

CPLD基于FPGA实现FIR滤波器的研究
FPGA/ASIC技术
描述
摘要: 针对在FPGA中实现FIR滤波器的关键--乘法运算的高效实现进行了研究,给了了将乘法化为查表的DA算法,并采用这一算法设计了FIR滤波器。通过FPGA仿零点验证,证明了这一方法是可行和高效的,其实现的滤波器的性能优于用DSP和传统方法实现FIR滤波器。最后介绍整数的CSD表示和还处于研究阶段的根据FPGA实现的要求改进的最优表示。
关键词: FPGA DA FIR滤波器 CSD
数字滤波器是语音与图像处理、模式识别、雷达信号处理、频谱分析等应用中的一种基本的处理部件,它能满足波器对幅度和相位特性的严格要求,避免模拟乙波器所无法克服的电压漂移、温度漂移和噪声等问题。有限冲激响应(FIR)滤波器能在设计任意幅频特性的同时保证严格的线性相位特性。
目前FIR滤波器的实现方法有三种:利用单片通用数字滤波器集成电路、DSP器件和可编程逻辑器件实现。单片通用数字滤波器使用方便,但由于字长和阶数的规格较少,不能完全满足实际需要。使用DSP器件实现虽然简单,但由于程序顺序执行,执行速度必然不快。FPGA有着规整的内部逻辑阵列和丰富的连线资源,特别适合于数字信号处理任务,相对于串行运算为主导的通用DSP芯片来说,其并行性和可扩展性更好。但长期以来,FPGA一直被用于系统逻辑或时序控制上,很少有信号处理方面的应用,其原因主要是因为在FPGA中缺乏实现乘法运算的有效结构。现在这个问题得到了解决,使FPGA在数字信号处理方面有了长足的发展。
图1
1 分布式运算原理
分布式算法(DA)早在1973年就已经被Croisier提出来了,但是直到FPGA出现以后,才被广泛地应用在FPGA中计算乘积和。
一个线性时不变网络的输出可以用下式表示:
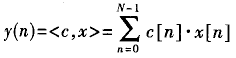
=c[0]x[0]+c[1]x[1]+…+c[N-1]x[N-1]
假设系数c[n]是已知常数,x[n]是变量,在有符号DA系统中假设变量x[n]的表达式如下:
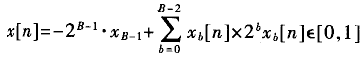
式中,xb[n]表示z[叫的第b位,而x[n]也就是x的第n次采样。于是,内积y可以表示为:
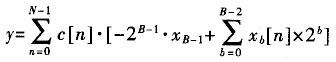
重新分别求和(也就是分布式算法的由来),其结果如下:
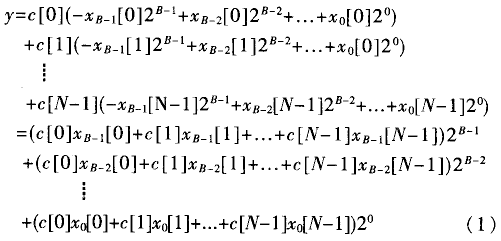
从(1)式可以发现,分布式算法是一种以实现乘加运算为目的的运算方法。它与传统算法实现乘加运算的不同在于执行部分积运算的先后顺序不同。分布式算法在实现乘加功能时,是通过将各输入数据的每一对应位产生的部分积预先进行相加形成相应的部分积,然后再对各个部分积累加形成最终结果的,而传统算法是等到所有乘积已经产生之后再来相加完成乘加运算的。与传统串行算法相比,分布式算法可极大地减少硬件电路的规模,提高电路的执行速度。它的实现框图如图1(虚线为流水线寄存器)所示。
图2
2 用分布式原理实现FIR滤波器
2.1 串行方式
当系统对速度的要求不高时,可以采用串行的设计方法,即采用一个DA表、一个并行累加器和少量的寄存器就可以了。
