

关于Redis缓存的原因及解决方案
电子说
描述
下面开始今天的正文,看见小小怎么辛苦的份上,滑到底下,给个素质三连?
缓存雪崩
缓存雪崩是指在某一个时间段内,缓存集中过期失效,如果这个时间段内有大量请求,而查询数据量巨大,所有的请求都会达到存储层,存储层的调用量会暴增,引起数据库压力过大甚至宕机。
原因
Redis突然宕机
大部分数据失效
举个栗子
比如我们基本上都经历过购物狂欢节,假设商家举办 23:00-24:00 商品打骨折促销活动。程序小哥哥在设计的时候,在 23:00 把商家打骨折的商品放到缓存中,并通过redis的expire设置了过期时间为1小时。这个时间段许多用户访问这些商品信息、购买等等。但是刚好到了24:00点的时候,恰好还有许多用户在访问这些商品,这时候对这些商品的访问都会落到数据库上,导致数据库要抗住巨大的压力,稍有不慎会导致,数据库直接宕机(over)。
当商品没有失效的时候是这样的:
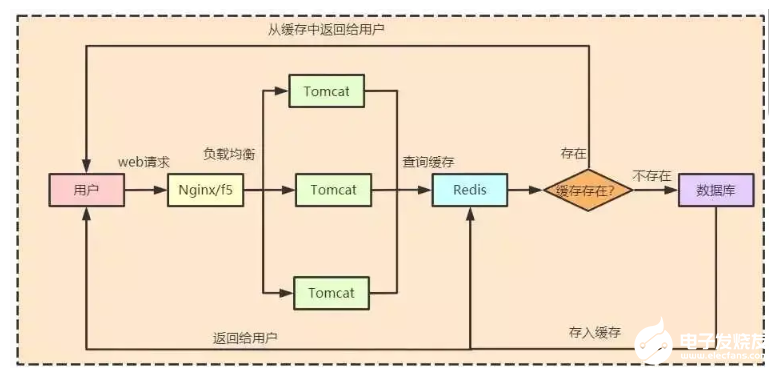
当缓存GG(失效)的时候却是这样的:
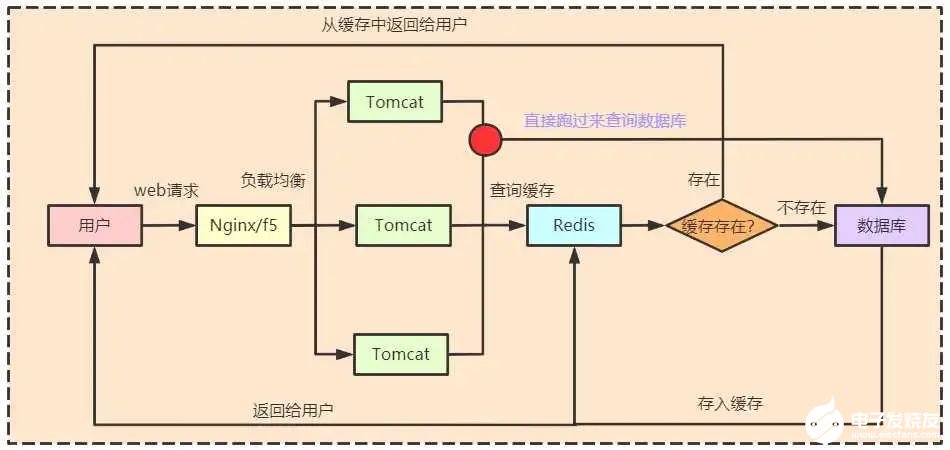
对于缓存雪崩有以下解决方案:
(1)redis高可用
redis有可能挂掉,多增加几台redis实例,(一主多从或者多主多从),这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
(2)限流降级
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量,对某个key只允许一个线程查询数据和写缓存,其他线程等待。
(3)数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key。
(4)不同的过期时间
设置不同的过期时间,让缓存失效的时间点尽量均匀。
缓存穿透
什么是缓存穿透,当用户在查询一条数据的时候,而此时数据库和缓存没有任何关于这条数据的任何记录的时候,当这条数据再缓存中没找到数据,就会向数据库请求数据,这样就会对数据库造成比较大的压力。如:用户查询一个 id = -1 的商品信息,一般数据库 id 值都是从 1 开始自增,很明显这条信息是不在数据库中,当没有信息返回时,会一直向数据库查询,给当前数据库的造成很大的访问压力。解决方案有俩个,分别为缓存空对象,布隆过滤器。
缓存空对象
缓存空对象它就是指一个请求发送过来,如果此时缓存中和数据库都不存在这个请求所要查询的相关信息,那么数据库就会返回一个空对象,并将这个空对象和请求关联起来存到缓存中,当下次还是这个请求过来的时候,这时缓存就会命中,就直接从缓存中返回这个空对象,这样可以减少访问数据库的压力,提高当前数据库的访问性能。我们接下来可以看下面这个流程
