

Jetson Nano b01国产开发套件测评
今日头条
描述
Jetson Nano是英伟达发布的一款小型人工智能(AI)计算主板,最大亮点是带有嵌入式领域相对高端的GPU,并且提供AI和计算机视觉(Computer Vision)的应用程序编程接口(API),可以直接用于注重低功耗的AI应用场景。
Jetson Nano自发布以来,在开源硬件圈子里的热度一向很高,但由于疫情导致全球物料短缺,一芯难求.Nvidia公司对于Jetson Nano开发板的产能急剧下降,市场基本上无货可买,有货的商家也将单价提到极高的价格.为了保证各位开发者能够继续使用Jetson Nano开发板进行各项科研工作,图为信息科技(深圳)有限公司结合Jetson nano开发板特性,综合各项性能,结合Jetson nano模块,自研载板,最终在不懈努力之下研发出了图为Jetson Nano国产套件,一比一大小还原Nvidia Jetson Nano开发板,可完美对接开发板的各种AI特性以及开发优势.本篇评测除了实事求是地展示图为Jetson Nano国产套件的各项性能特点,还将从入门指导角度尽力地为大家排除各种使用障碍。

1.Jetson Nano核心模块硬件概况
GPU:NVIDIA Maxwell 架构,128 个 NVIDIA CUDA 核心
● CPU:四核 ARM Cortex-A57
● 处理器内存:4GB 64 位 LPDDR4
● 存储:16G EMMC
● 视频编码:一路4K@30p、或4路1080p@30、或两路1080p@60
● 视频解码:一路4K@60p、或两路4K@30、或8路1080p@30
● 摄像头:2 x MIPI CSI-2或USB或者网络摄像头
● 摄像头网络:千兆以太网
● 显示器:HDMI 2.0 或 DP1.2
● 高速接口:1 x PCIe、4x USB 3.0I/O
● UART、2x SPI、3x I2C、I2S、GPIOs

图为Jetson Nano国产开发套件由核心板和载板组成,它们通过SO-DIMM接口连接,这种接口常见于笔记本内存。图为Jetson Nano国产开发套件使用的核心板与Nvidia Jetson Nano开发板的核心板不同,国产套件是采用带16g Hynix emmc5.1作为核心存储,官方套件则是采用sd卡作为核心存储.
eMMC (Embedded Multi Media Card)是MMC协会订立、主要针对手机或平板电脑等产品的内嵌式存储器标准规格。eMMC在封装中集成了一个控制器,提供标准接口并管理闪存.eMMC的应用是对存储容量有较高要求的消费电子产品。2011年已大量生产的一些热门产品,如Palm Pre、Amazon Kindle II和Flip MinoHD,都采用了eMMC。
EMMC优点:
1.简化存储器的设计。eMMC是当前最红的移动设备本地存储解决方案,目的在于简化手机存储器的设计,由于NAND Flash芯片的不同品牌包括三星、KingMax、东芝(Toshiba)或海力士(Hynix)、美光(Micron)等,所以都需要根据每家公司的产品和技术特性来重新设计,而过去并没有技术能够通用所有品牌的NAND Flash芯片。
2.更新速度快;
3.加速产品研发速度。
相比于sd卡作为核心存储.emmc速度更快,稳定性更高,适应环境能力更强,更符合当前边缘设备的系统环境搭建.
2.供电与系统启动指导
首先,Nvidia开发板套件里是没有包含显示器、HDMI线和电源等部件,这些需要用户自己准备或购买。使用的电源为5v4a的DC电源或者Micro USB电源,板子上有个供电选择跳线帽,编号J48。当通过Micro-USB供电时,需要保证J48上的跳线帽断开,Micro-USB电源导通,DC电源切断;当通过DC接口供电时,需要保证跳帽接上,这个在实际使用过程中往往会造成使用者的疑惑,怀疑刚收到的设备有问题.但是在图为Jetson Nano国产开发套件上采用唯一DC供电,无需连接跳线帽,直接连接12DC电源适配器即可,在保证简单实用的前提下,相比Nvidia开发套件5v4a的输入更为稳定,面对大型模型时,也不会掉电压力。