在用LUT实现串行分布式算法的时候,假设系数为8位,则DA表的规模为2N×8位。可以看到如果抽头系数N过多,则DA表的规模将十分庞大。这是因为LUT的规模随着地址空间的变化(也就是N的增加)而呈指数增加。例如EPFl0K20包含1152个LC,而一个27×7位的表就需要394个LC。当N过大时,一个FPGA器件就不够用了。
为了减小规模,可以利用部分表计算,然后将结果相加。假定长度为LN的内积为:
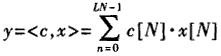
将和分配到L个独立的N阶并行DA的LUT之中结果如下:
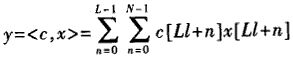
如图2所示,实现一个4N的DA设计需要3个次辅助加法器。表格的规模从一个2 N×B位的LUT降到4个2 N×B的位表。
如果再加上流水线寄存器,由于EPFl0K20每个LC后面都跟有一个寄存器,所以并没有增加电路规模,而速度却得到了提高。
2.2 并行方式
采用并行方式的好处是处理速度得到了提高。由于数据是并行输入,所以计算速度要比串行方式快,但它的代价是硬件规模更大了。下面举出全并行的例子。
设 sum[0]=c[0]x0+[0]+c[1]x0[1]+…+c[N-1]x0[N-1]
sum[B-1]=c[B-1]xB-1[0]+c[1]xB-1[1]+…c[N-1]+xB-1[N-1]
可将(1)式改写成如下形式
y=sum[0]+sum[1]2 1+sum[2] 2+…+sum[B-1]2 B-1 (2)
利用式(2)可得一种直观的加法器树,如图3所示。
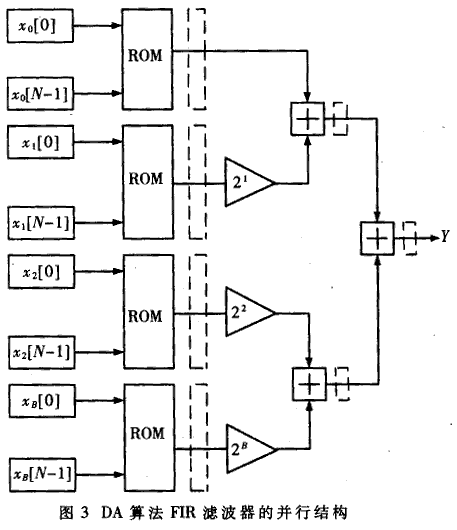
虽然硬件规模加大了,但是如果把系数的个数限制在4个或8个,再加上流水线寄存器,这个代价还是值得的。而且每张表都是相同的,不用为每个采样都设计一张表,减小了设计量。
DA算法的主要特点,是巧妙地利用ROM查找表将固定系数的MAC运算转化为查表操作,其运算速度不随系数和输入数据位数的增加而降低,而且相对直接实现乘法器而言在硬件规模上得到了极大的改善。利用ALTERA的FLEXl0K实现的16阶8位系数的并行FIR滤波器,其时钟频率可以达到101MHz,而实现的16阶8位系数的串行FIR滤波器,其时钟频率可以达到63MHz,每9个时钟周期可完成一次计算。但是其系数是传统二进制的,造成了很大的冗余(对于用逐位相加法实现的乘法器,当系数有一位为零时不用相加,零位越多,冗余越大),而且查找表的大小随着滤波器阶数的增加成指数增加,虽然可以采用将大查找表分解为小查找表,但是无法从根本上解决这一问题,这些都是DA方法的缺点。后面将对FIR滤波器实现给出新的设计方法,进一步降低逻辑资源的消耗。
3 CSD码及最优化方法
一个整数X与另一整数Y的乘积的二进制表示可以写成:
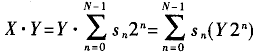
对于标准二进制,由于sn=0时的对应项Y2n并不参与累加运算,所以可以用另一种表示方法使非零元素的数量降低,从而使加法器的数目减少,降低硬件规模。有符号数字量(SD)有三重值{0,-1,+1},如果任意两个非零位均不相邻,即为标准有符号数字量(CSD)。
可以证明CSD表示对给定数是唯一的并且是最少非零位的。CSD表示相对于标准二进制表示的改进在于引入了负的符号位,从而降低了非零位个数,大大降低了逻辑资源的占用(大约平均降低33%的逻辑资源)。