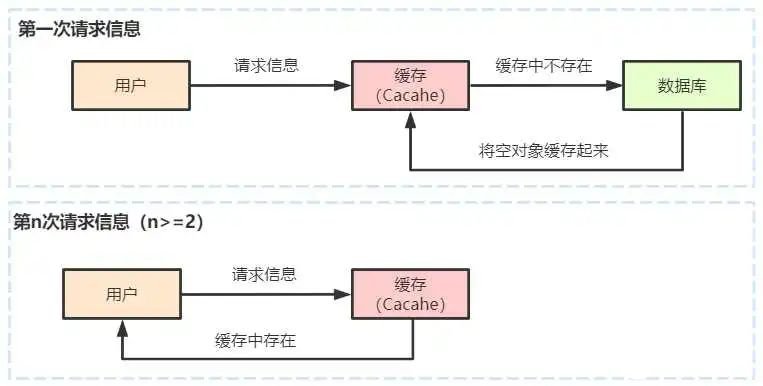
并且为了大量的空对象过多,导致缓存空对象也过多,所以需要利用Redis的过期机制,解决这个问题。
setex key seconds valule:设置键值对的同时指定过期时间(s)
在Java中
redisCache.put(Integer.toString(id), null, 60) //过期时间为 60s
布隆过滤器
布隆过滤器用来过滤东西的。它是一种基于概率的数据结构,主要使用爱判断当前某个元素是否在该集合中,运行速度快。我们也可以简单理解为是一个不怎么精确的 set 结构(set 具有去重的效果)。但是有个小问题是:当你使用它的 contains 方法去判断某个对象是否存在时,它可能会误判。也就是说布隆过滤器不是特别不精确,但是只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
举个栗子
打个比方,当它说不认识你时,肯定就不认识;当它说见过你时,可能根本就没见过面,不过因为你的脸跟它认识的人中某脸比较相似 (某些熟脸的系数组合),所以误判以前见过你。在上面的使用场景中,布隆过滤器能准确过滤掉那些已经看过的内容,那些没有看过的新内容,它也会过滤掉极小一部分 (误判),但是绝大多数新内容它都能准确识别。这样就可以完全保证推荐给用户的内容都是无重复的。
特点
一个非常大的二进制位数组(数组中只存在 0 和 1)
拥有若干个哈希函数(Hash Function)
在空间效率和查询效率都非常高
布隆过滤器不会提供删除方法,在代码维护上比较困难。
每个布隆过滤器对应到 Redis 的数据结构里面就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
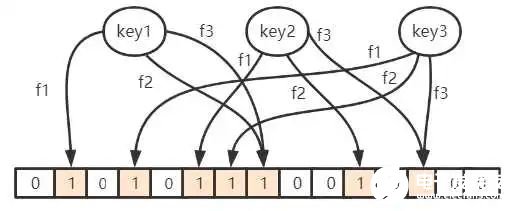
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。( 每一个 key 都通过若干的hash函数映射到一个巨大位数组上,映射成功后,会在把位数组上对应的位置改为1。)
为什么存在误判率
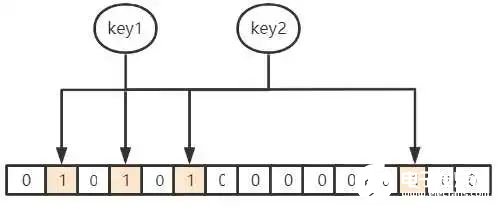
当 key1 和 key2 映射到位数组上的位置为 1 时,假设这时候来了个 key3,要查询是不是在里面,恰好 key3 对应位置也映射到了这之间,那么布隆过滤器会认为它是存在的,这时候就会产生误判(因为明明 key3 是不在的)。
提高准确率
哈希函数的好坏
存储空间大小
