

如何透过数字直剖本质评估AI芯片的真实性能?
描述
特斯拉 Hardware 3.0 的效率之谜
特斯拉在其推出的 Hardware 3.0 自动驾驶平台中,采用自研芯片替代了Nvidia Drive PX2,其理论算力直线提升了 3 倍,而以 MAPS 方式来评估,其真实 AI 性能更是惊人的提升了 21 倍。具体而言,Hardware 2.0 时每秒只能处理 110 帧图像,而现在则高达 2300 帧。
那么,Hardware 的效率提升应该如何认识呢?在“算力至上”的今天,如何透过数字直剖本质评估 AI 芯片的真实性能?
算力攀升,为什么却看不到实用性?
随着芯片制程技术的演进,摩尔定律的发展却逐渐进入瓶颈期,这与当下计算 AI 计算需求量爆发式的增长显得格格不入。追求纯算力突破并不可持续,同时算力也并不代表汽车智能芯片“真实性能”,芯片计算效率也同样需要关注。于是,软硬结合、算法加持的 AI 芯片接过了跑赢新场景的接力棒。
当前,行业普遍以“TOPS”为单位来评估AI的理论峰值算力。尽管在目前主流的AI芯片性能基准测试( MLPerf )下很多顶级厂商频繁刷新榜单记录,但在实际场景下的算力有效利用率却差强人意。
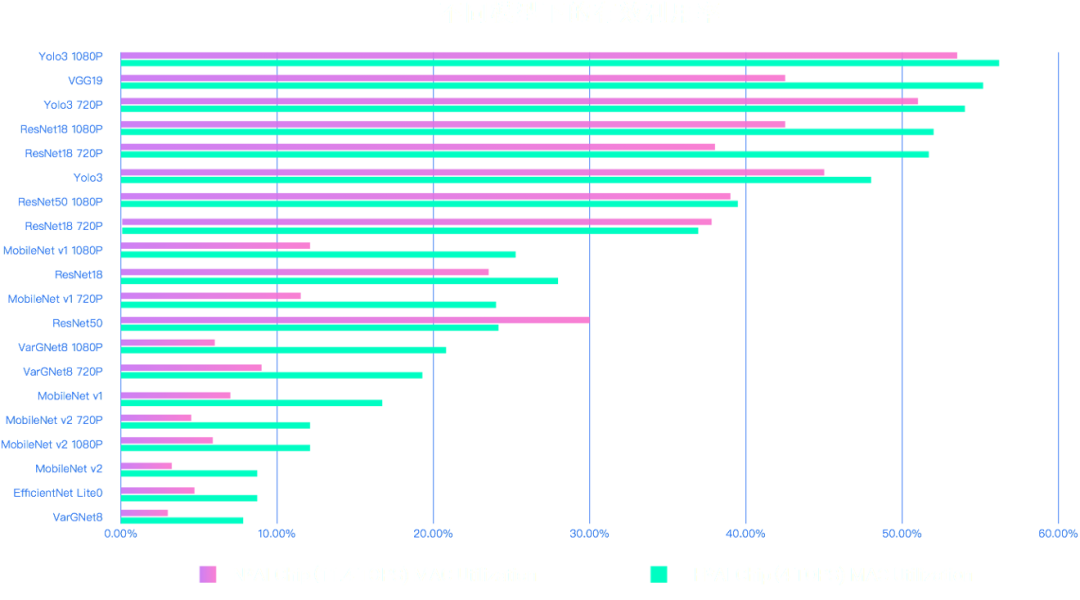
人们逐渐认识到,AI 芯片理论峰值算力并不一定能在实际运行中完全释放。例如,一款拥有理论峰值算力为 16 TOPS 的芯片,在计算不同模型时甚至会有接近 80% 的差异。此外,在卷积神经网络任务实测中,从 2014 年到 2019 年,最好的神经网络计算效率相差了 100 倍,相当于计算效率每 9 个月翻一倍,远快于每 18 个月翻倍的摩尔定律。因此在模型算法演进速度远快于芯片性能提升的速度的现在,不仅需要算力更高的芯片,也需要更合理的性能评估方法帮助用户选择适合的 AI 芯片。
对这些 AI 时代出现的新变化,以地平线为代表的 AI 芯片企业认为,单纯依赖于 PPA 芯片设计指标,很容易陷入算力至上的“误区”,但算力并不是完全反应芯片性能唯一评估标准。因此,地平线提出了 MAPS(Mean Accuracy-guaranteed Processing Speed)概念和评估方法,以此作为检验 AI 性能的真正标准。通俗来说,就是在特定的 AI 应用领域,看芯片处理 AI 任务的速度和精度,即“多快”和“多准”。
MAPS 动态评估芯片真实 AI 性能
随着 AI 算法的不断演进,几乎每 10-14 个月,相同的计算精度计算量可以下降一半。这种提升与算法设计的精妙程度息息相关,但算法的快速演进也对计算架构提出巨大的挑战,尤其是对传统通用的并行架构而言,例如亟需高效AI专用处理器的自动驾驶场景。
MAPS 其实是在物理算力的基础上,通过对大量模型的测试,综合各个模型的速度(正比与物理算力*实际利用率)和准确率得到的最佳方案的量化结果。它更聚焦于使用户能够通过可视化的图表直观的感知 AI 芯片真实算力。正如对于汽车来说,马力(单位: HP)不如百公里加速时间(单位:秒)更真实反映整车动力性能;算力(单位: TOPS)并不反映汽车智能芯片实际性能,而每秒准确识别帧率 MAPS(单位: FPS)才是更真实的性能指标。
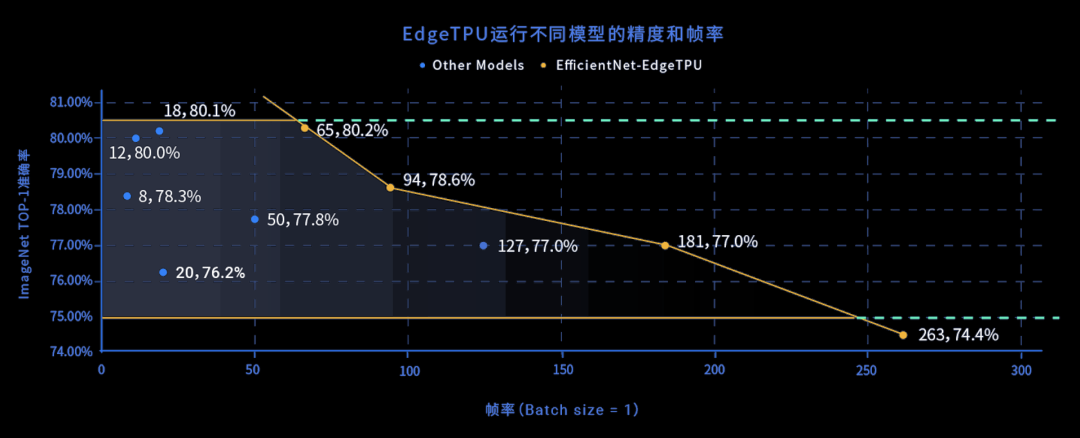
MAPS=最佳模型多边形面积/(精度上界—精度下界),其中横轴反应帧率,纵轴反应精度
此外,在自动驾驶中应该如何对速度和精度做取舍呢?现实生活中我们经常遇到一些极端的案例,例如当汽车遭遇小孩子横穿马路的突发状况时,如果自动驾驶识别延时过高,会刹车不及时;如果精度不够,则会造成无法识别。在很多类似的场景中,我们往往面临既要“快”,又要兼顾“准”的境况。而在 MAPS 评估方法下,我们可以清晰看到帧率和精度之间的动态关系,这也是其对实际场景的重要价值之一。