当用硬件实现时,常常限制系数位数,即每个系数与N个正(负)2的幂次之和近似。标准二进制数在整数轴上是紧密和均匀分布的,而CSD码是非均匀分布的,其对实系数的量化误差比标准二进制大,虽然增加N可以减小量化误差,但是会增大逻辑资源的消耗;而且CSD表示无法应用流水线结构,从而降低处理速度。
还可采用优化的方法将系数先拆分成几个因子,再实现具体因子。这就是最优化的代码。例如对系数93,93=10111012=1100101CSD。用最优化法,系数93可以表示成93=3·31,每个因子需要一个加法器,如图4所示。
图4
从图中可以看出,CSD码需要三个加法器,而最优法只需要两个加法器;CSD码的重要缺陷在于每一级加法都需要初节点参与,而最优表示仅依赖上一级加法的结果,因此也就更适合流水线处理。Dempster等人提出了需要1到4个加法器的所有可能配置表。利用这张表,就可以合成成本在0与4个加法器之间的所有8位二进制整数。
本文首先给出了一种巧妙利用FPGA的查找表,将乘法转化为查找表运算的DA算法,并用ALTERA的FLEXlOK器件分别实现了一个8位16阶的串行与并行FIR滤波器,系统频率分别达到63MHz与101MHz,采样速度分别达到7MSPS与101MSPS。而DSP实现的FIR滤波器只能达到5MSPS,明显低于FPGA。用传统的位串行方法实现的一个8阶8位FIR滤波器,也只能达到5MSPS,明显低于串行式DA方法;接着,针对系数的二进制表示非零位不是最少(即实现系数乘法的加法器不是最少)的问题,介绍了整数的CSD表示以及最优表示,它们可以用较小的代价和与加法器级数无关的处理速度实现整数乘法运算,能比DA方法用更少的逻辑资源实现FIR滤波器。这些算法都不同于传统的设计观念,为基于FPGA的DSP设计提出了新的思路,必将在高速FIR滤波器设计、高速FFT设计中得到广泛的应用。随着FPCA集成规模的不断提高,许多复杂的数学运算已经可以用FPCA来实现,利用单片FPGA实现系统的设想即将变为现实。
- 相关推荐
- FIR
-
基于FPGA的FIR滤波器设计与实现2012-08-11 0
-
fpga实现滤波器2012-08-12 0
-
基于fpga的fir滤波器的实现2012-08-17 0
-
基于FPGA的fir滤波器实现2017-08-28 0
-
如何利用CPLD去实现FIR数字滤波器?2021-04-28 0
-
怎么利用FPGA实现FIR滤波器?2021-04-29 0
-
怎么在FPGA上实现FIR滤波器的设计?2021-05-07 0
-
基于FPGA对称型FIR滤波器的设计与实现2009-09-25 371
-
如何用用FPGA实现FIR滤波器2009-03-30 4531
-
基于FPGA设计的FIR滤波器的实现与对比2012-11-09 924
-
用CPLD实现FIR数字滤波器的设计2017-01-10 726
-
用CPLD实现FIR数字滤波器2017-01-10 734
-
基于FPGA实现变采样率FIR滤波器的研究2017-01-08 855
-
基于FPGA的32阶FIR滤波器的设计与实现2017-11-10 965
全部0条评论

快来发表一下你的评论吧 !
