

为什么使用trace-event解决系统还不能深度睡眠问题?
描述
最近遇到一个问题,系统不能睡眠到c7s, 只能睡眠到c3. (c-state不能到c7s, cpu的c-state, c0是运行态,其它状态都是idle态,睡眠的越深,c-state的值越大)

这时候第一感觉是不是系统很忙导致, 使用pert top看一下耗cpu的进程和热点函数:
1perf top -E 100 --stdio 》 perf-top.txt2 19.85% perf [。] __symbols__insert 3 7.68% perf [。] rb_next 4 4.60% libc-2.26.so [。] __strcmp_sse2_unaligned 5 4.20% libelf-0.168.so [。] gelf_getsym 6 3.92% perf [。] dso__load_sym 7 3.86% libc-2.26.so [。] _int_malloc 8 3.60% libc-2.26.so [。] __libc_calloc 9 3.30% libc-2.26.so [。] vfprintf 10 2.95% perf [。] rb_insert_color 11 2.61% [kernel] [k] prepare_exit_to_usermode 12 2.51% perf [。] machine__map_x86_64_entry_trampolines 13 2.31% perf [。] symbol__new 14 2.22% [kernel] [k] do_syscall_64 15 2.11% libc-2.26.so [。] __strlen_avx2
发现系统中只有perf工具本身比较耗cpu :(
然后就想到是不是系统中某个进程搞的鬼,不让cpu睡眠到c7s. 这时候使用trace event监控一下系统中sched_switch事件。 使用trace-cmd工具监控所有cpu上的sched_switch(进程切换)事件30秒:
#trace-cmd record -e sched:sched_switch -M -1 sleep 302CPU0 data recorded at offset=0x63e000 3 102400 bytes in size 4CPU1 data recorded at offset=0x657000 5 8192 bytes in size 6CPU2 data recorded at offset=0x659000 7 20480 bytes in size 8CPU3 data recorded at offset=0x65e000 9 20480 bytes in size
使用trace-cmd report 查看一下监控结果,但是查看这样的原始数据不够直观,没有某个进程被切换到的统计信息:
1#trace-cmd report2cpus=4 3 trace-cmd-19794 [001] 225127.464466: sched_switch: trace-cmd:19794 [120] S ==》 swapper/1:0 [120] 4 trace-cmd-19795 [003] 225127.464601: sched_switch: trace-cmd:19795 [120] S ==》 swapper/3:0 [120] 5 sleep-19796 [002] 225127.464792: sched_switch: sleep:19796 [120] S ==》 swapper/2:0 [120] 6 《idle》-0 [003] 225127.471948: sched_switch: swapper/3:0 [120] R ==》 rcu_sched:11 [120] 7 rcu_sched-11 [003] 225127.471950: sched_switch: rcu_sched:11 [120] W ==》 swapper/3:0 [120] 8 《idle》-0 [003] 225127.479959: sched_switch: swapper/3:0 [120] R ==》 rcu_sched:11 [120] 9 rcu_sched-11 [003] 225127.479960: sched_switch: rcu_sched:11 [120] W ==》 swapper/3:0 [120] 10 《idle》-0 [003] 225127.487959: sched_switch: swapper/3:0 [120] R ==》 rcu_sched:11 [120] 11 rcu_sched-11 [003] 225127.487961: sched_switch: rcu_sched:11 [120] W ==》 swapper/3:0 [120] 12 《idle》-0 [002] 225127.491959: sched_switch: swapper/2:0 [120] R ==》 kworker/2:2:19735 [120] 13 kworker/2:2-19735 [002] 225127.491972: sched_switch: kworker/2:2:19735 [120] W ==》 swapper/2:0 [120]。..
trace-cmd report 的结果使用正则表达式过滤一下,然后排序统计:
1trace-cmd report | grep -o ‘==》 [^ ]+:?’ | sort | uniq -c 2 3 ==》 irqbalance:1034 3 3 ==》 khugepaged:43 4 20 ==》 ksoftirqd/0:10 5 1 ==》 ksoftirqd/1:18 6 18 ==》 ksoftirqd/3:30 7 1 ==》 kthreadd:19798 8 1 ==》 kthreadd:2 9 4 ==》 kworker/0:0:19785 10 1 ==》 kworker/0:1:19736 11 5 ==》 kworker/0:1:19798 12 5 ==》 kworker/0:1H:364 13 53 ==》 kworker/0:2:19614 14 19 ==》 kworker/1:1:7665 15 30 ==》 tuned:19498 19 。..
发现可疑线程tuned,30秒内被切换到运行了30次,其它线程都是常规线程。
此时查看一下系统中是否开启了tuned服务:
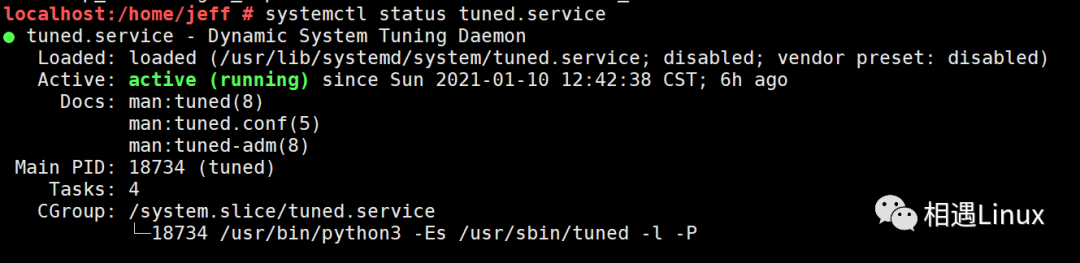
果真是系统开启了tuned服务,然后拉起了名字为tuned的线程。
查看一下tuned服务的配置文件:
localhost:/home/jeff # tuned-adm active Current active profile: sap-hana localhost:/home/jeff # cat /usr/lib/tuned/sap-hana/tuned.conf [main] summary=Optimize for SAP NetWeaver, SAP HANA and HANA based products [cpu] force_latency = 70
发现关于cpu这一项,设置强制延迟时间为70秒 force_latency = 70 ,这个是为了优化HANA数据库。
到底force_latency怎样起作用,经过一顿搜索,发现这个值是被设置进了/dev/cpu_dma_latency
使用lsof /dev/cpu_dma_latency, 发现tuned线程确实是在操作这个文件
#lsof /dev/cpu_dma_latency COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME tuned 18734 root 9w CHR 10,60 0t0 11400 /dev/cpu_dma_latency
而且Linux内核文档也说明了/dev/cpu_dma_latency文件,如果要对它进行写操作,要open之后写数据之后不close,如果释放掉了文件描述符它就又会恢复到默认值,这也印证了上面lsof /dev/cpu_dma_latency是有输出结果的。
https://github.com/torvalds/linux/blob/v5.8/Documentation/trace/coresight/coresight-cpu-debug.rst As specified in the PM QoS documentation the requested parameter will stay in effect until the file descriptor is released. For example: # exec 3《》 /dev/cpu_dma_latency; echo 0 》&3 。.. Do some work.。. 。.. # exec 3《》-
查看一下/dev/cpu_dma_latency文件的内容,确实是70,也就是(force_latency = 70)
localhost:/home/jeff # cat /dev/cpu_dma_latency | hexdump -Cv 00000000 46 00 00 00 |F.。.| localhost:/home/jeff # echo $((0x46)) 70
此时查看一下系统中cpu各个睡眠态的描述和延迟时间值:
# cd /sys/devices/system/cpu/cpu0/cpuidle/ # for state in * ; do echo -e “STATE: $state DESC: $(cat $state/desc) NAME: $(cat $state/name) LATENCY: $(cat $state/latency) RESIDENCY: $(cat $state/residency)” done
发现C3态的延迟时间是33微秒,C4的延时时间是133微秒,所以(force_latency = 70) ,
系统就只能睡眠到C3了 。(延迟时间就是从此睡眠态唤醒到运行态的时间)
STATE: state0 DESC: CPUIDLE CORE POLL IDLE NAME: POLL LATENCY: 0 RESIDENCY: 0 STATE: state1 DESC: MWAIT 0x00 NAME: C1 LATENCY: 2 RESIDENCY: 2 STATE: state2 DESC: MWAIT 0x01 NAME: C1E LATENCY: 10 RESIDENCY: 20 STATE: state3 DESC: MWAIT 0x10 NAME: C3 LATENCY: 33 RESIDENCY: 100 STATE: state4 DESC: MWAIT 0x20 NAME: C6 LATENCY: 133 RESIDENCY: 400 STATE: state5 DESC: MWAIT 0x32 NAME: C7s LATENCY: 166 RESIDENCY: 500
此时关闭tuned 服务, 再查看一下 /dev/cpu_dma_latency的值,变成了默认的2000秒
localhost:/home/jeff # tuned-adm off localhost:/home/jeff # cat /dev/cpu_dma_latency | hexdump -Cv 00000000 00 94 35 77 |。.5w| localhost:/home/jeff # echo $((0x77359400)) 2000000000
然后验证一下,此时系统可以睡眠到C7s了,此问题得到解决 :)

