

介绍一种新颖的三元组对比学习训练框架
描述
摘要
在自然语言处理和知识图谱领域的信息提取中,三元组抽取是必不可少的任务。在本文中,我们将重新审视用于序列生成的端到端三元组抽取任务。由于生成三元组抽取可能难以捕获长期依赖关系并生成不忠实的三元组,因此我们引入了一种新的模型,即使用生成式Transformer的对比学习三元组抽取框架。
具体来说,我们介绍了一个共享的Transformer模块,用于基于编码器-解码器的生成。为了产生忠实的结果,我们提出了一种新颖的三元组对比学习训练框架。此外,我们引入了两种机制来进一步改善模型的性能(即,分批动态注意掩码和三元组校准)。在三个数据集(NYT,WebNLG和MIE)上的实验结果表明,我们的方法比基线具有更好的性能。我们的代码和数据集将在论文出版后发布。
论文动机
编码器-解码器模型是功能强大的工具,已在许多NLP任务中获得成功,但是现有方法仍然存在两个关键问题。首先,由于递归神经网络(RNN)的固有缺陷,它们无法捕获长期依赖关系,从而导致重要信息的丢失,否则将在句子中反映出来,从而导致模型无法应用更长的文本。第二,缺乏工作致力于生成忠实的三元组,序列到序列的体系结构会产生不忠实的序列,从而产生意义上的矛盾。例如,给定句子“美国总统特朗普在纽约市皇后区长大,并居住在那里直到13岁”,该模型可以生成事实“(特朗普出生于皇后区)”。尽管从逻辑上讲是正确的,但我们无法从给定的句子中找到直接的证据来支持它。
为了解决这些问题,我们引入了带有生成变压器(CGT)的对比学习三元组提取框架,该框架是一个共享的Transformer模块,支持编码器-解码器的生成式三元组对比学习多任务学习。首先,我们使用分隔符和部分因果掩码机制将输入序列与目标序列连接起来,以区分编码器-解码器表示形式。除了预先训练的模型之外,我们的模型不需要任何其他参数。然后,我们介绍了一种新颖的三元组对比学习对象,该对象利用真实的三元组作为正实例,并利用随机令牌采样将损坏的三元组构造为负实例。为了共同优化三元组生成对象和对比学习对象,我们引入了分批动态注意掩码机制,该机制允许我们动态选择不同的对象并共同优化任务。最后,我们介绍了一种新颖的三元组校准算法,以在推理阶段滤除虚假三元组。
这项工作的贡献如下:
我们将三元组提取作为序列生成任务进行了重新介绍,并引入了一种新颖的CGT模型。考虑到增加的提取功能,CGT除了在预训练语言模型中发现的参数外,不需要其他参数。
我们引入了两种机制来进一步提高模型性能(即,批处理动态注意掩码和三元组校准)。第一个可以联合优化不同的对象,第二个可以确保忠实的推理。
我们在三个基准数据集上评估了CGT。 我们的模型优于其他强大的基准模型。我们还证明,在捕获长期依存关系方面,CGT比现有的三元组抽取方法更好,因此,在使用长句子场景下依然可以获得更好的性能。
