

使用NVIDIA TAO工具包构建对话AI和应用程序
描述
对话式人工智能是一组技术,能够在人类和设备之间基于最自然的界面(语音和自然语言)进行类似人类的交互。基于对话人工智能的系统可以通过识别语音和文本、在不同语言之间进行即时翻译、理解我们的意图以及以模仿人类对话的方式响应来理解命令。
构建对话式人工智能系统和应用程序很困难。为您的数据中心部署量身定制哪怕是单个组件来满足您企业的需求就更难了。特定于领域的应用程序的部署通常需要几个周期的重新培训、微调和部署模型,直到满足需求为止。
为了解决这些问题,本文介绍了三个关键产品:
NVIDIA TAO Toolkit 促进对话 AI 模型的培训和微调。
NVIDIA Riva 简化了结果模型的部署和推断。
NVIDIA NGC collections 已经预先训练了对话 AI 模型,可以作为进一步微调或部署的起点。
由于这些产品的紧密集成,您可以将 80 小时的培训、微调和部署周期压缩到 8 小时。在本文中,我们将重点介绍 TAO 工具包,向您展示它如何支持各种迁移学习场景,以及它如何与 Riva 集成以部署对话 AI 模型和运行实时推理。
会话人工智能简介
在对话人工智能系统中,有几个组件,大致分为三个主要领域(图 1 ):
自动语音识别( ASR )封装以用户语音作为输入开始的所有任务。在这些任务中,最常用的是负责生成口语单词和句子的转录本的语音对文本。
自然语言处理( NLP )负责文本处理,包括提取、理解和处理语义信息。 NLP 封装了许多任务,从简单的任务(如命名实体识别)到复杂的任务(如对话框状态跟踪、问答和机器翻译)。
文本到语音( TTS )将系统以文本形式的响应转换为您可以听到的音标。
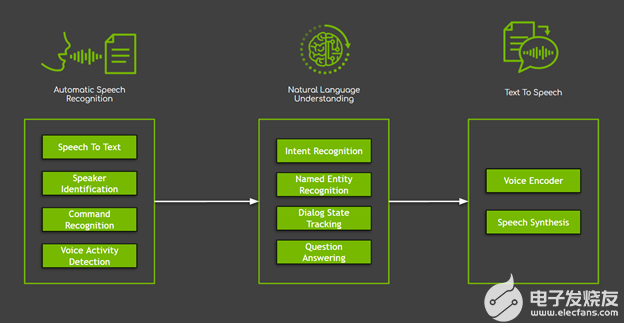
图 1 。对话人工智能系统的三个主要领域,以及示例任务。
虽然这些任务可以以各种方式实现,但由深度神经网络推动的新方法已经取得了最佳效果,克服了大多数机器学习和基于规则的解决方案的局限性。然而,这一进步是有代价的:基于神经网络的模型需要大量的数据。
克服数据匮乏最常见的解决方案之一是使用一种称为迁移学习。 转移学习可以使现有的神经网络适应(微调)到新的神经网络,这需要更少的领域特定数据。在大多数情况下,微调所需的时间显著减少(通常减少 x10 倍),从而节省时间和资源。最后,由于缺乏高质量、大规模的公共数据集,这种技术对对话式人工智能系统特别有吸引力。
TAO 工具包 3 。 0 概述
TAO Toolkit 是一个 Python 工具包,用于获取专门构建的预训练神经模型,并使用您自己的数据对其进行定制。该工具包的目标是使优化的、最先进的、经过预训练的模型易于在自定义企业数据上重新编译。
TAO 工具包最重要的区别在于它遵循零编码范式并附带了一组可随时使用的 Python 脚本和配置规范以及默认参数值,使您能够启动培训和微调。这降低了门槛,使没有深入了解模型、深度学习专业知识或开始编码技能的用户能够培训新模型并对预先训练的模型进行微调。随着新的 TAO Toolkit 3 。 0 版本的发布,该工具包实现了重大转变,并开始支持最有用的对话 AI 模型。
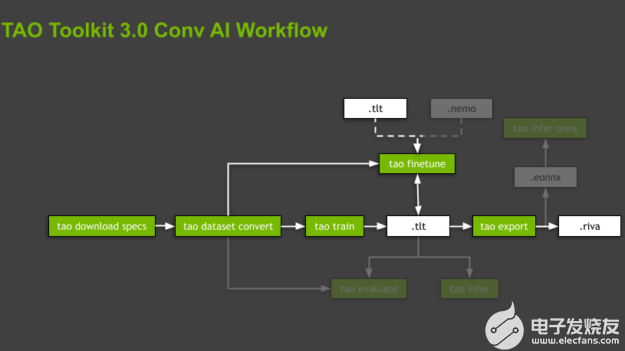
图 2 。 TAO 工具包的一般工作流程,包括最重要的子任务(绿色框)和资产(白色框)。
TAO 工具包通过在专用的、预构建的 Docker 容器中执行所有操作来抽象软件依赖关系。脚本按层次结构组织,遵循与支持的模型关联的域和特定于域的任务。对于每个模型,工具箱通过强制命令的执行顺序来指导您,从数据准备、培训和微调模型到导出以供推断。这些命令是子任务,整个组织称为工作流程(图 2 )。
TAO 工具包为每个工作流提供了几个有用的脚本。在这篇文章中,我们将重点关注突出显示的子任务,只简要提及其余的子任务。
使用 TAO Toolkit 3 。 0 构建对话 AI 模型
TAO 工具包以 Python 包的形式提供,可使用 NVIDIA PyPI (Private Python Package) 中的 pip 进行安装。入口点是 TAO 工具包启动器,它使用 Docker 容器。确保 following prerequisites 可用:
安装玩具娃娃按照官方指令的要求。然后,按照 post-installation 步骤确保 Docker 可以在没有管理员权限(即没有 sudo )的情况下运行。
安装Invidia 容器工具包通过遵循 instructions 。
登录到 NGC Docker 注册表。
地图目录
TAO 工具包在后台运行 Docker 容器,以执行与不同命令相关联的脚本。这个容器隐藏在 TAO 工具包启动器后面,所以您不必担心它。唯一的要求是预先指定存储数据、规范文件和结果的单独目录。您还应该挂载一个 .cache 目录,工具箱可以在其中存储下载的、预先训练的检查点。这可以防止脚本在每次运行新的培训或微调时反复下载相同的文件。
可以使用命令行参数设置这些目录并使其对 Docker 容器可见,也可以在 ~/.tao_mounts.json 文件中配置这些目录。有关更多信息,请参阅 Running the launcher 。
下面的代码示例是一个配置文件。 source 值表示计算机中的目录, destination 是 Docker 容器中映射的目录。

