

如何通过蒸馏来使小模型具有更好的性能
描述
之前我们讨论了『模型压缩与蒸馏!BERT的忒修斯船』,算是一个开篇。本文继续讨论关于模型蒸馏(Distilling Knowledge)及关于BERT模型的知识蒸馏,分享针对具体任务时可行的简洁方案,同时在新的视角下探讨了知识蒸馏有效的一些原因,并通过实验进行验证。
模型蒸馏的最重要的一个特点就是降低资源使用以及加速模型推理速度,而小模型往往性能较低,本文总结如何通过蒸馏来使小模型具有更好的性能。
Distilling the Knowledge in a Neural Network
这篇是2015年Hinton发表的,也是我看到的最早提出Knowledge Distillation的论文[1]。
在这篇论文中,Hinton指出one-hot 的label只指示了true label 的信息,但是没有给出negative label 之间、negative 与 true label之间的相对关系,比如:
现在的任务是给定一个词(比如:苹果),然后判断词对应的类别(电视/手机/水果/汽车),假如现在我们有两个样本:(苹果,[0,0,1,0])和(小米,[0,1,0,0])而one-hot 形式的label并不能告诉我们,苹果中 label是水果的概率高出label是拖拉机的概率,稍低于是手机的概率,而小米中label是电视的概率稍低于是手机的概率,但是同时要高于是汽车和水果的概率,这些相对关系在one-hot 形式的label中是无法得到的。
而这些信息非常重要,有了这些信息,我们可以更容易的学习任务。于是提出了Teacher-Student模式,即用一个大的复杂的模型(也可以是ensemble后的)来先学习,然后得到label的相对关系(logits),然后将学习到的知识迁移到一个小模型(Student)。
Distilling
具体迁移过程是Student 在进行training 时,除了学习ground truth 外,还需要学习label 的probability(softmax output),但是不是直接学习softmax output,而是学习soften labels,所谓soften labels 即经过Temperature 平滑后的 probability,具体形式:
其中T 越大,对应的probability 越平滑,如下图所示。而平滑probability 可以看作是对soften label的一种正则化手段。
更直观的实验请查阅Knowledge Distillation From Scratch[2]
Distill BERT
看到的第一篇针对 BERT 模型做蒸馏的是Distilling Task-Specific Knowledge from BERT into Simple Neural Networks[3]。
在这篇论文中,作者延续Hinton 的思路在BERT 上做实验,首先用BERT-12 做Teacher,然后用一个单层Bi-LSTM 做Student,loss 上除了ground truth 外,也选择了使用teacher 的logits,包括Temperature 平滑后的soften labels 的CrossEntropy和 logits 之间的MSE,最后实验验证MSE效果优于CE。
此外,由于是从头开始训练Student,所以只用任务相关数据会严重样本不足,所以作者提出了三种NLP的任务无关的data augment策略:
mask:随机mask一部分token作为新样本,让teacher去生成对应logits ;
根据POS标签去替换,得到 ”What do pigs eat?" -> " How do pigs ear?"
n-gram采样:随机选取n-gram,n取[1-5],丢弃其余部分。
在Distilling the Knowledge in a Neural Network[4]中曾指出 logits 之间的CrossEntropy是可以看作是MSE 的近似版本,不过这里作者的结论是MSE 更好。
此外,由于Hinton 实验时是巨大数据量,所以不存在样本不足的情况,而普通实验时都会遇到迁移时训练样本不足,需要做数据增强的问题。
TinyBERT
TinyBERT 出自TinyBERT: Distilling BERT for Natural Language Understanding[5]。
由于Transformer 结构在NLP 任务中的强大能力,作者选择用与BERT 同结构的方式做Student。此外,为了提高KD后模型性能,做了更细致的工作:
Student选择一个更窄更浅的transformer;
将KD也分为两个阶段:pre-train 和 fine-tuning,并且在两个阶段上都进行KD;