更高级别自动驾驶需要多少“FPS”?
软件定义的汽车的趋势下,未来汽车正逐步成为四个轮子上的超级计算机。可以清晰预见的是,电动车卖点不是车,而是「智能」,这是一个堪比计算机诞生级别的创新。
特斯拉在 Hardware 3.0 中,采用其自研 AI 芯片 FSD Chip 替代了 Hardware 2.5 中的 Nvidia Drive PX2,算力从 24 TOPS 提升到了 72 TOPS,但运行同样模型的精度却惊人的提升了 21 倍。具体而言,Hardware 2.0 时每秒只能处理 110 帧图像,而现在则高达 2300 帧。除了绝对算力的提升,额外提升则来自于利用率的提升。同时特斯拉也宣布针对 Hardware 3.0 重写自动驾驶软件,从而在 2020 年 10 月推出了 FSD beta,这是唯一不受场地限制、大规模测试的自动驾驶方案。
特斯拉革命性技术的重构与 MAPS 背后体现的理念有相通之处:提升物理算力(HW 3.0 提升 3 倍)、提升利用率(提升近 2 倍),找到最佳的速度和准确率提升(重写自动驾驶软件),使得特斯拉从简单场景的 NOA 一步步突破到不受限的自动驾驶。而地平线在芯片设计之中一直贯彻 MAPS 背后的技术理念,关注提升物理算力的同时关注利用率的提升,并且不断把算法发展趋势,使得软硬件可以协同共振,发挥最高效能。
为了助力汽车厂商突破“特斯拉困境”,实现高级别自动驾驶的落地。地平线即将推出的征程 5 MAPS 整体跑分高达 3020 FPS,其中 MAPS@COCO (检测任务COCO MAPS) 跑分可高达 116,而 Nvidia Xavier MAPS@COCO 为 41 FPS (GPU&DLA@32W mode ),如此高的性能将助力车厂加速实现自动驾驶方案的落地。
驱动新基建数字底座,需要有算力也要有效率。自成立以来,地平线便致力于兼备算力与效率的高性能芯片。未来,地平线将推出性能更强大的征程6,其不仅在功耗、面积优化的基础上,同时在MAPS上继续提升一个数量级,助力全行业共同努力进一步大幅提升自动驾驶的安全性。
原文标题:不看算力看效率,更高级别的自动驾驶需要多少 “FPS”?
文章出处:【微信公众号:地平线HorizonRobotics】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
#芯片 #AI 世界最强AI芯片H200性能大揭秘!深圳市浮思特科技有限公司 2023-11-15
-
iphone5的图纸 真实性有待考证~2014-01-04 0
-
matlab关于城市空气污染数据的真实性判别及分析研究2016-08-15 0
-
如何辨别一个运动粘度测定仪厂家的真实性?2019-07-01 0
-
Tir-RK3399+movidius AI深度学习评估板有哪些性能呢2022-03-07 0
-
可以使用ECCDSA去验证FW固件的真实性吗2022-12-12 0
-
如何使用ECDSA进行固件真实性验证?2022-12-15 0
-
诺基亚8设计图曝光 用蔡司双摄真实性不高2017-03-29 352
-
Adobe已经启动了内容真实性计划2020-10-24 1626
-
企业数字化转型的本质2022-07-26 1656
-
AI重新评估世界上最神秘的艺术品的真实性2022-10-26 290
-
产品的真实性与可靠性2022-11-01 906
全部0条评论

快来发表一下你的评论吧 !