利用迁移学习建立文本分类模型
下面是 NLP 领域的一个示例任务:基于 BERT 的模型的文本分类。文本分类是根据文本内容为文本指定标记或类别的一般任务。
在下一节中,您将重点介绍 文本分类的两种不同应用:
情绪分析– 类别表示输入段落的积极或消极情绪。
领域分类– 这些类别是不同的会话域。
使用 TAO Toolkit 3 。 0 在 NLP 领域中使用迁移学习有两种不同的方法。
下载实验规范文件
初始化 TAO 工具包启动器后,可以开始调用与一个或另一个工作流关联的命令。所有这些命令都在调用需要大量参数的脚本,例如数据集参数、模型参数、优化器和训练超参数。使 TAO 工具箱如此易于使用的部分原因是,大多数参数都以实验规范文件( spec 文件)的形式隐藏起来。
您可以从头开始编写这些规范文件,也可以通过运行 tao 《 task 》 download _ specs 《 args 》从每个任务或工作流可以下载的默认文件开始编写。您甚至可以通过启动器单独覆盖每个或所有这些参数。有关每个任务的每个脚本或子任务的参数化的更多信息,请参阅 Text Classification 。
要启动,请下载文本分类任务的默认等级库文件:

请注意, -o 参数指示要下载默认规范文件的文件夹, -r 参数指示脚本保存日志的位置。确保 -o 参数指向空文件夹。
使用预训练编码器训练情绪分析模型
对于情绪分析示例,请使用公开的 Stanford Sentiment Treebank (SST-2) 数据集。它包含 215154 个短语,在电影评论中 11855 个句子的解析树中有情感标签。该模型可以在细粒度( 5 向)或二元(正/负)分类任务上进行训练,并根据精度评估性能。 SST-2 格式包含每个数据集分割的。 tsv 文件,即训练、开发和测试数据。每个条目都有一个空格分隔的句子,后跟一个选项卡和一个标签。
下载数据
下载 SST-2.zip archive 并将其解压缩到主机上的一个目录中,您将在其中存储数据并将其装载到 TAO Toolkit Docker 。在本例中,它是主文件夹中的/ data 文件夹:

