

如何定义网络架构或结构加速视觉系统的优化
描述
当人们讨论深度神经网络(DNN)、深度学习和嵌入式视觉时,通常会先讨论如何定义网络架构或结构。不久之前,我们还只能支持线性网络,在输入和输出级之间的层数非常有限。相比之下,今天的网络技术,如谷歌的TensorFlow,支持多个输入、多个输出以及每级多个层。
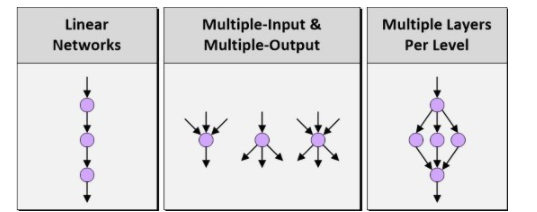
图1:线性网络、多输入&多输出以及每级多个层
TensorFlow的强大令人难以置信,但人工定义TensorFlow架构类似于用汇编语言编写一个复杂的软件。因此Bonsai等公司开始研究提升抽象等级,帮助更多的开发人员在他们的工作中融合更加丰富的智能模型。一旦定义好网络结构,下一步就是训练这种结构,并用32位浮点系数(“加权”)产生一个新的版本。假设我们在创建某类嵌入式视觉图像处理应用,这个过程——可能会用到数十万甚至数百万幅分类照片——可以在高层进行描述,如图2所示。
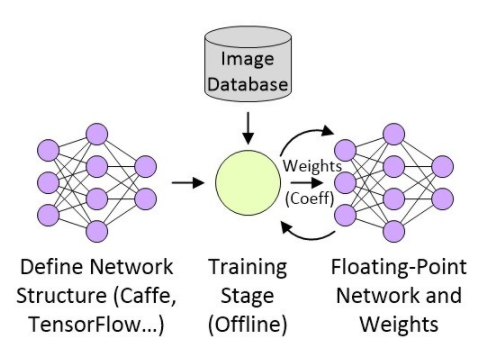
图2:创建嵌入式视觉图像处理应用
网络经过训练之后,下一步就是准备部署网络了,这与目标平台有关。假设这是一个性能受限的、具有功耗意识的部署平台,那么浮点网络需要被转换为定点网络,如图3所示(虽然16位定点实现很常见,但低至8位定点的实现也有大量成功的案例)。
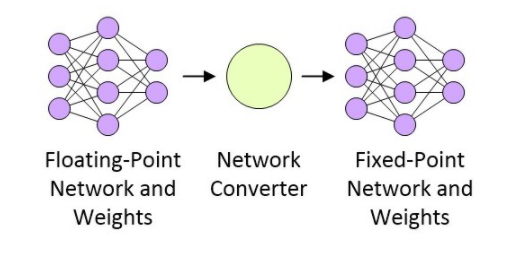
图3:浮点网络转换为定点网络
CEVA正在做一些非常有意思的研发工作,包括一种网络产生器。这种网络产生器采用基于Caffe或TenserFlow(任何形式)的网络浮点表示法,并将其转换为小型快速高能效的定点网络,目标应用是CEVA-XM4智能视觉处理器。
投入实际使用之前的最后一步是将网络部署进目标系统,目标系统可以是MCU、FPGA或基于SoC的系统,且可作为目标检测和识别系统的一部分。
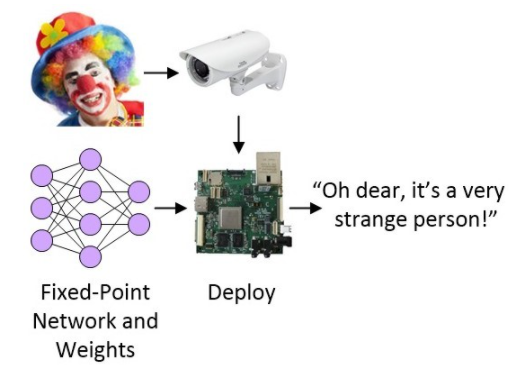
图4:将网络部署进目标系统
目前为止情况一切都很好,但是……
还有巨大的改进空间
与大多数事情一样,如果只是随便说说,那么上面的描述听起来也不错。然而,在一线搭建实际系统的开发人员知道,还有许多事情要考虑。
就拿第一步训练网络所用到的图像来说,用什么设备来捕获这些图像?在物理范畴,我们可能会讨论镜头、图像传感器和模拟前端(AFE)等东西。在此之上,我们必须考虑图像处理管线(可以用软件函数实现,或使用硬件加速器)中采用的所有算法,比如增益控制、白平衡、噪声抑制和锐化、颜色空间转换、插值、压缩……等等。
当然,所有这一切也适合用于捕获和处理图像的任何后端摄像系统,这些图像最后馈入人工神经网络,实现检测、识别、分类和其它用途。
越来越多的公司将摄像机和智能视觉技术集成进产品中,系统的图像质量和精度是体现其价值的核心。除了镜头和传感器等物理组件,一个典型的图像处理管线可能会达到10级,每级可能有大约25个调整参数。在光学、传感器、处理器和算法组合之间优化这些系统需要付出很大的努力,而且每个产品和衍生品都要完成这一辛苦的工作,因此可能会限制待评估的替代配置的数量。
为了解决这一问题,Algolux公司以其机器学习解算器为基础设计了一种最优化的平台架构,名为CRISP-ML(运算型可重配置图像信号平台)。这种架构可以根据标准图像测试卡、加有标签的训练图像和关键性能指示器(KPI)目标调整成像和计算机视觉算法,在规定的成像条件下取得理想的图像质量、视觉精度、功耗和性能目标。这种方案可以极大地减少优化一个新视觉系统所需的时间和成本,将专家资源留给价值更高的任务。
当我第一次听到这一切时,第一反应就是Algolux的员工正在使用基因算法玩“魔术”。不过,Algolux公司首席技术官Paul Green表示,他们其实并没有使用基因算法,而是使用“有指导性的随机搜索与基于微积分的搜索的一种组合”。哇,这才真正激起了我的兴趣——“真是个坏小子!”。我期望在不远的将来能够学习到更多的内容,并写出更多的报道来。
编辑:hfy
-
#硬声创作季 机器视觉教程:视觉系统基本术语Mr_haohao 2022-10-02
-
机器视觉系统在注塑行业的应用2014-06-09 0
-
贴片机视觉系统组成2018-11-27 0
-
基于图像分析技术的无编程新型机器视觉系统2019-06-21 0
-
嵌入式机器视觉系统有什么特性?怎么优化?2020-03-11 0
-
机器视觉系统的工作原理是什么?有哪些应用实例?2021-07-16 0
-
机器视觉系统是指什么? 机器视觉系统的工作原理是什么?2021-07-16 0
-
机器视觉系统原理及基础知识2011-12-16 2034
-
嵌入式机器视觉系统优化研究2012-08-13 579
-
基于嵌入式机器视觉系统优化研究2017-10-31 687
-
视觉系统应用基础2017-11-17 2371
-
南京大学提出垂直结构的类脑视觉系统,为实现类脑机器视觉提供了思路2020-09-27 3262
-
机器视觉系统的结构由什么部分组成2020-10-14 12402
-
机器视觉系统的经典应用2021-05-28 743
-
视觉系统的构成 机器视觉中常用的接口有哪些2023-09-05 543
全部0条评论

快来发表一下你的评论吧 !