图为Jetson Nano开发套件的显示器支持HDMI接口和DP接口。目前市场上HDMI显示器已经比较普及,如果你的显示器只支持VGA的话,得考虑新买一台显示器。如果使用电视机做显示器用,现在市场上主流品牌的液晶电视都同时支持HDMI和DP。

摄像头模块可以使用Jetson Nano推荐的LI-IMX219-MIPI-FF-NANO摄像头模块;也支持第三方的树莓派的Pi Camera V2模块。如果你已经有树莓派V2摄像头,可以直接使用。摄像头接到下图CAM0和CAM1接口。

3.性能测试
Jetson Nano应该算是阉割加降频的Jetson TX1。CPU方面去掉了big.LITTLE中的4个A53,GPU中则直接砍掉了一半的CUDA核心。其实4个A53对于TX1本来就很鸡肋,因为你并不能同时使用8个核心,只能按集群来切换。与TX1相比,Nano中的4个A57频率也从1.9GHz降到了1.43GHz。由于继续使用20nm制程,降频显然是降低功耗的另一主要手段。GPU频率从1GHz降到922MHz,变化不大,也与Switch SoC的最高频率一致。使用Ubuntu Benchmark Tools做了一些跑分测试。可以看出性能大致相当于2008年的主流CPU。
总的来说,Nano的CPU性能强于树莓派3B,与树莓派4相差不大。虽然GPU的472GFlops半精度浮点性能大概只有TX2的1/3,但也基本达到Intel HD Graphics 615集显的水平。再加上有CUDA加持,实际性能应该更强。那么树莓派能做的事,Nano都能做,树莓派做不了的事,Nano或许也能做。
3.1测试 TensorFlow
跑一段自己写的非线性回归代码, 速度还是挺快的, 使用 vi 新建 python 文件命名: tensorflowDemo.py然后复制以下代码进去。保存后使用 python3 tensorflowDemo.py 运行, 这段必须在图形化界面下运行,因为会出现一张图表。由于是 TensorFlow2 所以把 import tensorflow as tf 改成了 import tensorflow.compat.v1 as tf 和 tf.disable_v2_behavior(),即代码的前两句,如果是TensorFlow1 则为 import tensorflow as tf。
# -*- coding: utf-8 -*-
import tensorflow.compat.v1 as tf tf.disable_v2_behavior()
import numpy as np
import matplotlib.pyplot as plt
x_data = np.linspace(-0.5, 0.5, 200)[:, np.newaxis] noise = np.random.normal(0, 0.02, x_data.shape) y_data = np.square(x_data) + noise
x = tf.placeholder(tf.float32, [None, 1]) y = tf.placeholder(tf.float32, [None, 1])
