

直接通过预测 3D 关键点来估计透明物体深度的 ML 系统
描述
计算机视觉应用领域的核心问题是3D 物体的位置与方向的估计,这与对象感知有关(如增强现实和机器人操作)。在这类应用中,需要知道物体在真实世界中的 3D 位置,以便直接对物体进行操作或在其四周正确放置模拟物。
围绕这一主题已有大量研究,但此类研究虽然采用了机器学习 (ML) 技术,特别是 Deep Nets,但直接测量与物体的距离大多依赖于 Kinect 等深度感应设备。而对于表面有光泽或透明的物体,直接采用深度感应难以发挥作用。例如,下图包括许多物体(左图),其中两个是透明的星星。深度感应设备无法很好的为星星测量深度值,因此难以重建 3D 点云效果图(右图)。
Deep Nets
https://arxiv.org/abs/1901.04780
左图:透明物体的 RGB 图像;右图:左侧场景的深度重建效果四格图,上排为深度图像,下排为 3D 点云,左侧图格采用深度相机重建,右侧图格是 ClearGrasp 模型的输出。需要注意的是,虽然 ClearGrasp 修复了星星的深度,但它却错误地识别了最右边星星的实际深度
要解决这个问题,可以使用深度神经网络来 修复 (Inpainting) 透明物体的错误深度图,例如使用 ClearGrasp 提出的方法:给定透明物体的单个 RGB-D 图像,ClearGrasp 使用深度卷积网络推断透明表面法线、遮挡和遮挡边界,然后通过这些信息完善场景中所有透明表面的初始深度估计(上图 最右)。这种方法很有前景,可以通过依赖深度的位置姿态估计方法处理具有透明物体的场景。但是修复可能会比较棘手,仍然可能导致深度错误,尤其是完全使用合成图像进行训练的情况。
我们与斯坦福大学 AI 实验室在 CVPR 2020 上合作发表了“KeyPose: Multi-View 3D Labeling and Keypoint Estimation for Transparent Objects”,论文描述了直接通过预测 3D 关键点来估计透明物体深度的 ML 系统。为了训练该系统,我们以半自动化方式收集了真实世界中透明物体图像的大型数据集,并使用人工选择的 3D 关键点标记有效姿态。然后开始训练深度模型(称为 KeyPose),从单目或立体图像中估计端到端 3D 关键点,而不明确计算深度。
论文
https://openaccess.thecvf.com/content_CVPR_2020/html/Liu_KeyPose_Multi-View_3D_Labeling_and_Keypoint_Estimation_for_Transparent_Objects_CVPR_2020_paper.html
在训练期间,模型在见过和未见过的物体上运行,无论是单个物体还是几类物体。虽然 KeyPose 可以处理单目图像,但立体图像提供的额外信息使其结果提高了两倍,根据物体不同,典型误差在 5 毫米至 10 毫米之间。它对这些物体的姿态预测远高于当前最先进水平,即使其他方法带有地面真实深度。我们将发布关键点标记的透明物体数据集,供研究界使用。
关键点标记的透明物体数据集
https://sites.google.com/corp/view/transparent-objects
透明物体数据集
为了方便收集大量真实世界图像,我们建立了一个机器人数据收集系统。系统的机械臂通过轨迹移动,同时使用立体摄像头和 Kinect Azure 深度摄像头拍摄视频。
使用带有立体摄像头和 Azure Kinect 设备的机械臂自动捕捉图像序列
目标上的 AprilTags 可以让摄像头准确跟踪姿态。通过人工标记每个视频中少量图像 2D 关键点,我们可以使用多视角几何图形为视频的所有帧提取 3D 关键点,将标记效率提高 100 倍。
我们捕捉了五种类别的 15 个不同透明物体的图像,对每个物体使用 10 种不同的背景纹理和 4 种不同的姿势,总计生成 600 个视频序列,包括 4.8 万个立体和深度图像。我们还用不透明版本的物体捕捉了相同的图像,以提供准确的深度图像。所有图像都标有 3D 关键点。我们将公开发布这一真实世界图像数据集,为 ClearGrasp 合成数据集提供补充。
真实世界图像数据集
https://sites.google.com/corp/view/transparent-objects
使用前期融合立体的 KeyPose 算法
针对关键点估计,本项目独立开发出直接使用立体图像的概念;这一概念最近也出现在手动跟踪的环境下。下图为基本思路:来自立体摄像头的两张图像的物体被裁剪并馈送到 KeyPose 网络,该网络预测一组稀疏的 3D 关键点,代表物体的 3D 姿态。KeyPose 网络使用 3D 关键点标记完成监督训练。
手动跟踪
https://bmvc2019.org/wp-content/uploads/papers/0219-paper.pdf

立体 KeyPose 的一个关键是使用允许网络隐式计算视差的前期融合来混合立体图像,与后期融合不同。后期融合是分别预测每个图像的关键点,然后再进行组合。如下图所示,KeyPose 的输出图像在平面上是 2D 关键点热力图,以及每个关键点的视差(即逆深度)热力图。这两张热力图的组合会为每个关键点生成关键点 3D 坐标。

