

page struct的三种存放方式
描述
随着硬件能力的提升,系统内存容量变得越来越大。尤其是在服务器上,过T级别的内存容量也已经不罕见了。
如此海量内存给内核带来了很多挑战,其中之一就是page struct存放在哪里。
page struct的三种存放方式
在内核中,我们将物理内存按照页大小进行管理。这样每个页就对应一个page struct作为这个页的管理数据结构。
随着内存容量的增加,相对应的page struct也就增加。而这部分内存和其他的内存略有不同,因为这部分内存不能给到页分配器。也就是必须在系统能够正常运行起来之前就分配好。
在内核中我们可以看到,为了应对这样的变化进化出了几个不同的版本。有幸的是,这部分内容我们现在还能在代码中直接看到,因为这个实现是通过内核配置来区分的。我们通过查找_pfn_to_page的定义就能发现一下几种memory model:
CONFIG_FLATMEM
CONFIG_SPARSEMEM
CONFIGSPARSEMEMVMEMMAP
接下来让小编给各位看官一一道来。
1) FLATMEM
在这种情况下,宏_pfn_to_page的定义是:
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
而这个mem_map的定义是
struct page *mem_map;
所以在这种情况下,page struct就是一个大数组,所有的人都按照自己的物理地址有序得挨着。
2) SPARSEMEM
虽然第一种方式非常简单直观,但是有几个非常大的缺点:
内存如果有空洞,那么中间可能会有巨大的page struct空间浪费
所有的page struct内存都在一个NUMA节点上,会耗尽某一个节点内存,甚至是分配失败
且会产生夸NUMA访问导致性能下降
所以第二种方式就是将内存按照一定粒度,如128M,划分了section,每个section中有个成员指定了对应的page struct的存储空间。
这样就解决了上述的几个问题:
如果有空洞,那么对应的 page struct就不会占用空间
每个section对应的page struct是属于本地NUMA的
怎么样,是不是觉得很完美。这一部分具体的实现可以可以看函数sparse_init()函数。
有了这个基础知识,我们再来看这种情况下_pfn_to_page的定义:
#define __pfn_to_page(pfn) ({ unsigned long __pfn = (pfn); struct mem_section *__sec = __pfn_to_section(__pfn); __section_mem_map_addr(__sec) + __pfn; })
就是先找到pfn对应的section,然后在section中保存的地址上翻译出对应pfn的page struct。
既然讲到了这里,我们就要对sparsemem中重要的组成部分mem_section多说两句。
先来一张mem_section的整体图解:
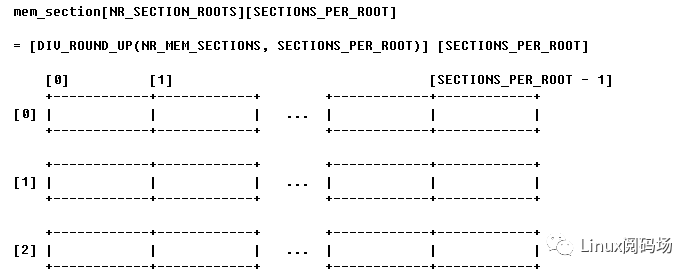
这是一个 NRSECTIONROOTS x SECTIONSPERROOT的二维数组。其中每一个成员就代表了我们刚才提到的128M内存。
当然最开始它不是这个样子的。
其实最开始这个数组是一个静态数组。很明显这么做带来的问题是这个数组定义太大太小都不合适。所以后来引进了CONFIGSPARSEMEMEXTREME编译选项,当设置为y时,这个数组就变成了动态的。
如果上面这个算作是空间上的限制的话,那么接下来就是一个时间上的限制了。
在系统初始化时,每个mem_section都要和相应的内存空间关联。在老版本上,这个步骤通过对整个数组接待完成。原来的版本上问题不大,因为整个数组的大小还没有很大。但随着内存容量的增加,这个数值就变得对系统有影响了。如果系统上确实有这么多内存,那么确实需要初始化也就忍了。但是在内存较小的系统上,哪怕没有这么多内存,还是要挨个初始化,那就浪费了太多的时间。
commit c4e1be9ec1130fff4d691cdc0e0f9d666009f9aeAuthor: Dave Hansen
Dave在这个提交中增加了对系统最大存在内存的跟踪,来减少不必要的初始化时间。
瞧,内核代码一开始其实也没有这么高大上不是。
3) SPARSEMEM_VMEMMAP
最后要讲的,也是当前x86系统默认配置的内存模型是SPARSEMEM_VMEMMAP。那为什么要引入这么一个新的模型呢?那自然是sparsemem依然有不足。
细心的朋友可能已经注意到了,前两种内存模型在做pfn到page struct转换是有着一些些的差异。为了看得清,我们把这两个定义再拿过来对比一下:
先看看FLATMEM时的定义:
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
再来看看使用SPASEMEM后的定义:
#define __pfn_to_page(pfn) ({ unsigned long __pfn = (pfn); struct mem_section *__sec = __pfn_to_section(__pfn); __section_mem_map_addr(__sec) + __pfn; })
更改后,需要先找到section,然后再从section->memmap的内容中换算出page的地址。
不仅计算的内容多了,更重要的是还有一次访问内存的操作
可以想象,访问内存和单纯计算之间的速度差异那是巨大的差距。
既然产生了这样的问题,那有没有办法解决呢?其实说来简单,内核开发者利用了我们常见的一个内存单元来解决这个问题。
页表
是不是很简单粗暴?如果我们能够通过某种方式将page struct线性映射到页表,这样我们不就能又通过简单的计算来换算物理地址和page struct了么?
