

深入剖析多线程计算平台的性能模型
描述
在以前的文章里,笔者谈到单核CPU无论在PC端还是服务器上基本上已经退出历史舞台,目前主流的计算平台是使用多核(multiple cores)的CPU以及众核(many cores)的GPU。另外处理器与内存访问速度差距也不断增大,为克服访存瓶颈主要采用两种方法。
其中多核CPU与单核CPU都是利用Cache来掩盖访问系统内存的延迟,以减轻访存带宽的压力,其芯片的较大面积也都贡献给Cache。在另一端,GPU通过同时运行很多简单的线程,不使用或者只利用相对较小的Cache。
而主要通过线程间的并行(Thread Level Parallelism, TLP)来隐藏内存访问延迟,当一部分线程因为访存停滞的时候,另一部分线程会接着执行,使得处理单元不会空闲下来。
目前的异构计算平台同时采用这两种截然不同的架构,使得性能预测和优化都不太容易,面对一个给定的计算负载,我们应该如何分发能够达到性能最佳?对芯片架构师而言,在面积受限的芯片上,怎样合理部署处理单元、Register File和Cache等等也是让人挠头的事情。
希望能够为理解优化性能提供参考,论文作者定义了一个统一仿真模型可以容纳延展这两种不同特点的架构设计。这个模型对应一个想象的混合计算平台,该平台由很多简单的处理单元以及较大的共享缓存构成,通过灵活配置一系列参数,包括处理单元个数、缓存大小以及缓存和内存的访问延迟等等,可以观察不同参数变化对计算性能的影响。
为保持模型简单,论文假设所有线程相互不共享数据且系统内存带宽足够大。如下图所示,作者发现,当线程数量较少的时候,随着线程数量增加,性能开始提升,而当线程数量到达转折点,Cache不能够容纳所有线程的工作集的时候,性能反而下降。
之后,随着线程数量越来越多,由于有足够的线程来掩盖Cache访问不命中带来内存访问延迟,性能又接着上升,直达到平台可获得的最大性能。我们可以认为MC Region对应多核CPU的情形,而MT Region自然对应有超多线程的GPU,MC Region和MT Region之间的性能波谷区域在我们的架构设计和程序优化中都是要努力避免的。
以下我们具体推导下参数曲线对应的公式,下表列出计算模型涉及的参数,左边是平台相关的,右边跟运算任务有关。
公式(1)为考虑Cache命中率的线程平均访问内存所需要的时钟数。
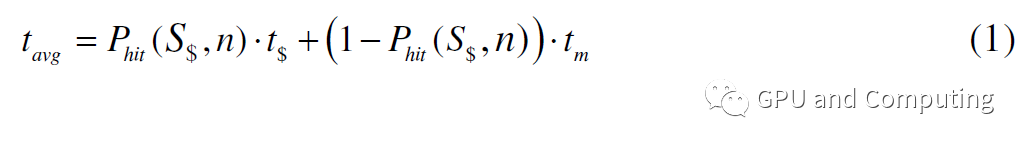
这就是说,线程每运行1/rm条指令,就会因为访存停滞tavg时钟,如果没有别的线程替换进来,对应的处理单元就会处于空闲状态,要让该处理单元充分利用,额外需要的线程数为tavg/(CPIexe/rm)。所以要让整个计算平台满负荷运转,总共需要的线程数量为
NPE * (1 +tavg/(CPIexe/rm))。给定有n个线程的计算任务,计算平台的利用率η可以计算如公式(2)。
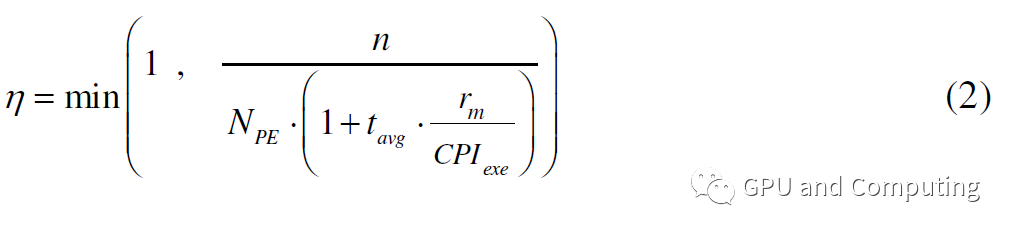
在η=1的情况下,再添加多余的线程于性能无补。根据利用率η我们可以得到计算平台的预期性能为NPE * (f/CPIexe)*η OPS(Operations Per Second,每秒钟运算数)。通过该公式,我们可以观察以下各种参数调节对性能曲线的影响。
值得注意的是以上计算中我们没有考虑内存带宽受限的情况,如果把它纳入考虑,对特定性能Performance,我们可以按公式(3)计算所要求带宽。
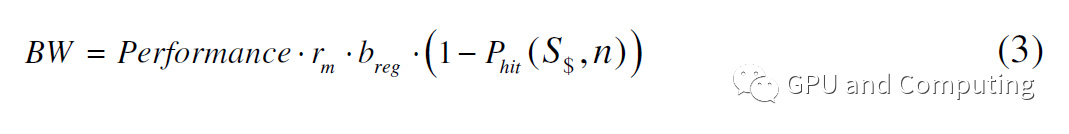
所以在内存带宽也是约束条件的情况下,性能计算修正为公式(4)。
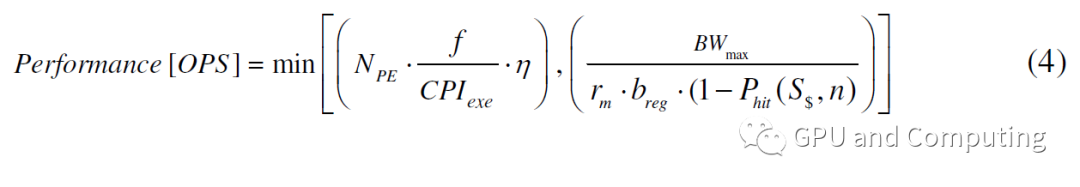
而下图也反映了内存带宽对性能曲线的影响。值得提醒的是性能曲线水平顶表示计算任务在该平台上已经触到了内存带宽墙(off-chip bandwidth wall),在这种情况下继续增加线程有可能会恶化Cache命中率,使得带宽问题更加严重反而有损性能,这也是为什么之前我们提到过的GPU显存带宽要远大于CPU系统内存带宽。
主要参考资料:
Many-core vs many-thread machines: Stay away from the valley
The Interplay of Caches and Threads in Chip-MultiProcessors
编辑:jq
-
基于MIPS多线程处理器的SOC设计2019-07-18 0
-
多线程的过程程序2021-08-24 0
-
rk3399pro的npu是否是支持多线程同时调用呢2022-04-15 0
-
如何使用多线程和异步操作等并发设计方法来最大化程序的性能2022-08-23 0
-
Windows CE下多线程串口通信2009-06-04 428
-
基于SWT的多线程解决方案2011-06-07 619
-
linux多线程编程课件2011-07-10 710
-
内存模型-多线程内存模型2011-07-25 590
-
MFC下的多线程编程2016-09-01 595
-
Windows多线程编程2016-09-01 790
-
多线程好还是单线程好?单线程和多线程的区别 优缺点分析2017-12-08 80047
-
什么是多线程编程?多线程编程基础知识2017-12-08 12147
-
多线程服务器编程模型:如何正确使用mutex 和condition variable2018-02-19 6938
-
大小核的OpenMP多线程并行计算测试2019-05-04 4165
-
Java多线程的用法2023-09-30 636
全部0条评论

快来发表一下你的评论吧 !
