

将对话中的情感分类任务建模为序列标注 并对情感一致性进行建模
描述
本文是平安科技发表在ACL2020上的一篇论文,思路比较新颖,它将ERC任务看做序列标注任务,并对情感一致性进行建模。
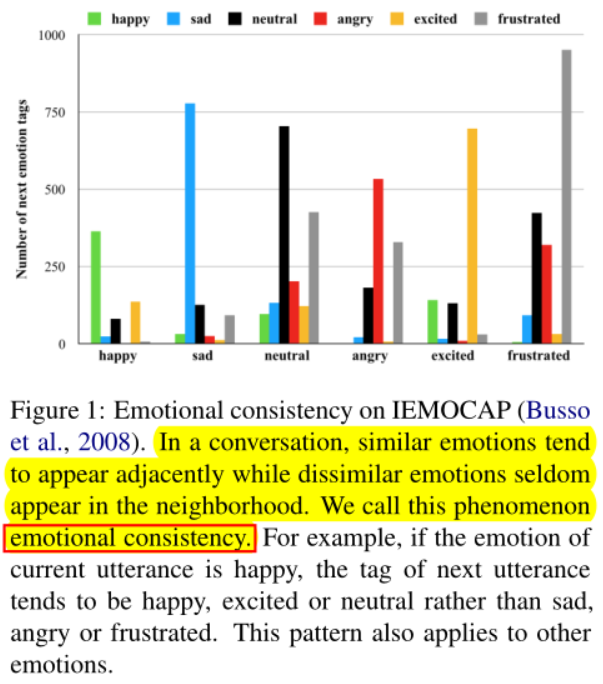
之前解决ERC的思路是利用上下文的话语特征预测对话中单个话语的情感标签,但是这样做忽略了情感标签之间的固有关系。本在本文中,作者提出了一种将情感分类看作序列标注的模型。对于给定的会话,我们考虑附近的情感标签之间的关系,而不是独立地预测话语的情感标签,并一次性为整个会话选择全局最佳的标签序列。**情感一致性(emotional consistency)**就是指说话者下一句话的情感与这一句话的情感呈现出一致性。
本文的贡献
第一次将ERC任务建模为序列标记,并用CRF建模会话中的情感一致性。CRF层利用上文和下文的情感标签来联合解码整个对话的最佳标签序列。
应用多层Transformer编码器来增强基于LSTM的全局上下文编码器,这是因为在远距离上下文特征抽取方面,Transformer的抽取能力远强于LSTM。
本文在三个对话数据集上做了实验,实验表明对情感一致性和远程上下文依赖关系进行建模可以提高情感分类的性能。
模型
作者提出了Contextualized Emotion Sequence Tagging(CESTa)模型
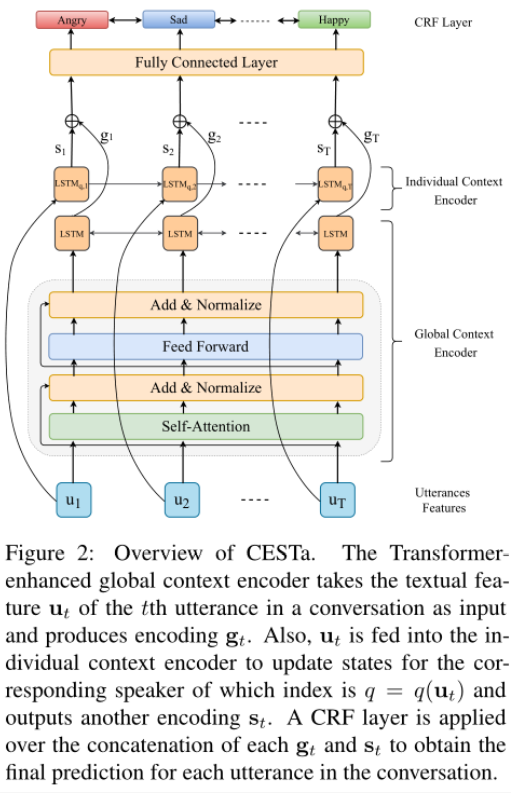
话语特征提取(Utterances Features)
对于对话中的第t个话语,其句子表示**ut**由单层CNN提取并馈入全局上下文编码器和个人上下文编码器。
全局上下文编码器(Global Context Encoder)
说话者之间的依赖关系对于对话中的情感动态至关重要,比如当前说话者的情绪可以被对方的话语改变,因此必须考虑上下文信息。全局上下文编码器对所有句子编码,使用的是多层Transformer + BiLSTM,意在捕捉长距离上下文信息。

个人上下文编码器(Individual Context Encoder)
个人上下文编码器会跟踪每个说话者的自我依赖关系,从而反映出说话者在谈话过程中对自己的情感影响。在情感惯性的影响下,说话者倾向于保持稳定的情绪状态,直到对方导致变化。
本层采用的是LSTM作为个人上下文编码器,在每个时间步输出所有说话者的状态。

