

利用机器学习识别加密项目风险
电子说
描述
加密货币是一种存在于数字世界的交易媒介(另一种支付形式),依靠加密技术使交易安全。加密货币背后的技术允许用户直接向他人发送货币,而不需要通过第三方,如银行。为了进行这些交易,用户需要设置一个数字钱包,而不需要提供身份证号码或信用评分等个人细节,因此可以让用户伪匿名。
对于普通的加密货币用户来说,这种匿名性可以让他们放心,因为他们的个人信息或交易数据不会被黑客窃取。然而,这种交易匿名性的提高,也容易被犯罪分子滥用,进行洗钱、恐怖融资等非法活动。这种非法活动给区块链钱包用户以及加密货币实体都造成了巨大的损失。虽然金融行动特别工作组(FATF)等监管机构已经在这些实体的监管中引入了标准化的指导方针,但由于每天都有大量的加密货币实体和交易发生,监控加密货币空间是一项具有挑战性的任务。
解决方案
因此,人们有兴趣利用开源信息,例如新闻网站或社交媒体平台,来识别可能的安全漏洞或非法活动。在与Lynx Analytics的合作中,我们(来自新加坡国立大学的一个学生团队)已经致力于开发一个自动工具,以刮取开源信息,预测每篇新闻文章的风险分数,并标记出风险文章。这个工具将被整合到Cylynx平台(https://www.cylynx.io/)中,这是Lynx Analytics开发的一个工具,用于帮助监管机构通过使用各种信息源监控区块链活动。
开源信息的数据获取
我们确定了3类开源数据,这些数据可以提供有价值的信息,帮助检测加密货币领域的可疑活动。这些类别是:
传统的新闻网站,如谷歌新闻,它将报告重大的黑客事件。
加密货币专用新闻网站,如Cryptonews和Cointelegraph,它们更有可能报道小型实体和小型安全事件的新闻。
社交媒体网站,如Twitter和Reddit,在官方发布黑客新闻之前,加密货币所有者可能会在那里发布有关黑客的消息。
检索文章和社交媒体帖子的内容,然后建立情绪分析模型。该模型为文章中提到的实体分配了一个风险活动的概率。
情绪分析模型
我们尝试了四种不同的自然语言处理工具进行情绪分析,即VADER、Word2Vec、fastText和BERT模型。在通过选定的关键指标(召回率、精度和F1)对这些模型进行评估后,RoBERTa模型(BERT的一个变种)表现最佳,被选为最终模型。
RoBERTa模型对新闻文章(标题和摘录)或社交媒体帖子的文本进行处理,并为特定文本分配一个风险分数。由于该文本在数据收集过程中已经被标记为实体,我们现在已经有了加密实体的相关风险指标。在后期,我们将多个文本的风险分数结合起来,给出一个实体的整体风险分数。
RoBERTa原本是一个使用神经网络结构建立的情感分析模型,我们将最后一层与我们标注的风险分数进行映射,以适应风险评分的环境。为了提高模型在未来文本数据上的通用性,我们进行了几种文本处理方法,即替换实体、删除url和替换hash。然后我们使用这个表现最好的模型进行风险评分。
风险评分
现在,每篇文章都有一个相关的来源(news/reddit/twitter),一个风险概率和一个计数,指的是文章被转发、分享或转发的次数。为了将这些风险概率转换为加密货币实体的单一风险得分,我们首先将文章的概率值缩放到0到100的范围内,并获得每个来源的加权平均值,结合文章的风险得分和计数。加权平均数用于对计数较高的文章给予更大的重视,因为份额数量很可能表明文章的相关性或重要性。
在计算出各来源的风险得分后,我们对各来源的风险得分进行加权求和,得到综合得分,公式如下:
传统的新闻来源被赋予了更高的权重,因为这些来源更有可能报道重大的安全漏洞(相对于单个用户的黑客事件)。
该解决方案的有效性
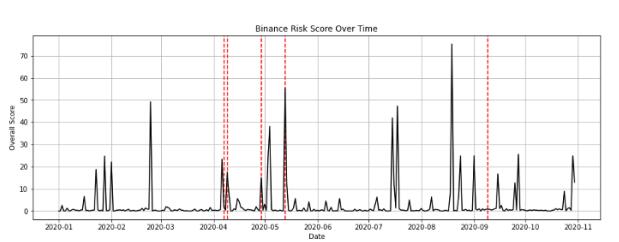
