

BP神经网络的概念
描述
最近学习BP神经网络,网上文章比较参差不齐,对于初学者还是很困惑,本文做一下笔记和总结,方便以后阅读学习。
一、BP神经网络的概念
BP神经网络是一种多层的前馈神经网络,其主要的特点是:信号是前向传播的,而误差是反向传播的。具体来说,对于如下的只含一个隐层的神经网络模型:输入向量应为n个特征
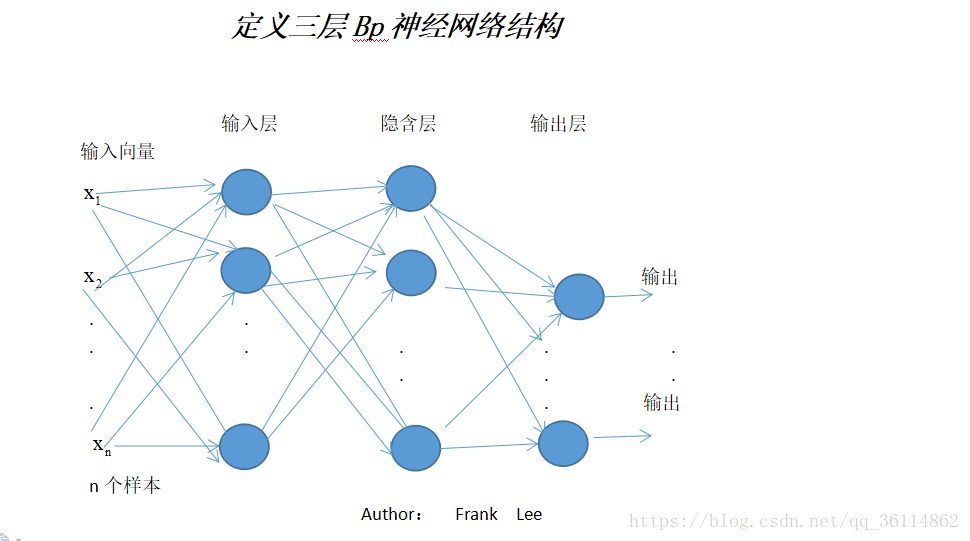
BP神经网络的过程主要分为两个阶段,第一阶段是信号的前向传播,从输入层经过隐含层,最后到达输出层;第二阶段是误差的反向传播,从输出层到隐含层,最后到输入层,依次调节隐含层到输出层的权重和偏置,输入层到隐含层的权重和偏置。
1. 神经元:神经元,或称神经单元/神经节点,是神经网络基本的计算单元,其计算函数称为激活函数(activation function),用于在神经网络中引入非线性因素,可选择的激活函数有:Sigmoid函数、双曲正切函数(tanh)、ReLu函数(Rectified Linear Units),softmax等。
1.1 Sigmoid函数,也就是logistic函数,对于任意输入,它的输出范围都是(0,1)。公式如下:
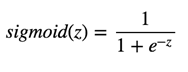
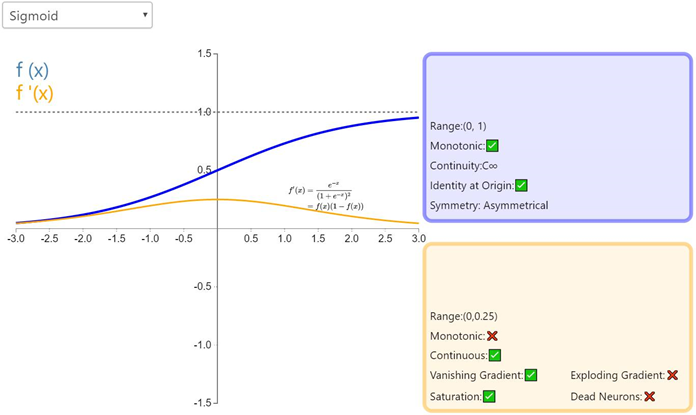
Sigmoid的函数图如上所示,很像平滑版的阶跃函数。但是,sigmoid 有很多好处,例如:
(1)它是非线性的
(2)不同于二值化输出,sigmoid 可以输出0 到 1 之间的任意值。对,跟你猜的一样,这可以用来表示概率值。
( 3)与 2 相关,sigmoid 的输出值在一个范围内,这意味着它不会输出无穷大的数。但是,sigmoid 激活函数并不完美: 梯度消失。如前面的图片所示,当输入值 z 趋近负无穷时,sigmoid 函数的输出几乎为 0 . 相反,当输入 z 趋近正无穷时,输出值几乎为 1 . 那么这意味着什么?在这两个极端情况下,对应的梯度很小,甚至消失了。梯度消失在深度学习中是一个十分重要的问题,我们在深度网络中加了很多层这样的非线性激活函数,这样的话,即使第一层的参数有很大的变化,也不会对输出有太大的影响。换句话讲,就是网络不再学习了,通常训练模型的过程会变得越来越慢,尤其是使用梯度下降算法时。
1.2 Tanh函数
Tanh 或双曲正切是另一个深度神经网络中常用的激活函数。类似于 sigmoid 函数,它也将输入转化到良好的输出范围内。具体点说就是对于任意输入,tanh 将会产生一个介于 -1 与 1 之间的值。