# 输入层一个神经元,输出层一个神经元,中间 10 个
# 第一层
Weights_L1 = tf.Variable(tf.random.normal([1, 10])) Biases_L1 = tf.Variable(tf.zeros([1, 10])) Wx_plus_b_L1 = tf.matmul(x, Weights_L1) + Biases_L1 L1 = tf.nn.tanh(Wx_plus_b_L1)
# 第二层
Weights_L2 = tf.Variable(tf.random.normal([10, 1])) Biases_L2 = tf.Variable(tf.zeros([1, 1]))
Wx_plus_b_L2 = tf.matmul(L1, Weights_L2) + Biases_L2 pred = tf.nn.tanh(Wx_plus_b_L2)
# 损失函数
loss = tf.reduce_mean(tf.square(y - pred))
# 训练
train = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(2000):
sess.run(train, feed_dict={x: x_data, y: y_data})
print("第{0}次,loss = {1}".format(i, sess.run(loss,feed_dict={x: x_data, y: y_data}))) pred_vaule = sess.run(pred, feed_dict={x: x_data})
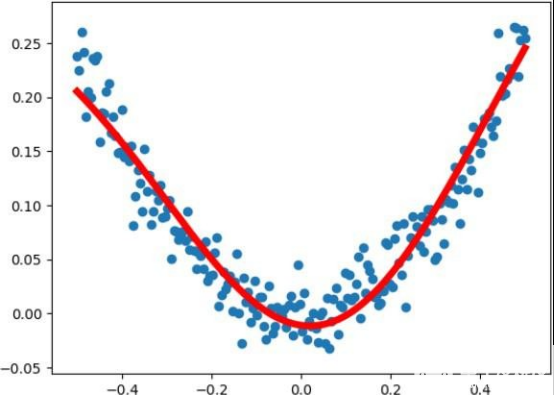
plt.figure() plt.scatter(x_data, y_data)
plt.plot(x_data, pred_vaule, 'r-', lw=5)
plt.show()
3.2 YOLOv4 环境搭建和摄像头实时检测
因为用的是opencv4所以使用 yolo3编译可能回出错,可以换成 yolov4 或yolov4-tiny, 同时YOLO V4无论在精度和速度上都较YOLO V3有了很大的提升,为在性能受限的嵌入式设备上部署检测程序提供了可能。yolo v4和yolov4-tiny的区别是:tiny是yolov4 的压缩版,主要运行小算力 cpu 核心版本,在 jetso nano上使用tiny版帧率会比 yolov4提升十多倍。总的来说还是推荐使用yolov4-tiny,帧率提升很多,使用感会提升很多。
闲话少说,开始安装。
下载
git clone https://github.com/AlexeyAB/darknet.git
配置
cd darknet
sudo vim Makefile #修改 Makefile
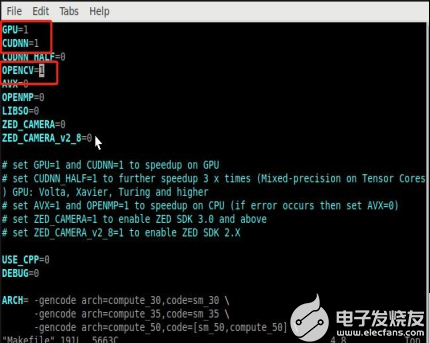
将下图标注中的三项值由0修改为1
GPU=1
CUDNN=1
OPENCV=1
编译
在 darknet 路径下编译
make -j4
放置权重文件
将github上下载好权重文件后,将权重文件yolov4.weights 和 yolov4-tiny.weights 拷贝至 darknet 目录下,