哈希函数个数 hash函数的设计也是一个十分重要的问题,对于好的hash函数能大大降低布隆过滤器的误判率。同时,对于一个布隆过滤器来说,如果其位数组越大的话,那么每个key通过hash函数映射的位置会变得稀疏许多,不会那么紧凑,有利于提高布隆过滤器的准确率。同时,对于一个布隆过滤器来说,如果key通过许多hash函数映射,那么在位数组上就会有许多位置有标志,这样当用户查询的时候,在通过布隆过滤器来找的时候,误判率也会相应降低。
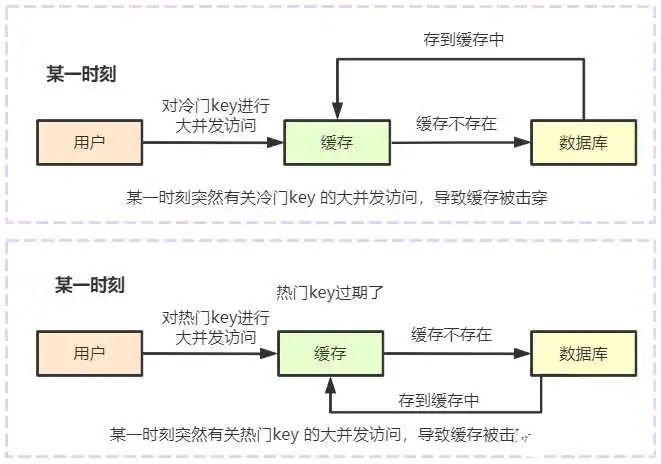
缓存击穿
一个被经常访问并且查询到的key,经常有用户访问,但是这个时候,这个key正好到了失效时间,或者突然变成冷门key,此时仍然有大量的关于这个的key的请求,这样会造成大量的并发访问到数据库,造成数据库的压力剧增。导致缓存击穿的产生。
原因有两条。
一个冷门的key,突然有大量的用户请求访问。
一个热门的key恰好到了过期的时间。
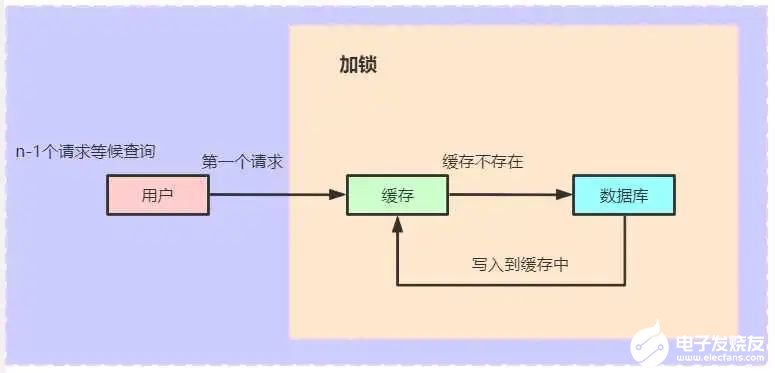
缓存击穿问题的解决: 加锁,对于key过期的时候,查询数据库的时候加锁,可以让只有一个连接访问到数据库,然后获取到key缓存到redis中,减少了缓存的压力。在单机幻觉使用单机的锁,在分布式环境下使用分布式锁。
编辑:hfy
-
Redis缓存和MySQL数据不一致原因和解决方案2019-03-27 0
-
使用Redis缓存model层2019-04-18 0
-
redis缓存注解怎么使用2019-09-11 0
-
Redis在高速缓存系统中的序列化算法研究2017-11-23 643
-
Java 使用Redis缓存工具的详细解说2018-02-09 7628
-
redis缓存mysql数据2018-02-09 3854
-
Redis常见面试题及答案2020-12-16 1933
-
缓存雪崩/穿透/击穿的解决方案2021-01-26 1118
-
Redis缓存的异常原因及其处理办法分析2023-02-06 489
-
SpringBoot+Redis实现点赞功能的缓存和定时持久化(附源码)2023-02-09 3930
-
如何在SpringBoot中解决Redis的缓存穿透等问题2023-04-28 508
-
Redis数据同步解决方案—NineData2023-06-05 528
-
Oracle与Redis Enterprise协同,作为企业缓存解决方案2023-11-22 280
-
Redis Enterprise vs ElastiCache——如何选择缓存解决方案?2023-11-26 171
-
redis分布式锁可能出现的问题及解决方案2023-12-04 356
全部0条评论

快来发表一下你的评论吧 !