Keypose 系统图:立体图像被传递到 CNN 模型,为每个关键点生成概率热力图。此热力图输出关键点的 2D 图像坐标 (U,V)。CNN 模型还为每个关键点生成一个视差(逆深度)热力图,与 (U,V) 坐标结合时,可以给出 3D 位置 (X,Y,Z)
相较于后期融合或单目输入,前期融合立体通常可以达到两倍的准确率。
结果
下图显示了 KeyPose 对单个物体的定性结果。左侧是一个原始立体图像,中间是投射到图像上的预测 3D 关键点。在右侧,我们将 3D 瓶子模型中的点可视化,并放置在由预测 3D 关键点确定的姿态上。该网络高效准确,在标准 GPU 上仅用 5 ms 的时间就预测出瓶子的 5.2 mm MAE (Mean Absolute Error) 和杯子的 10.1 mm MAE 关键点。
下表为 KeyPose 类别级别估计的结果。测试集使用了训练集未见过的背景纹理。注意,MAE 从 5.8 mm 到 9.9 mm 不等,这表明该方法的准确率非常高。
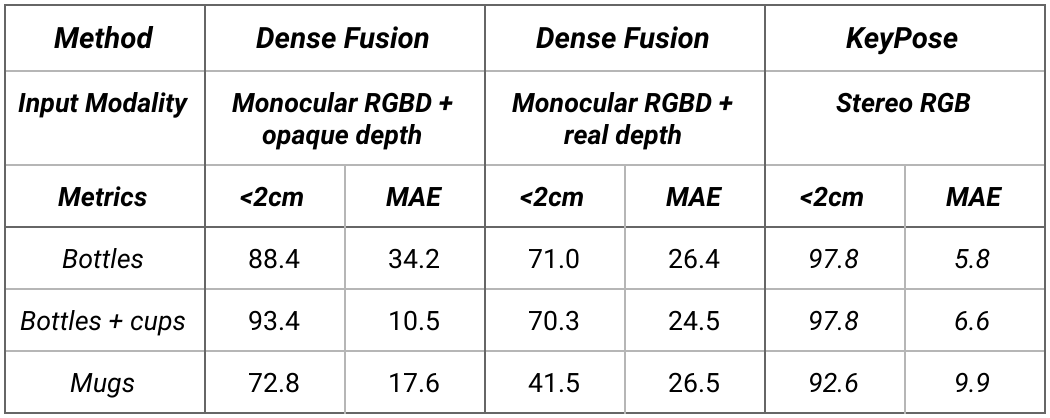
在类别级别数据上,KeyPose 与最先进的 DenseFusion 系统进行定量比较。我们为 DenseFusion 提供了两个版本的深度:透明物体与不透明物体。<2cm是误差小于 2cm 的估计百分比。MAE是关键点的平均绝对误差,以 mm 为单位。
DenseFusion
https://arxiv.org/abs/1901.04780
有关定量结果以及消融研究的完整说明,请参见论文和补充材料以及 KeyPose 网站。
论文和补充材料
https://openaccess.thecvf.com/content_CVPR_2020/html/Liu_KeyPose_Multi-View_3D_Labeling_and_Keypoint_Estimation_for_Transparent_Objects_CVPR_2020_paper.html
KeyPose 网站
https://sites.google.com/corp/view/keypose/
结论
该研究表明,在不依赖深度图像的情况下,从 RGB 图像中可以准确估计透明物体的 3D 姿态。经过验证,立体图像可以作为前期融合 Deep Net 的输入。在其中,网络被训练为直接从立体对中提取稀疏 3D 关键点。我们希望提供广泛的带标签透明物体数据集,推动这一领域的发展。最后,尽管我们使用半自动方法对数据集进行了有效标记,但我们希望在以后的工作中能够采用自监督方法来消除人工标记。
致谢
感谢合著者:斯坦福大学的 Xingyu Liu 以及 Rico Jonschkowski 和 Anelia Angelova;以及在项目和论文撰写过程中,与我们一起讨论并为我们提供帮助的人,包括 Andy Zheng、Suran Song、Vincent Vanhoucke、Pete Florence 和 Jonathan Tompson。
原文标题:机器人收集 + Keypose 算法:准确估计透明物体的 3D 姿态
文章出处:【微信公众号:TensorFlow】欢迎添加关注!文章转载请注明出处。
-
采用 DLP® 技术的顶级立体光固化成型印刷 3D 打印机2015-04-28 0
-
3D检测系统可检测PCB板针脚高度2016-01-05 0
-
3D扫描的结构光2018-08-30 0
-
3D TOF深度剖析2019-07-25 0
-
机器视觉3D成像技术大全!2019-11-19 0
-
如何做个可以扫描物体的3D扫描器?2020-08-27 0
-
3D视觉的测量原理2020-12-01 0
-
如何通过Synopsys解决3D集成系统的挑战?2021-05-10 0
-
浩辰3D的「3D打印」你会用吗?3D打印教程2021-05-27 0
-
基于深度学习和3D图像处理的精密加工件外观缺陷检测系统2022-03-08 0
-
裸眼3D显示应用2022-11-07 0
-
使用结构光的3D扫描介绍2022-11-16 0
-
3D扫描到底是如何进行的?2022-11-17 0
-
使用DLP技术的3D打印2022-11-18 0
-
基于几何单目3D目标检测的密集几何约束深度估计器2022-10-09 710
全部0条评论

快来发表一下你的评论吧 !