测试
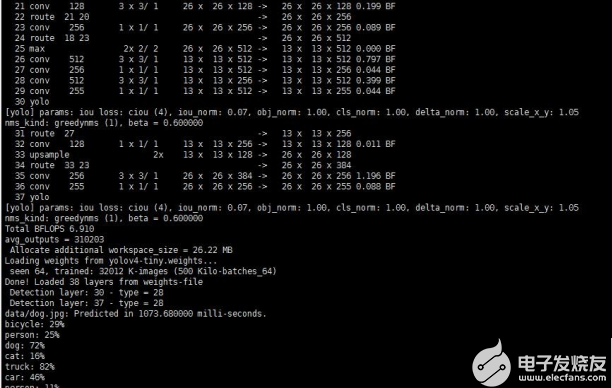
Yolov4 图片的检测
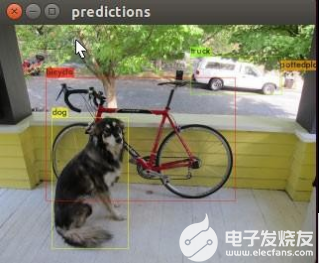
./darknet detect cfg/yolov4.cfg yolov4.weights data/dog.jpg # 简写版
./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights data/dog.jpg # 完整版
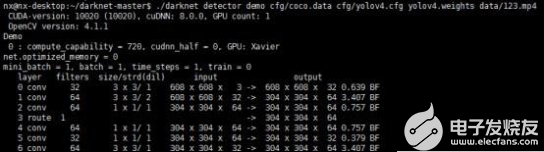
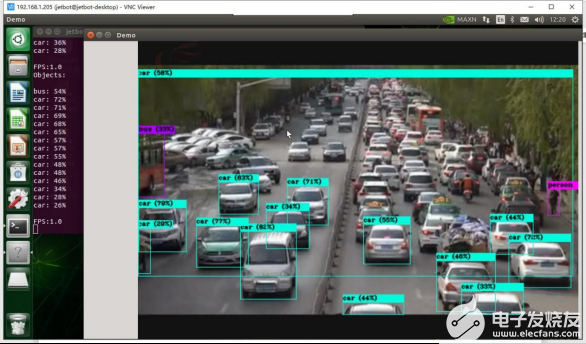
Yolov4 视频的检测(github 下来的data 里面并没有该视频文件,需要用户自行上传要检测的视频文件到data 文件夹下)
./darknet detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights data/123.mp4
总结
这个就是我们传说中的,英伟达AIOT的一款重量级产品 - Jetson Nano!
千万别小看这快板子,它可是可以跑Ubuntu 18.04, CUDA什么的一应俱全,并且具有4G显存的而且体积非常小的神器.这是一块性能非常强悍的板子,更重要的是软件资源非常丰富,你可以编译依赖库非常复杂的caffe,并且你还可以任意编译任何你的tensorrt加速的模型;这快板子的推理速度可以满足一些基本的需求。比如:
基于yolov3的人流和车流的检测;
基于MTCNN的人脸检测和比对(带人脸建库);
使用TensorRT加速onnx模型;
基于yolov3的手检测器等,
目前人工智能风口开始逐步进入落地应用阶段,更多产品希望能够将人工智能算力运用于实际终端,即实现所谓的边缘计算需求。从根本上来说近几年推动人工智能的核心在于深度学习算法,但是深度学习的推理加速离不开高速GPU的支持,而一般桌面PC或服务器级别的显卡(如英伟达1080Ti等)价格非常昂贵,不适合边缘计算需求,而且体积也过于庞大。因此,英伟达推出的这款嵌入式人工智能开发板Jetson Nano非常契合当前行业需求。
审核编辑:符乾江
-
 jf_22343912
2023-08-08
0 回复 举报目前,国产的大概要多少钱 收起回复
jf_22343912
2023-08-08
0 回复 举报目前,国产的大概要多少钱 收起回复
-
【LicheeRV-Nano开发套件试用体验】+智能平板开发2024-03-06 0
-
EASY EAI Nano开发套件开箱体验# #硬声创作季 #硬声新人计划jf_1137202360 2022-10-06
-
jetson nano开发板2020-08-20 0
-
基于JetsoN Nano开发套件的开源智能车项目2020-11-04 0
-
Jetson Nano B01 从零入门笔记系列(一)基本组装与启动问题 精选资料推荐2021-07-20 0
-
Jetson Nano具有哪些优势?Jetson Nano怎么安装?2021-09-28 0
-
微雪电子人工智能开发套件 简介2019-11-20 1178
-
微雪电子人工智能开发套件简介2019-11-20 953
-
NVIDIA Jetson Nano 2GB开发套件的应用2022-04-18 1150
-
贸泽开售Seeed Studio reComputer Jetson开发套件助力AI应用开发2022-06-27 651
-
Jetson Orin开发套件安装开发环境的详细步骤2022-07-06 2924
-
使用 NVIDIA Jetson Nano 开发套件提高您的边缘 AI 和机器人技能2022-12-07 711
-
GTC23 | 使用 NVIDIA Jetson Orin Nano 开发套件开发 AI 机器人及智能视觉系统2023-03-29 1066
-
Jetson Orin Nano纳米刷机介绍2023-04-01 2293
-
Jetson Nano 是学习 AI 边缘计算的神器2023-05-17 845
全部0条评论

快来发表一下你的评论吧 !