准备数据
训练或微调模型的第一步是准备数据。 TAO Toolkit 使用专用的数据集转换脚本( tao dataset_convert )支持此步骤,这些脚本将输入数据预处理为培训、微调、评估或推理所需的格式。
对于文本分类任务, TAO Toolkit dataset _转换脚本支持两个公开可用的数据集,即 SST-2 和 IMDB 数据集。对于该职位,请使用 SST-2 :

请注意,所需的 -e 选项负责将配置规范文件提供给脚本,而 -r 选项指示脚本将日志文件保存在何处。所有路径都引用安装在 Docker 容器中的目录。
将数据集转换为正确的格式后,工作流中的下一步是开始培训( tao train )或微调( tao finetune )。
使用预训练编码器训练模型
从体系结构的角度来看, TAO Toolkit 中支持的所有 NLP 模型都属于 encoder-decoder models 的一般类别,编码器是 BERT (来自 transformer s 的双向编码器表示)和非回归解码器的变体之一。有关 NLP 模型和基于 BERT 的体系结构的更多信息,请参阅本文后面的内容。
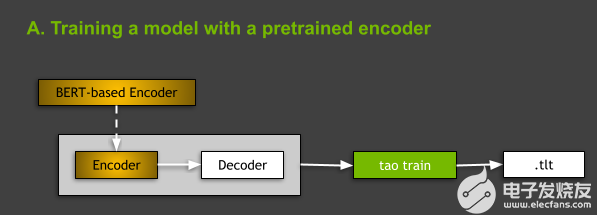
图 3 。图中显示了使用预训练编码器训练模型的想法。
在 TAO Toolkit 中训练 NLP 模型时,有两种选择:从头开始训练,或者使用基于 model: 的编码器训练模型,该编码器在一些通用 NLP 任务上进行了预训练。在本文中,我们将重点讨论后一种情况(图 3 )。您可以通过在 spec 文件中指出 BERT 的 language_model 小节中基于预训练的 BERT 编码器的名称来实现这一点

这是为文本分类任务下载等级库文件时的默认设置。有关更多信息,请参阅 Required Arguments for Training 。
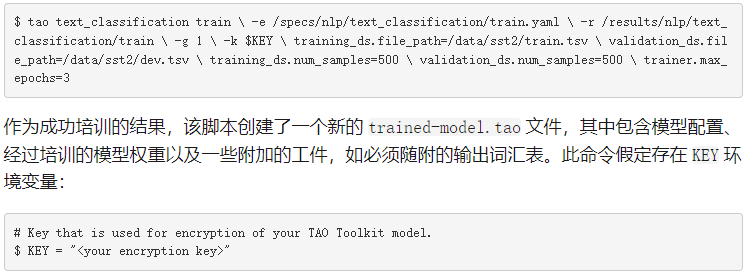
要训练模型,必须运行 tao text_classification train 命令:
-e :微调规范文件的路径。
-r :保存输出日志和模型的文件夹的路径。
-g : number of GPU to use 。
-k :保存或加载模型时要使用的用户指定的加密密钥。
-r :用于指定保存结果的目录。
对等级库文件中参数的任何替代。
正如您在本文的其余部分中所看到的,所有工作流中的大多数 TAO 工具箱子任务都共享这些参数。
微调领域分类模型
TAO 工具包还支持不同的用例:微调从 NGC 下载的预训练模型。在以下部分中,我们将向您展示如何微调域分类器。
从 NGC 下载预训练模型
TAO 工具包在 NGC 上提供了几个资产。从 NGC TAO Toolkit Text Classification model card 下载预训练模型。为便于使用,请将其下载到/ results 文件夹:

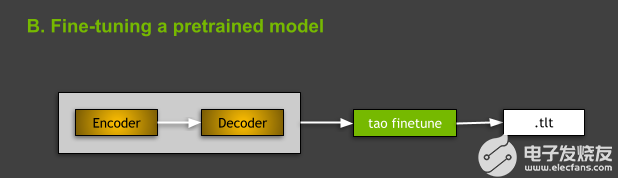
图 4 。微调预训练模型。
微调预训练模型
要微调 TAO 工具箱中的文本分类模型,请使用 tao text_classification finetune 命令。从命令的角度来看,训练和微调之间的主要区别在于存在微调所需的预训练模型 -m 参数,其中 -m 是预训练模型文件的路径。
在本例中,必须将数据集转换为培训和微调可接受的格式。有关更多信息,请参阅 Data Format 。与培训类似,您还可以手动覆盖包含微调和验证数据的文件的路径,假设微调中使用的数据文件夹为 ~/tao/data/my_domain_classification/) 。将上一步下载的 nlp-tc-trained-model.tao 文件作为输入。