内核开发者就是这么做的,我们先来看一眼最后那简洁的代码:
#define __pfn_to_page(pfn) (vmemmap + (pfn))
经过内核开发这的努力,物理地址到page struct的转换又变成如此的简洁。不需要访问内存,所以速度的问题得到了解决。
但是天下没有免费的午餐,世界哪有这么美好,鱼和熊掌可以兼得的情况或许只有在梦境之中。为了达到如此简洁的转化,我们是要付出代价的。为了实现速度上的提升,我们付出了空间的代价。
至此引出了计算机界一个经典的话题:
时间和空间的转换
话不多说,也不矫情了,我们来看看内核中实现的流程。
既然是利用了页表进行转换,那么自然是要构建页表在做这样的映射。这个步骤主要由函数vmemmap_populate()来完成,其中还区分了有没有大页的情况。我们以普通页的映射为例,看看这个实现。
int __meminit vmemmap_populate_basepages(unsigned long start, unsigned long end, int node){ unsigned long addr = start; pgd_t *pgd; p4d_t *p4d; pud_t *pud; pmd_t *pmd; pte_t *pte; for (; addr < end; addr += PAGE_SIZE) { pgd = vmemmap_pgd_populate(addr, node); if (!pgd) return -ENOMEM; p4d = vmemmap_p4d_populate(pgd, addr, node); if (!p4d) return -ENOMEM; pud = vmemmap_pud_populate(p4d, addr, node); if (!pud) return -ENOMEM; pmd = vmemmap_pmd_populate(pud, addr, node); if (!pmd) return -ENOMEM; pte = vmemmap_pte_populate(pmd, addr, node); if (!pte) return -ENOMEM; vmemmap_verify(pte, node, addr, addr + PAGE_SIZE); } return 0;}
内核代码的优美之处就在于,你可能不一定看懂了所有细节,但是从优美的结构上能猜到究竟做了些什么。上面这段代码的工作就是对每一个页,按照层级去填充页表内容。其中具体的细节就不在这里展开了,相信有兴趣的同学会自行去探索。
那这么做的代价究竟是多少呢?
以x86为例,每个section是128M,那么每个section的page struct正好是2M,也就是一个大页。
(128M / 4K) * 64 = (128 * (1 < 20) / (1 < 12)) * 64 = 2M
假如使用大页做页表映射,那么每64G才用掉一个4K页表做映射。
128M * 512 = 64G
所以在使用大页映射的情况下,这个损耗的级别在百万分之一。还是能够容忍的。
好了,我们终于沿着内核发展的历史重走了一遍安放page struct之路。相信大家在这一路上领略了代码演进的乐趣,也会对以后自己代码的设计有了更深的思考。
-
ARQ方式的三种形式2011-07-15 0
-
三种复位方式比较2012-08-16 0
-
FCC三种认证方式有什么区别2015-10-22 0
-
步进电机的三种驱动方式2016-01-12 0
-
请问stm32启动的三种方式是什么意思?2019-07-17 0
-
伺服电机的三种控制方式详解2021-01-21 0
-
伺服电机的三种控制方式怎么选2021-01-29 0
-
常见的三种无线接入方式是什么?2021-05-26 0
-
STM32的三种开发方式2021-08-05 0
-
STM32的三种启动方式2021-08-11 0
-
伺服的三种控制方式具体根据什么来选择的2021-10-11 0
-
STM32的三种开发方式分享2021-12-01 0
-
STM32三种启动方式是什么2021-12-15 0
-
如何使用三种方式进行文件的创建2021-12-15 0
-
STM32三种BOOT启动方式的设置与应用2022-01-18 0
全部0条评论

快来发表一下你的评论吧 !