使用了更多的loss:Embedding之间的MSE,Attention Matrix中的logits之间的MSE,Hidden state之间的MSE以及最后的分类层的CE;
为了提高下游任务fine-tuning后的性能,使用了近义词替换的策略进行数据增强。
优点
6层transformer基本达到了bert-12的性能,并且hidden size更小,实际是比bert-6更小的;
因为有pre-train KD,所以可以拿来当bert 一样直接在下游fine-tuning。
缺点
由于hidden size的不同,所以为了进行MSE,需要用一个参数矩阵W 来调节,这个参数只在训练时使用,训练完后丢弃,这个矩阵没有任何约束,觉得不优雅;
其次,student model的每一层都需要去学习teacher model的对应的block的输出,如何对不同的层如何设计更好的权重也是一个费力的事;
虽然student的结构也是transformer,但是由于hidden size 不同,没法使用teacher的预训练结果,但是我觉得这里其实可以用降维的方式用teacher的预训练结果,可能不需要pretraining的阶段了也说不定。
DistilBERT
DistilBERT 出自DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter[6]。
论文中作者通过调查发现BERT 中的hidden size 对计算效率的改变比hidden layer nums 的影响小,说白了就是「让模型变矮比让模型变瘦效率更高」,所以作者使用了一个更矮的BERT来做Student 来迁移BERT 中的知识。
由于DistilBERT 是一个与BERT 同结构只是层数更小,所以DistilBERT 可以用BERT 的预训练的权重进行初始化。此外,DistilBERT 是一个与任务无关的模型,即与BERT 一样,可以对很多下游任务进行fine-tuning。
由于DistilBERT 与 BERT 的前几层一致,所以loss 的选择上就更多一些,作者选择了triple loss:MLM loss + embedding cosin loss + soften labels cross entropy loss
优点
DistilBERT 做到了与BERT 一样,完全与任务无关,不需要添加额外的Distillation 阶段(添加后结果会更好)。
MobileBERT
MobileBERT 出自MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices[7]。
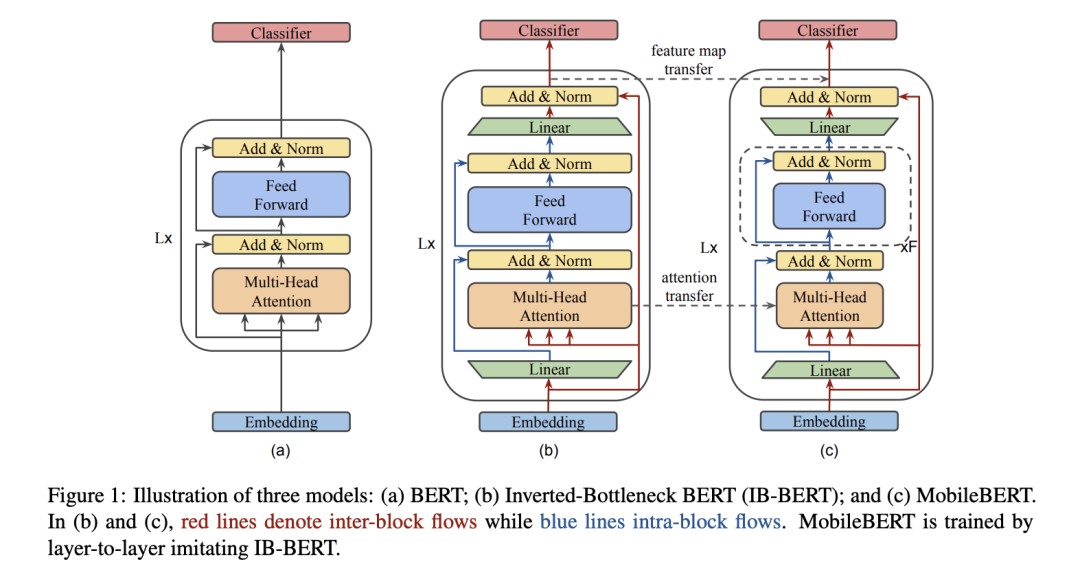
作者同样采用一个transformer 作为基本结构,但作者认为深度很重要,宽度较小对模型损坏较小,所以整体架构是保持模型深度不变,通过一个矩阵来改变feature size,即bottleneck,再通过在block的前后插入两个bottleneck,来scale feature size。
由于MobileBERT太窄太深,所以不好训练,作者提出新的方式,通过一个同深但是更宽的同架构的模型来训练 作为teacher,然后用MobileBERT迁移。
loss 设计上主要包括三部分:feature map之间的MSE,Attention logits之间的KL,以及pre-training MLM + pre-training-NSP + pre-training-KD
训练策略上,有三种方式:
将KD作为附加预训练的附加任务,即一起训练;
分层训练,每次训练一层,同时冻结之前的层;
分开训练,首先训练迁移,然后单独进行pre-training。
此外,为了提高推理速度,将gelu 替换为更快的 relu ,LayerNormalization 替换为 更简单的NoNorm,也做了量化的实验。
优点
首先mobileBERT容量更小,推理更快,与任务无关,可以当bert来直接在下游fine-tuning,而之前的KD大多数时候需要与任务绑定并使用数据增强,才能达到不错的性能;
论文实验非常详实,包括如何选择inter-block size, intra-block size, 不同训练策略如何影响等;
训练策略上,除了之前的一起训练完,实验了两种新的训练方式,而最终的一层一层的训练与skip connection 有异曲同工的作用:每层都学一小部分内容,从而降低学习的难度;
替换了gelu 和 LayerNormalization,进一步提速。
缺点
要训练一个IBBERT作为teacher,而这个模型容量与BERT-Large差不多,增加了训练难度.