此公共 NGC 模型的加密密钥为 tlt_encode 。
评估绩效
评估子任务的目标是测量给定模型在测试分割上的性能。运行 tao evaluate :

运行推理
除了评估子任务外, TAO Toolkit 还为您提供了 tao infer 子任务,用于测试模型是否按预期运行,并为 speech_to_text 提供的原始输入样本(。 wav 文件)探测其输出 question_answering 的任务、原始文本或句子 任务等)。在这种情况下,运行推断显示模型是否能够正确分类输入句子的情绪:

导出模型
最后,当您确定模型行为正确时,可以使用 tao export 命令将其导出以进行部署:

默认情况下,这将导致在 /results/nlp/text_classification/export 文件夹中创建 exported-model.riva 文件。导出子任务还允许将模型导出为 ONNX (开放式神经网络交换)格式( .eonnx )。必须手动设置 export_format=ONNX 参数。完成后,还可以通过运行 tao infer_onnx 命令来测试导出的 ONNX 模型的行为。尽管如此,从部署到基于 Riva 和 Riva 的推理的角度来看,这是可选的,目前不需要。
有关所有 TAO 工具包命令的更多信息,请参阅 TAO Toolkit v3.0 User Guide 。在本文后面,我们还将简要讨论其他支持的对话 AI 任务。
在 Riva 中将对话 AI 模型部署为实时服务
NVIDIA Riva 是一个 GPU – 加速 SDK ,用于使用 GPU 构建语音 AI 服务。 Riva SDK 包括针对 ASR 、 NLP 和 TTS 任务的预训练模型、工具和优化的端到端服务。使用 Riva 将您的模型部署为在 GPU 上进行推理优化的服务。为了充分利用 GPU 的计算能力, Riva 使用 NVIDIA Triton Inference Server 为神经网络服务,并使用 NVIDIA TensorRT 运行推理。与仅 CPU 平台上所需的 25 秒相比,生成的实时服务可以在 150 毫秒内运行。
要部署导出到 Riva (上一节中创建的 .riva 文件)的 TAO 工具箱模型,请使用 Riva ServiceMaker ,这是一个组合所有必要资产(模型图、模型权重、模型配置、推理中使用的词汇表等)的实用工具,并将其部署到目标环境中。图 5 显示, Riva ServiceMaker 分为两个主要组件: riva-build 和 riva-deploy.
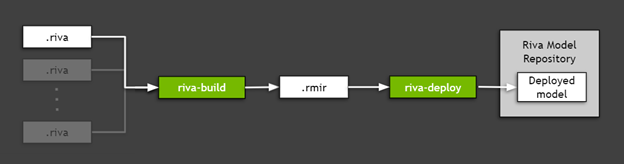
图 5 。使用 Riva ServiceMaker 部署导出的 TAO 工具包模型。
安装 Riva 必备组件
首先,设置一些环境变量以供以后使用。在本例中,您使用之前使用 TAO 工具箱训练和导出的情绪分析模型,因此必须相应地设置路径。

在本例中,您使用 /data 文件夹作为 Riva Model Repository 值,因为 Riva 快速启动脚本默认使用此名称。此文件夹用于存储模型集成以及运行推理服务器所需的所有资产。
接下来,安装 Riva Quick Start scripts 。最简单的路径是通过 NGC 注册表。安装 NGC CLI 并运行以下命令:

您已准备好进行模型部署。
运行 Riva – 构建
riva-build 负责一个或多个导出模型的组合( .riva 文件)转换为包含称为 Riva 模型中间表示( .rmir )的中间格式的单个文件。该文件包含整个端到端管道的部署无关规范,以及最终部署和推断所需的所有资产。要在 Riva ServiceMaker Docker 映像内运行 riva-build 命令,请运行以下命令:

