

腾讯AI推出“绝悟”完全体
电子说
描述
说起 MOBA 类手游,想必大家都能想到王者荣耀。它近日又有了新动作。11 月 28 日腾讯宣布,旗下腾讯 AI Lab 与王者荣耀联合研发的策略协作型 AI “绝悟” 推出升级版本 “绝悟 “完全体。 目前,“绝悟 “背后采用的创新算法突破了 AI 的英雄上限,英雄池数量也从 40 个增至 100 + 个。创新算法能够让 AI 完全掌握所有英雄的所有技能,同时应对高达 10 的 15 次方的英雄组合数变化,几乎覆盖人类玩家能够选出的组合。另一技术亮点则是优化了禁选英雄(BanPick,简称 BP)博弈策略,能综合自身技能与对手情况等多重因素派出最优英雄组合。 相关研究已被 AI 顶级会议 NeurIPS 2020 与顶级期刊 TNNLS 收录,两篇论文的一作均为腾讯的 Deheng Ye(叶德珩)。
同时,“绝悟” 完全体版本已在王者荣耀 App 限时开放。各荣耀玩家可以上线与之对战,体验时间为 11 月 14 日至 30 日,绝悟在 20 个关卡的能力不断提升,最强的 20 级于 11 月 28 日开放,接受 5v5 组队挑战。
AI 策略:红方 AI 铠大局观出色,绕后蹲草丛扭转战局 积少成多,自古英雄出少年
王者荣耀中,最吸引人的称号是:“全能高手”。想要获得它却很难,你需要在五个职业中(对抗路、中路、发育路、游走、打野)都拥有 4 个紫色熟练度英雄。但因为练习时间与精力限制,很少有人能精通所有英雄。 而 “绝悟”技术团队一年内让 AI 掌握的英雄数从 1 个增加到 100 + 个,完全解禁英雄池,此版本因此得名 “绝悟完全体”。 那么 “绝悟完全体” 是怎样做到的呢? 我们知道,从零学会单个阵容易如反掌,但面对多英雄组合时就难如登天。在对战中,因为地图庞大且信息不完备,不同的 10 个英雄组合应该有不同的策略规划、技能应用、路径探索及团队协作方式,这将使决策难度几何级增加。并且,多英雄组合也带来了 “灾难性遗忘” 问题,这使得模型容易边学边忘,是长期困扰开发者的大难题。
为了应对上述问题,技术团队先引入 “老师分身” 模型,让每个 AI 老师在单个阵容上训练至精通,再引入一个 AI 学生模仿学习所有的 AI 老师,最终让 “绝悟” 掌握了所有英雄的所有技能,成为一代宗师。 同时,团队还制定了长期目标,就是要让 “绝悟” 学会所有英雄的技能,且每个英雄都能达到顶尖水平。为此他们在技术上做了三项重点突破: 首先团队构建了一个最佳神经网络模型,让模型适配 MOBA 类任务、表达能力强、还能对英雄操作精细建模。模型综合了大量 AI 方法的优势,具体而言: 1. 在时序信息上引入长短时记忆网络(LSTM)优化部分可观测问题; 2. 在图像信息上选择卷积神经网络(CNN)编码空间特征; 3. 用注意力(Attention)方法强化目标选择; 4. 用动作过滤(Action Mask)方法提升探索效率; 5. 用分层动作设计加快训练速度; 6. 用多头值估计(Multi-Head Value)方法降低估计方差等。
图 | 网络架构 其次,团队借用围棋的思路,采用了 CSPL(Curriculum Self-Play Learning,课程自对弈学习),能够有效拓宽英雄池,让 “绝悟 “掌握所有英雄技能。 CSPL 是一种让 AI 从易到难的渐进式学习方法,具体有以下几个步骤: 1.“老师分身” 模型:挑选多组覆盖全部英雄池的阵容,在小模型下用强化学习训练,得到多组 “老师分身” 模型; 2.迁移模型:蒸馏,把第一步得到的多个模型的能力迁移到同一个大模型中; 3.随机阵容的强化训练:在蒸馏后的大模型里,随机挑选阵容继续强化训练和微调。通过多种传统和新颖技术方法的结合,实现了在大的英雄池训练,同时还能不断扩展的目标。
图 | CSPL 流程图。任务由易到难,模型从简单到复杂,知识逐层深入。 实验结果表明,使用 CSPL 方法扩展英雄池有明显优势,能够在非常有效地减少训练时间,同时保持良好的效果。
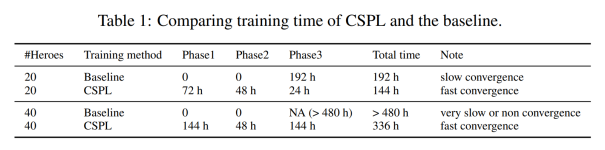
图 | 实验结果 最后,团队还搭建了大规模训练平台 —— 腾讯开悟(aiarena.tencent.com)。该平台依托项目积累的算法经验、脱敏数据及腾讯云的算力资源,为训练所需的大规模运算保驾护航。目前,开悟平台于今年 8 月对 18 所高校开放,未来希望为更多科研人员提供技术与资源支持,深化课题研究。 排兵布阵,致人而不致于人
作为团队的大脑,教练在整个比赛中都起到了非常重要的作用。无论是在 BP 环节(禁选英雄)的选择,还是阵容的压制上面,稍有不慎就为给对手带来先天优势,造成 “致于人” 的局面。因此,“绝悟” 要取得胜利就必须找到一个能排兵布阵的 AI 教练。
