

干货:基于Redis配置Celery任务(附源码)
电子说
描述
作为一个分布式异步计算框架,Celery虽然常用于Web框架中,但也可以单独使用。 虽然常规搭配的消息队列是RabbitMQ,但是由于某些情况下系统已经包含了Redis,那就可以复用。
以下撇开Web框架,介绍基于Redis配置Celery任务的方法。
pip install celery[redis]
项目结构

其中,main.py是触发Task的业务代码。当然,文件名可以随意改。celery.py是Celery的app定义的位置,tasks.py是Task定义的位置,文件名不建议修改。
配置Celery
在celery.py中写入如下代码:
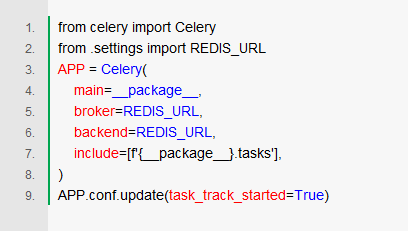
其中,REDIS_URL从同一的配置settings.py中引入, 形式大概是redis://localhost:6379/0。这里既用Redis来当broker,又用来当backend。即,既当消息队列,又当结果反馈的数据库(默认仅保存1天)。
在include=,需要填一个下游worker的包名列表。这里选择了同一个包的tasks.py文件。
额外设置的task_track_started,是命令Worker反馈STARTED状态。默认情况下,是无法知道任务什么时候开始执行的。
编写任务并调用
在tasks.py文件中,添加异步任务的实现。
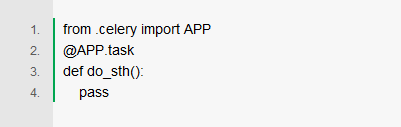
在需要发起任务的地方,用.apply_async可以触发异步调用。即,实际只是向消息队列发送消息,真正的执行操作在远程。
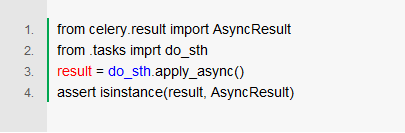
运行Worker:
celery -A your_project worker
运行原理
一次Task从触发到完成,序列图如下:
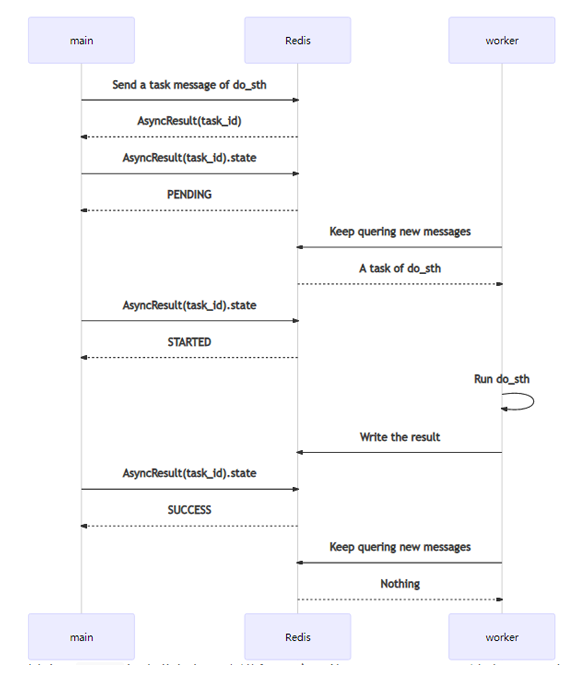
其中,main代表业务代码主进程。它可能是Django、Flask这类Web服务,也可能是一个其它类型的进程。worker就是指Celery的Worker。
main发送消息后,会得到一个AsyncResult,其中包含task_id。仅通过task_id,也可以自己构造一个AsyncResult,查询相关信息。其中,代表运行过程的,主要是state。
worker会持续保持对Redis(或其它消息队列,如RabbitMQ)的关注,查询新的消息。如果获得新消息,将其消费后,开始运行do_sth。运行完成会把返回值对应的结果,以及一些运行信息,回写到Redis(或其它backend,如Django数据库等)上。在系统的任何地方,通过对应的AsyncResult(task_id)就可以查询到结果。
Celery Task的状态
以下是状态图:
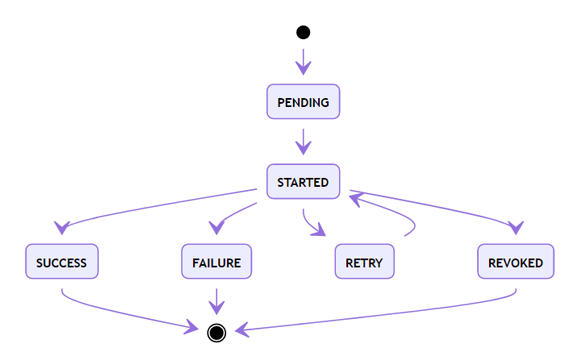
其中,除SUCCESS外,还有失败(FAILURE)、取消(REVOKED)两个结束状态。而RETRY则是在设置了重试机制后,进入的临时等待状态。
另外,如果保存在Redis的结果信息被清理(默认仅保存1天),那么任务状态又会变成PENDING。这在设计上是个巨大的问题,使用时要做对应容错。
常见控制操作

有时,在业务主进程中需要等待异步运行的结果,这时需要使用wait。如果要取消一个排队中、或已执行的任务,则可以使用revoke。即使任务已经执行完成,也可以使用revoke,但不会有任何变化。如果需要提前删除任务记录,可以使用forget。
责编AJX
-
redis集群环境安装及配置2019-03-08 0
-
基于linux的安装和配置redis2019-04-11 0
-
阿里云ECS的redis配置步骤2019-10-28 0
-
Mac上redis怎么安装配置?2020-05-01 0
-
启动Redis的三种方法2020-06-08 0
-
走近源码之Redis如何执行命令的2020-06-09 0
-
【昉·星光 2 高性能RISC-V单板计算机体验】Redis源码编译和性能测试以及与树莓派4B对比2023-12-10 0
-
【爱芯派 Pro 开发板试用体验】Redis源码编译和基准测试2023-12-10 0
-
干货:在Windows上安装Maven及配置2020-06-20 2554
-
单片机多任务事件驱动C源码2021-11-29 435
-
redis.conf 7.0配置和原理全解2023-06-08 349
-
Celery Beat 的周期调度机制及实现原理2023-10-31 306
-
基于Django的Celery异步任务和定时任务的实战教程2023-11-02 310
-
redis连接数配置多少合适2023-12-04 466
-
云容器redis持久化配置2023-12-05 251
全部0条评论

快来发表一下你的评论吧 !