解决此问题,主要用到了Linux内核本身提供的trace-event.
所以任何一个功能都不能小看,内核就是这样,一般看上去很无聊的功能,被一些工程师用很认真的态度打磨出来之后,潜力还是非常大的:)
原文标题:使用trace-event解决系统不能深度睡眠的问题
文章出处:【微信公众号:Linuxer】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
在睡眠/深度睡眠模式下通过调试器TRACE32读取来自ITCM/DTCM地址的数据,会出现问题吗?2024-01-18 0
-
PSoC CAN不会从深度睡眠中醒来是怎么回事?2024-01-31 0
-
CC3200深度睡眠被系统任务切换中断唤醒,怎么解决?2016-04-27 0
-
在进入深度睡眠之前需要检查BLE堆栈吗2018-10-12 0
-
深度睡眠时的低电流有什么影响?2019-09-09 0
-
伪随机序列(prs)和睡眠/休眠/深度睡眠该如何建立?2019-09-25 0
-
冲突的深度睡眠信息2019-10-08 0
-
请问Z-stack 加密后无法进入深度睡眠?2020-08-05 0
-
怎样通过trace生成系统cpu的loading图2021-06-28 0
-
GD32进入深度睡眠后通过外部中断唤醒发现系统时钟变慢的原因2022-01-26 0
-
LM3S系列单片机睡眠与深度睡眠应用笔记2010-04-03 626
-
深度睡眠模式操作技术笔记2010-04-03 416
-
Cortex-M0深度睡眠唤醒测试2010-11-17 1754
-
GD32低功耗:深度睡眠唤醒系统时钟变慢问题2021-12-02 1995
-
AN010 从深度睡眠模式2唤醒并恢复2023-02-27 160
全部0条评论

快来发表一下你的评论吧 !