目前,简单的做法是选择贪心策略,即选择当前胜率最高的英雄。这针对单个英雄而言或许可以,但王者荣耀有上百个英雄,任意英雄间都有或促进或克制的关系,只按胜率选择很容易被对手针对,更需要综合考虑敌我双方、已选和未选英雄的相关信息,最大化己方优势,最小化敌方优势。 受到围棋 AI 算法(Alpha Go)的启发,团队使用蒙特卡洛树搜索(MCTS)和神经网络结合的自动 BP 模型来解决这一问题。 MCTS 方法包括了选择、扩张、模拟和反向传播四个步骤,会不断迭代搜索,估算出可选英雄的长期价值。在这其中模拟部分最耗时,所以团队用估值神经网络替代该环节,加快了搜索速度,这样能够又快又准地选出具备最大长期价值的英雄。要提到的是,围棋等棋牌类游戏结束就能确定胜负,但 BP 结束只到确定阵容,还未对战,所以胜负未分。因此团队利用绝悟自对弈产生的超过 3000 万条对局数据训练出一个阵容胜率预测器,用来预测阵容的胜率。胜率预测器得到的阵容胜率又被用来监督训练估值网络。
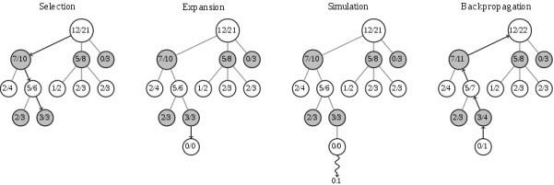
图 | 蒙特卡洛搜索树 除了常见的单轮 BP,AI 教练还学会了王者荣耀 KPL 赛场上常见的多轮 BP 赛制,该模式下不能选重复英雄,对选人策略要求更高。为此,团队引入多轮长周期判定机制,在 BO3/BO5 赛制中可以全局统筹、综合判断,做出最优 BP 选择。训练后的 BP 模型在对阵基于贪心策略的基准方法时,能达到近 70% 胜率,对阵按位置随机阵容的胜率更接近 90%。 至此,强兵加军师的组合,使得 “绝悟” 成为了不折不扣的一代宗师。
除了上述的 RL(强化学习)算法外,团队还开发了 SL(监督学习)算法,针对大局观和微操策略同时建模,让绝悟同时拥有优秀的长期规划和即时操作,达到了非职业玩家的顶尖水平。
相关技术成果曾在 2018 年 12 月公开亮相对战人类玩家。其实,团队对于监督学习的研发一直在持续进行中。今年 11 月 14 日起开放的绝悟第 1 到 19 级,就有多个关卡由监督学习训练而成。
从研究方法上看,监督学习对于 AI 智能体的研发有很高的价值。 1.“更像人”:通过挖掘人类数据预测未来的监督学习是通常是研发游戏 AI 的第一步,并在众多视频游戏上取得较好效果。比如在明星大乱斗等复杂电子游戏中,纯监督学习能也学到达到人类高手玩家水平的 AI 智能体。 2. 多种深度学习的结合:监督学习能复用为强化学习的策略网络,如 AlphaGo 就是监督学习结合强化学习。 3. 节约训练时间:同时适当地插入监督学习可以缩短强化学习探索时间,比如 DeepMind 的星际争霸 AI AlphaStar 就用监督学习做强化训练的隐含状态。
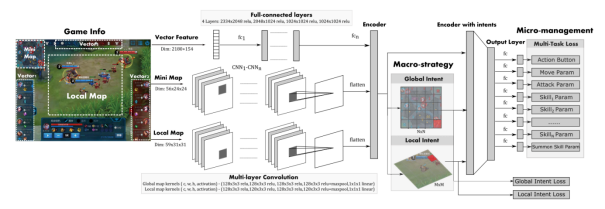
图 | 网络架构 应用上述诸多优点,“绝悟 “可以实现一系列效果:训练快,在 16 张 GPU 卡上只需几天,而强化学习则需几个月;拓展能力强,能完成全英雄池训练;使用真实玩家的脱敏数据,配合有效采样,产出的 AI 行为上会更接近人类。 随着 AI 在游戏世界的发展,它们在数据的记忆和处理方面的优势能够进一步体现出来。那么如何利用 AI 来强化自己的队伍,或许是当下游戏教练需要思索的问题。 -End-
原文标题:登上NeurIPS 2020:腾讯AI联合王者荣耀推出“绝悟”完全体
文章出处:【微信公众号:DeepTech深科技】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
腾讯叮当联手Alavening发布智能闹钟“阿拉的神奇小闹闹”2018-08-04 0
-
用腾讯优图AI视觉模组做一个驾驶疲劳监测仪2019-08-16 0
-
【推荐体验】腾讯云自然语言处理2019-10-09 0
-
先暏为快:腾讯将会推出3DQQ秀[组图]2006-03-07 647
-
攻克食管癌早筛有望了!腾讯发布腾讯觅影AI2017-08-10 1274
-
AI+农业_腾讯AI生态养鹅?2018-04-08 2768
-
腾讯正式宣布推出首款医疗AI引擎——腾讯睿知2018-05-14 2875
-
腾讯正式推出首款医疗AI引擎2018-05-15 4134
-
腾讯正式发布AI开放平台AI.QQ.COM2018-09-20 5918
-
腾讯携手创维推出AI智能语音投影P2,售价1999元2019-03-14 3115
-
腾讯云推出小微AI助手 助力各行业的智慧化转型2019-05-23 750
-
奥蒂玛将在Q3推出全新AI操作系统,实现AOI的完全自动化!2019-07-31 4998
-
腾讯云在北京举行大数据AI新品发布会2020-07-25 3526
-
中国联通携手腾讯推出“无障碍AI通话服务”,主要针对听障人士2020-10-09 16339
-
腾讯给全体员工每人一台价值16999元的华为折叠屏手机2020-10-12 2412
全部0条评论

快来发表一下你的评论吧 !