我们在2020年1月1日至2020年10月30日的174个加密货币实体的名单上测试了我们的解决方案,并将结果与该时间段内的已知黑客案例进行了比较。我们发现,我们的风险评分方法表现相当出色,在37个已知的黑客案例中识别了32个。我们还分析了我们的解决方案对单个实体的有效性。下图显示了Binance从2020年1月1日至2020年10月30日的风险评分。虚线红线代表已知的黑客案例。从图中我们观察到,我们的解决方案报告了5个已知黑客中的4个黑客的风险得分增加。也有几个峰值与已知黑客案例不一致。然而,这并不构成一个主要问题,因为对我们的模型来说,更重要的是识别尽可能多的黑客,减少未识别的黑客数量。
有趣的发现
在风险评分过程中,我们注意到,与规模较小的实体相比,规模较大的实体的风险评分往往有较大比例的假阳性记录。这是因为大型实体被谈论得更多,因此会有更多的负面帖子和虚假谣言,从而导致更高的不准确率。
另一个值得强调的有趣趋势是,围绕着黑客攻击通常有几个明显的高峰。这是由于不同数据源的反应时间不同。社交媒体网站Twitter和Reddit通常是第一个看到高风险事件发生时的高峰,因为用户会发帖提出他们观察到的异常情况,比如一个实体的网站在没有事先通知用户的情况下宕机。官方消息一般是在官方声明之后,稍后才会发布。
局限性
我们发现,我们的解决方案有两个潜在的局限性,首先是需要不断地维护收集器。网站设计可能会随着时间的推移而改变,这些网站的刮擦器需要更新,以确保相关信息仍能被检索到,从而达到风险评分的目的。
第二个限制是,验证一篇文章是否已被正确地标记为加密货币实体是具有挑战性的。例如,一篇报道Bancor可疑活动的文章可能也会因为一个不相关的事件提到Binance。我们的解决方案会错误地将新闻标记为两个实体,并将Binance标记为风险,即使它不是文本中的关键主题。然而,这并不是一个主要的限制,因为我们只使用新闻文章的标题和摘录来进行风险评分,这通常只包含文章的关键信息。
结语
我们的项目让监管机构可以轻松挖掘开源信息,更好地识别加密货币领域发生的风险事件。我们提供了一个分析文章并预测风险分数的语言模型,以及根据实体和来源信息汇总这些分数的方法。这些方法都被编织成一个可以端到端运行的自动化流水线。将该项目整合到Cylynx平台中,将对其现有功能进行补充,并为监管机构识别高风险加密货币实体提供巨大的帮助。
责任编辑:YYX
- 相关推荐
- 加密货币
-
#硬声创作季 iPhone面容识别加密、3台移高移低问题看我如何修复它#手机维修深海狂鲨 2022-11-02
-
基于概率影响图的IT项目风险评估方法研究2010-04-24 0
-
北京盛讯美恒科技加密狗共享器/虚拟化识别加密狗/集中管理2014-03-25 0
-
u***server虚拟化识别加密狗解决方案2014-03-27 0
-
虚拟化方案识别加密狗技术介绍2014-08-08 0
-
基于贝叶斯网络的软件项目风险评估模型2009-04-10 640
-
建设工程项目业主风险防范2009-12-28 687
-
基于投影寻踪方法的工程项目风险评估2017-12-20 550
-
PFMEA技术能够有效降低项目管理的风险,保证项目顺利的进行2017-12-25 7364
-
用机器学习算法来识别加密货币骗局2018-03-21 3592
-
首款基于FPGA的原创深度学习语音识别加速解决方案面世,深鉴引领FPGA加速云市场2018-07-27 1738
-
加密货币交易的深度学习2018-11-12 2378
-
机器学习准确预测发病风险2019-07-19 3298
-
如何确保AI和机器学习项目的风险和安全性?2020-12-04 2288
-
避免隐藏的隔离成本设计-如何管理项目风险与下一代解决方案2023-11-22 60
全部0条评论

快来发表一下你的评论吧 !
