后,都需要找出该级计算结果中的最大值来判断溢出的状态,并以此确定进行下一级运算时每个数据需要移位的位数。这对全并行的工作方式而言,意味着每一级数据都会带来更大的延迟,影响整个运算的速度。而对定点运算而言,虽然存在有限字长效应的影响,但是,只要对数据进行适当的移位处理就可以防止溢出;在数据舍弃时,进行类似4舍5入的运算就可以有效的控制误差。在综合考虑之后,系统采用定点运算方案。在定点运算中,误差主要体现在以下两方面:
(1)乘法截断误差。2个18位的数据相乘得到36位的积,把该积舍入为18位就会产生误差。由于来自零中频的18位数据实际表征的是模值不大于‘1’的复小数,所以相乘不会产生溢出。去掉次高位多余的符号位并截去后17位。当被截去的各位是‘1’的时候,误差最大;被截去的各位为‘O’时,没有误差。对被截去的部分作类似4舍5入的处理,第20位为‘1’则向上进位,为‘O’则直接舍去,可以有效减小误差。
(2)加减法溢出误差。2个18位的数据相加减得到19位的结果,在进行下一级运算之前,必须舍去l位,对舍弃的这l位也进行上述的4舍5入运算。2个小数的加减运算而言,把结果全部右移1位就可以防止溢出。
3、波形仿真与性能分析
波形仿真选用的输入信号为
x(n)=Xxexp[j×(03+2x127xnxπ)/256]
式中。X根据测试的需要分别取18 bit信号的最大值和达到80 dB信噪比所需的最小值13,n的取值范围为0:255。设计工具选用VHDL93版硬件描述语言,在QuartusⅡ4.1平台上进行逻辑综合和时序分析,把仿真结果保存为*.tbl文件格式。在MATLAB中,读取*.tbl文件,并与MATLAB的计算结果进行比较。由于8级运算都作了右移1位的处理,所以实际结果比用MATLAB的计算结果缩小256倍。把MATLAB的计算结果缩小256倍与0uartusⅡ4.1的计算结果比较,如图4所示。图中,左上图为原始序列,右上图为用MATLAB计算的结果,右下图为用FPGA计算的实际结果。在左下图中,把二个结果进行局部放大,MATLAB的计算结果用实线表示,Quartus4.1的仿真结果用“+”表示。可以看出二组结果的吻合性非常好,验证了程序的正确性。仿真采用60 MHz系统主频,在系统进入稳定状态之后(经过38.34μs),每完成1次256点FFT所用时间为4.26μs。对EPlS25器件资源占用情况为:逻辑单元使用15%,内部存储器使用18%,专用DSP使用62.5%。虽然专用DSP块使用较多,但是逻辑单元使用得很少,可以用逻辑单元来构成18x18的乘法器和专用DSP一起完成更多的并行乘法运算。这说明系统还具有很好的可扩展性,要完成更多点数的FFT,只需增加相应蝶形运算的级数即可。
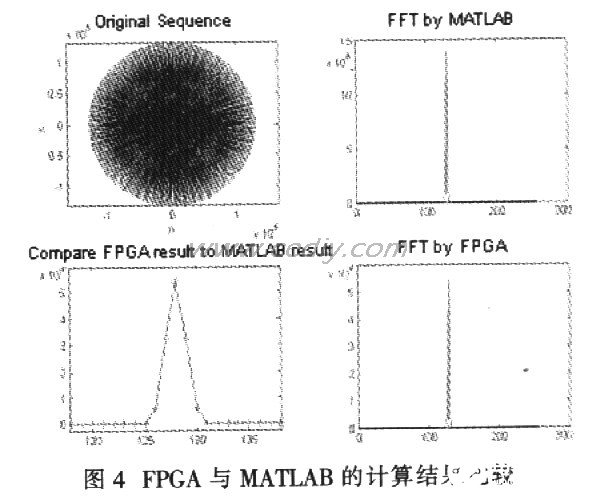
从结果可以看出,由于运算中采用有效措施防止误差和溢出,在最大数据运算时没有溢出,而且最终运算结果的误差小于10-9。在用达到80 dB信噪比所需最小数据进行运算时,也有很好的分辨率。
4、结束语
本文讨论了微波接力机中FFT模块的设计与实现过程。全部电路设计已经过功能仿真、逻辑综合、时延分析并成功下载到FPGA中投入实践应用。实践应用表明用Stratix系列FPGA实现FFT的速度快、稳定性高、易于扩展。在微波接力通信,特别是在接力机对窄带干扰快速识别的应用中有很大的优越性。
责任编辑:gt
-
FFT算法的FPGA实现2010-05-28 0
-
FPGA实现高速FFT处理器的设计2012-08-12 0
-
FFT 算法的一种 FPGA 实现2017-11-21 0
-
基于FPGA的超高速FFT硬件实现2009-04-26 514
-
利用CORDIC 算法在FPGA 中实现可参数化的FFT2009-08-24 515
-
基于Stratix系列FPGA 的FFT模块设计与实现2009-11-24 467
-
利用CORDIC算法在FPGA中实现可参数化的FFT2010-08-09 748
-
一种块递推实时FFT算法模块设计与实现2010-09-15 425
-
用FPGA实现FFT算法2008-10-30 1441
-
基于Xilinx_FPGA_IP核的FFT算法的设计与实现2016-05-24 747
-
如何使用FPGA实现全并行结构FFT2021-03-31 898
-
基于新型FPGA的FFT设计与实现2021-06-17 742
-
用FPGA实现FFT算法的方法2022-04-12 4639
-
采用FPGA实现FFT算法示例2023-05-11 1931
全部0条评论

快来发表一下你的评论吧 !