总结
以上论文的迁移过程其实可以总结为两类:
soft label迁移,即主要迁移Teacher 模型最后分类层的logits 及相应的soft label;
feature迁移,即除了最后分类层外,还迁移Teacher 模型中的output/attention/embedding等特征。
Student 的选择上,除了自定义外,还可以选择跟Teacher 同结构,而为了降低参数量,可以选择将模型变矮/变窄/减小hidden size 等方式。
而为了蒸馏后的模型能更加的general,适应更多的task,就需要迁移更多的信息,设计上也越复杂。
想法
实际工作上,大多数时候我们都是需要一个task 来做模型,而以上论文中告诉我们,迁移的信息越多,Student 的性能越好。
而针对具体task ,我觉得比较简洁有效的一种方式是采用更矮的Teacher 来作为Student ,这样可以直接将Teacher 中的前几层的信息完全迁移过来,然后在object 上,加入迁移Teacher 在train data 上的logits ,这样就可以比较有效的进行蒸馏了。
除此之外,让我们换个角度看看为什么logits 能增强Student 模型的性能呢?除了迁移的角度外,其实logits 提供了label 更多的信息(不同类别的相对关系),而这个额外信息只要优于随机分布,就能对模型提供更多的约束信息,从而增强模型性能,即当前的模型可以看作是分别拟合ground truth 和 logits的两个模型的ensemble,只不过是两个模型共享参数。
上面我们提到只要logits 优于随机,对Student 模型来说就会有所提升,那logits 由谁产生的其实并不重要。所以,我们除了可以用Teacher 产生的logits来增强Student 模型外,我们还可以增强Teacher 模型,或者直接用Student 先学习一下,产生logits,再用Student 去迁移上次产生的logits。
想到这里,我不禁的有个大胆的想法:既然我可以一边生成logits, 一边学习logits,那我不是可以持续这个过程,直到模型完全拟合train data,生成的logits退化为one-hot,那此时的模型是不是能得到一个非常大的提升呢?
实验
实验的基本设置是用12层bert 作为Teacher model ,用3层bert 作为Student model 。soften labels 采用Temperature 平滑后的结果,此外,Student model 除了学习 soften labels 的外,也需要学习ground truth。
Teacher-to-Student
Teacher model 在train data 上训练,然后在train data 上生成对应的soften labels,Student model 学习ground truth 和 soften labels。
student-to-student
既然soften labels 是一种对labels 的一种平滑估计,那我们可以用任何方式去估计他,所以这里我们就用student 去做一个估计:student model 在train data 上进行训练,然后在train data 上生成对应的soften labels ,将 student model 利用bert 预训练结果重新初始化,然后去学习ground truth 和 soften labels.
normal-noise-training
既然是对labels 的一个估计,那假如给一个随机的估计,只要保证生成的logits 中true label 对应的值最大,就能对Student 模型进行一定程度的提升:直接在train label 上添加一个normal noise ,然后重新进行平滑后归一,作为soften labels让student model 去学习。
实验结果
从结果中可以看到:
优于随机的logits 对Student 模型有一定的提升,估计越准确,提升越高;
越大的模型性能越好;
迭代进行logits 的生成与训练不能进一步提高模型性能,原因主要是新的logits 分布相比之前的对模型的提升非常小,此外这个分布也比较容易拟合,所以无法进一步提升。
责任编辑:lq
-
基于网络性能的VoIP语音质量评价模型2010-04-24 0
-
请问这两种机械手模型哪种实验性能更好,可扩展性更好2015-07-15 0
-
如何通过软件指令来使程序复位?2019-09-19 0
-
Arm性能模型库发布说明产品修订版2023-08-11 0
-
如何提高YOLOv4模型的推理性能?2023-08-15 0
-
废镍镉电池的真空蒸馏回收技术简介2009-12-07 1270
-
深度学习:知识蒸馏的全过程2021-01-07 5666
-
若干蒸馏方法之间的细节以及差异2022-05-12 1173
-
关于快速知识蒸馏的视觉框架2022-08-31 682
-
如何度量知识蒸馏中不同数据增强方法的好坏?2023-02-25 567
-
蒸馏也能Step-by-Step:新方法让小模型也能媲美2000倍体量大模型2023-05-15 437
-
基于一步步蒸馏(Distilling step-by-step)机制2023-05-16 748
-
如何将ChatGPT的能力蒸馏到另一个大模型2023-06-12 602
-
盘古大模型和文心一言哪个更好?2023-08-31 4065
-
任意模型都能蒸馏!华为诺亚提出异构模型的知识蒸馏方法2023-11-01 564
全部0条评论

快来发表一下你的评论吧 !