CRF层
全局上下文编码器的输出gt和个人上下文编码器的输出st做一个拼接操作经过全连接层送入CRF层产生最终的预测,并选择选择最大分数的序列作为输出。

实验
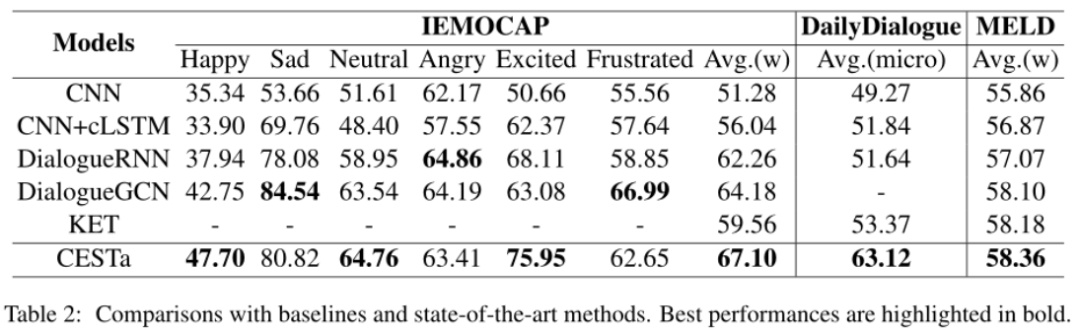
作者在三个对话数据集上开展了实验

与baseline相比,本文的模型在三个数据集上均取得了SOTA结果
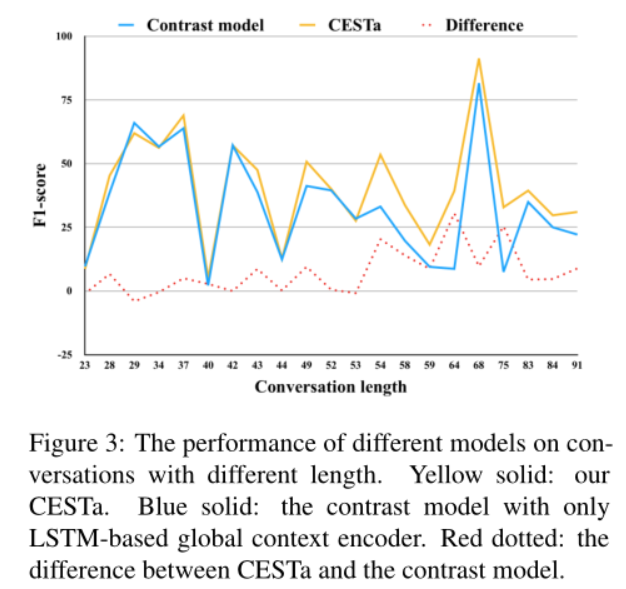
研究Transformer Enhancing在不同长度对话上的表现
作者在IEMOCAP数据集上对比了CESTa模型与去掉Transformer的模型变体做了对比,从下图可以看出,当数据集中话语长度超过54时,两者之间的差距变大,体现出了Transformer在捕捉长距离上下文特征的能力。
情感一致性分析
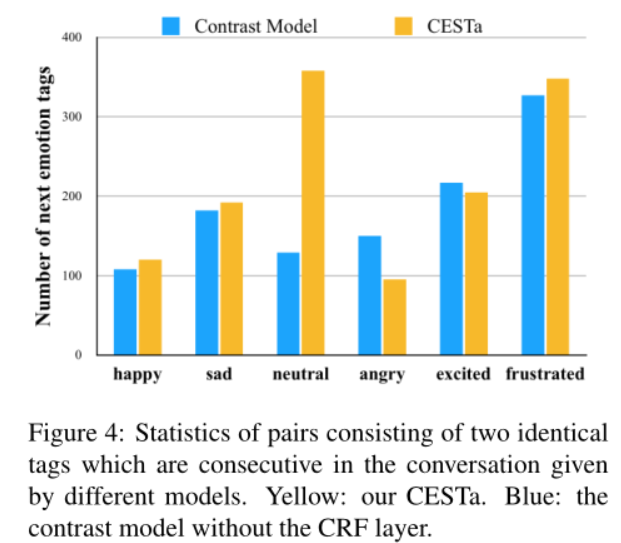
作者在IEMOCAP数据集上检验了情感一致性,比较了两个模型,一个是带有CRF层的CESTa模型,另一个是使用softmax层而不是CRF进行分类的对比模型,从下图可以看出CESTa模型较好地学习了情感一致性。
责任编辑:xj
原文标题:【ACL2020】CESTa, 将对话中的情感分类任务建模为序列标注任务
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
-
对申请CCC认证的产品进行一致性检查时检查什么?2016-10-19 0
-
一致性测试2017-07-14 0
-
c6678cache一致性2018-06-24 0
-
CAN一致性测试—容错性测试2018-11-22 0
-
基于Keras的mini_XCEPTION训练情感分类模型hdf5并保存到指定文件夹下2018-12-26 0
-
pyhanlp文本分类与情感分析2019-02-20 0
-
LTE基站一致性测试的类别2019-06-06 0
-
MIPI一致性测试2019-09-26 0
-
什么是霍尔元件的一致性2020-10-12 0
-
为什么需要进行WiMAX协议一致性测试?2021-04-15 0
-
顺序一致性和TSO一致性分别是什么?SC和TSO到底哪个好?2022-07-19 0
-
基于LDA和微博用户关系的主题情感模型2018-01-02 1251
-
如何使用词典和弱标注信息进行电影的评论情感分析2018-11-27 1610
-
情感分析常用的知识有哪些呢?2021-04-15 3101
-
图模型在方面级情感分析任务中的应用2022-11-24 1383
全部0条评论

快来发表一下你的评论吧 !