模型框架
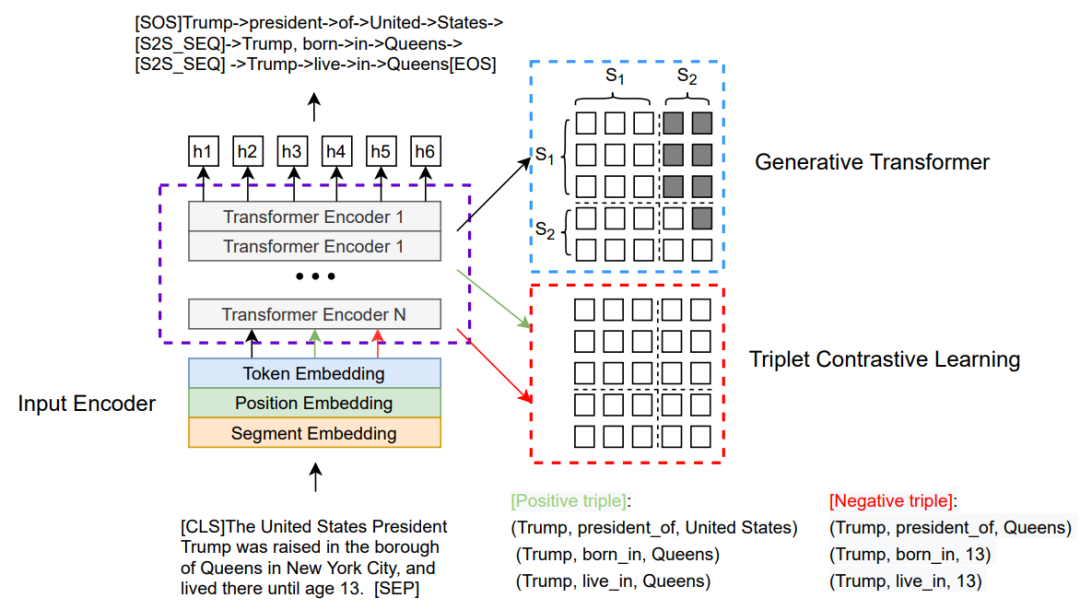
这里我们展示了CGT生成式Transformer的总体架构。右上部分表示Transformer生成模块,右下部分表示三元组对比学习模块。这两个部分训练时共同优化。生成模块依靠部分因果掩码机制建模成序列生成任务,如右图中的示例所示,对于三元组序列生成,其中右上部分设置为-∞以阻止从源段到目标段的关注;左侧部分设置为全0,表示令牌能够参与第一段。利用交叉熵损失生成来优化三元组生成过程,获得生成损失。对比学习模块将输入文本与正确的三元组实例或者伪造的三元组进行随机拼接,依靠部分因果掩码机制建模成文本分类任务,其中mask矩阵的元素全为0,利用经过MLP多层感知机层的特殊token[CLS]表示来计算分类打分函数,鉴别是否为正确实例,从而增强模型对关键token的感知能力。我们利用交叉熵优化对比损失。生成损失与对比学习损失通过一个超参数权衡构成了我们最终的总体损失。我们的解码推理采用的是波束搜索和启发式约束。
实验结果
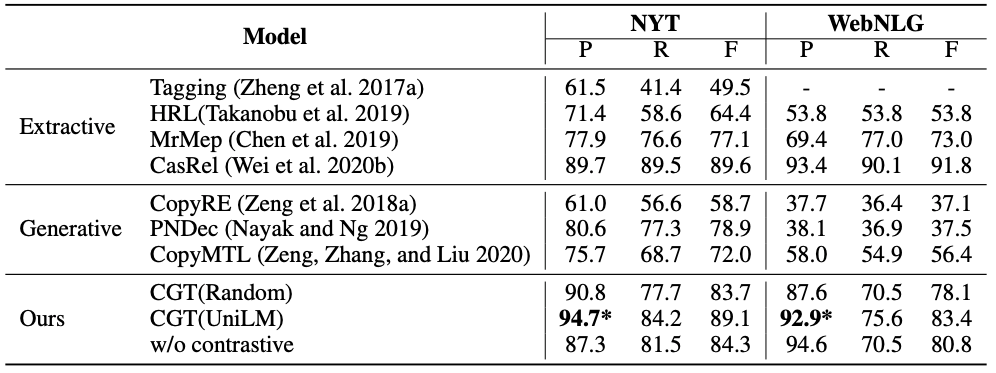
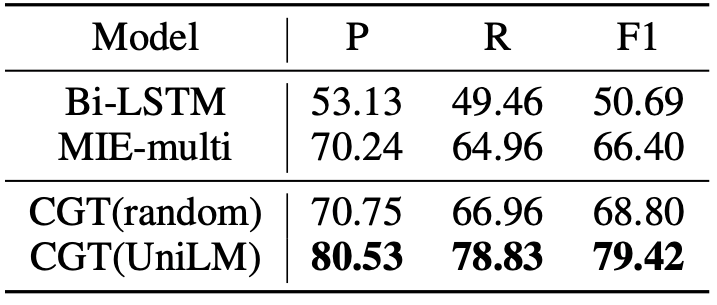
我们对三个基准数据集进行了实验:纽约时报(NYT),WebNLG和MIE。MIE是医学领域的大规模中文对话信息提取数据集。图2中中显示了这三个数据集的部分实验统计信息。
责任编辑:lq6
-
乙烯装置三元制冷技术2010-03-18 0
-
解三元一次方程组的C语言程序2013-05-06 0
-
一种形式新颖的12dB线极化RFID天线设计2019-07-23 0
-
三元素分析仪怎么使用?2019-09-19 0
-
回收电芯组,回收库存电芯组,回收聚合物电芯组,回收锂电芯组,回收动力电芯组,三元电芯组回收2021-08-24 0
-
回收电池组,回收动力电池组,回收动力锂电池组,回收三元动力电池组,回收锂电池组2021-09-10 0
-
回收动力电芯,三元电芯,回收动力锂电池,回收三元动力电池,回收锂电池,圆柱锂电池回收 动力锂电池回收2022-01-04 0
-
根据mac地址创建五元组的步骤2022-03-08 0
-
一种基于Deep U-Net的多任务学习框架2022-11-10 0
-
一种基于策略元素三元组的策略描述语言2009-04-09 476
-
可提高跨模态行人重识别算法精度的特征学习框架2021-05-10 610
-
泰凌微电子三元组认证功能实现2022-11-23 851
-
深度学习框架区分训练还是推理吗2023-08-17 1090
全部0条评论

快来发表一下你的评论吧 !