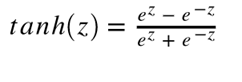
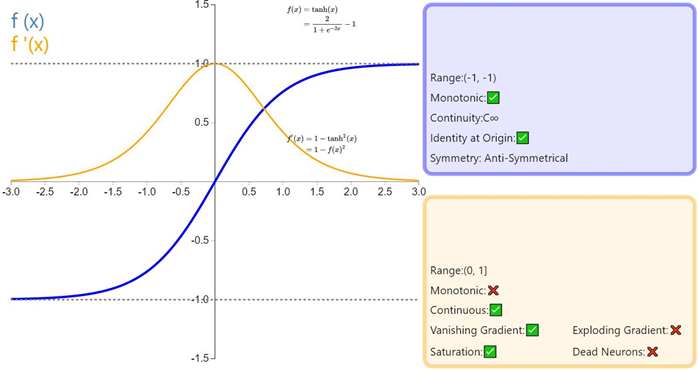
Tanh函数图
如前面提及的,tanh 激活函数有点像 sigmoid 函数。非线性且输出在某一范围,此处为 (-1, 1)。不必意外,它也有跟 sigmoid 一样的缺点。从数学表达式就可以看出来,它也有梯度消失的问题,以及也需要进行开销巨大的指数运算。
1.3
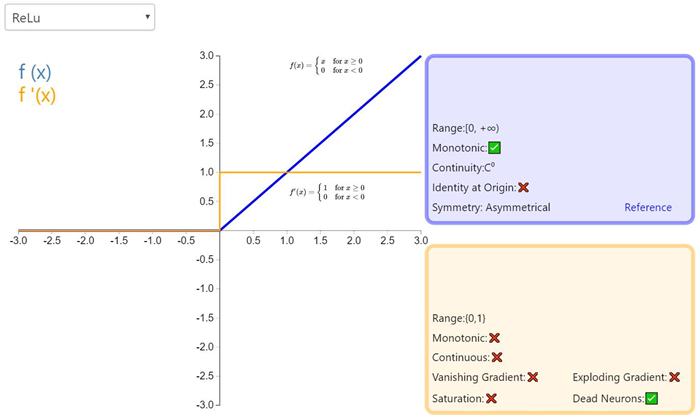
ReLU
终于讲到了 Relu,人们起初并不觉得它的效果会好过 sigmoid 和 tanh。但是,实战中它确实做到了。事实上,cs231n 课程甚至指出,应该默认使用 Relu 函数。
ReLU 从数学表达式来看,运算十分高效。对于某一输入,当它小于 0 时,输出为 0,否则不变。下面是 ReLU 的函数表达式。Relu(z) = max(0,z)
那么你可能会问,「它是线性函数吧?为何我们说它是非线性函数?」
在线代中,线性函数就是两个向量空间进行向量加和标量乘的映射。
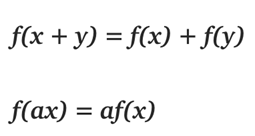
给定上面的定义,我们知道 max(0, x) 是一个分段线性函数。之所以说是分段线性,是因为它在 (−∞, 0] 或 [0,+∞) 上符合线性函数的定义。但是在整个定义域上并不满足线性函数的定义。例如f(−1) + f(1) ≠f (0)
所以 Relu 就是一个非线性激活函数且有良好的数学性质,并且比 sigmoid 和 tanh 都运算得快。除此以外,Relu 还因避免了梯度消失问题而闻名。然而,ReLU 有一个致命缺点,叫「ReLU 坏死」。ReLu 坏死是指网络中的神经元由于无法在正向传播中起作用而永久死亡的现象。
更确切地说,当神经元在向前传递中激活函数输出为零时,就会出现这个问题,导致它的权值将得到零梯度。因此,当我们进行反向传播时,神经元的权重将永远不会被更新,而特定的神经元将永远不会被激活。
还有件事值得一提。你可能注意到,不像 sigmoid 和 tanh,Relu 并未限定输出范围。这通常会成为一个很大的问题,它可能在另一个深度学习模型如递归神经网络(RNN)中成为麻烦。具体而言,由 ReLU 生成的无界值可能使 RNN 内的计算在没有合理的权重的情况下发生数值爆炸。因此反向传播期间权重在错误方向上的轻微变化都会在正向传递过程中显著放大激活值,如此一来学习过程可能就非常不稳定。我会尝试在下一篇博客文章中详细介绍这一点。(摘自https://my.oschina.net/amui/blog/1633904)
1.4 softmax简介
Softmax回归模型是logistic回归模型在多分类问题上的推广,在多分类问题中,待分类的类别数量大于2,且类别之间互斥。比如我们的网络要完成的功能是识别0-9这10个手写数字,若最后一层的输出为[0,1,0, 0, 0, 0, 0, 0, 0, 0],则表明我们网络的识别结果为数字1。
Softmax的公式为
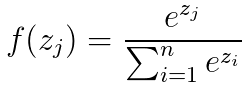
,可以直观看出如果某一个zj大过其他z,那这个映射的分量就逼近于1,其他就逼近于0,并且对所有输入数据进行归一化。
2.权重:
3.偏置
偏置单元(bias unit),在有些资料里也称为偏置项(bias term)或者截距项(intercept term),它其实就是函数的截距,与线性方程 y=wx+b 中的 b 的意义是一致的。在 y=wx+b中,b表示函数在y轴上的截距,控制着函数偏离原点的距离,其实在神经网络中的偏置单元也是类似的作用。
因此,神经网络的参数也可以表示为:(W, b),其中W表示参数矩阵,b表示偏置项或截距项。
2.反向传播调节权重和偏置
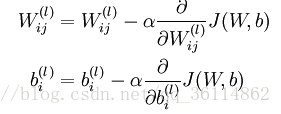
-
神经网络教程(李亚非)2012-03-20 0
-
求利用LABVIEW 实现bp神经网络的程序2012-11-26 0
-
求基于labview的BP神经网络算法的实现过程2012-12-10 0
-
关于BP神经网络预测模型的确定!!2014-02-08 0
-
用labview框图编写的BP神经网络程序vi2015-05-28 0
-
labview BP神经网络的实现2017-02-22 0
-
【案例分享】基于BP算法的前馈神经网络2019-07-21 0
-
如何设计BP神经网络图像压缩算法?2019-08-08 0
-
BP神经网络PID控制电机模型仿真2020-02-22 0
-
BP神经网络的基础数学知识分享2020-06-16 0
-
基于BP神经网络的PID控制2021-09-07 0
-
基于BP神经网络的辨识2017-12-06 1118
-
BP神经网络概述2018-06-19 43170
-
BP神经网络原理及应用2021-04-27 837
全部0条评论

快来发表一下你的评论吧 !