运行 Riva – 部署
riva-deploy 部署工具将 .rmir 文件作为输入,并创建一个集合配置,指定执行的管道。
在本例中,您使用 Riva 快速启动附带的脚本,它为您运行部署。有关如何手动调用 riva-deploy 的更多信息,请参阅 Riva Deploy 。
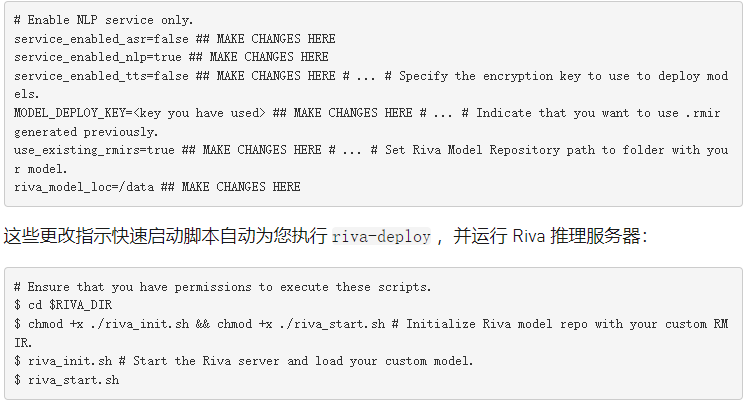
使用快速启动启动 Riva 服务器
在 Riva 中部署模型有两个选项。在这种情况下,使用前面从 NGC 中提取的 Riva 快速启动设置本地工作站。在从 pull 创建的文件夹中,找到 config.sh 文件。下面的代码示例使用了一个附加变量, $RIVA_DIR ,以指示此文件夹。编辑 config 。 sh 文件并应用以下更改:
实现客户端应用程序
Riva 服务器启动并使用您的模型运行后,您可以发送查询服务器的推断请求。要发送 gRPC 请求,请安装 Riva 客户端 Python API 绑定。这个 API 是一个带有 Riva 快速启动的 pip .whl 。
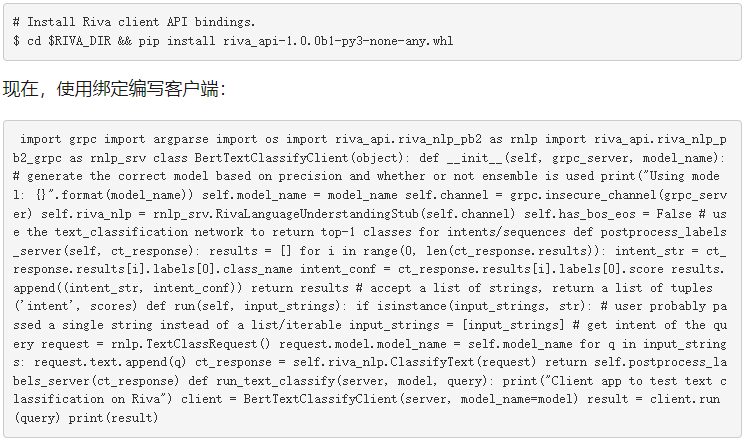
运行客户端
现在,您已准备好运行客户端:
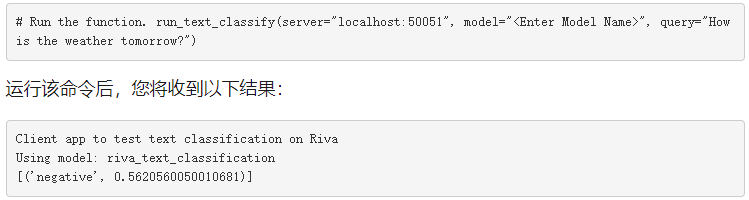
就这样!您刚刚学习了如何使用 TAO 工具包训练模型,将其部署到 Riva ,运行 Riva 推理服务器,并使用 Riva API 编写简单的客户端。祝贺
TAO Toolkit 3 。 0 中支持的其他对话 AI 任务和模型
本文介绍的文本分类任务只是当前 TAO Toolkit 3 。 0 版本中支持的任务之一。此版本支持会话 AI 空间中两个域的任务: ASR 和 NLP 。在本版本中跳过 TTS 的主要原因是我们发现培训最先进的 TTS 模型很困难。它需要用户专业知识和领域知识。他们还没有为零编码模式做好准备。
自动语音识别领域
自动语音识别( ASR )是从语音输入中提取有意义信息的任务。来自该领域的示例性任务包括向交互式虚拟助理发出语音命令、将电影和视频聊天中的音频转换为字幕,以及将客户交互转换为文本以便在呼叫中心存档。
目前, TAO Toolkit 3 。 0 支持来自 ASR 域的单个任务,即语音到文本( STT )( tao speech_to_text ),负责转录语音。模型的输出可以用于不同的目的。通过附加逻辑, STT 的输出可用于语音命令。
TAO 工具包用户有三种可用模型,所有 convolutional 神经声学模型:
Jasper 体系结构旨在通过允许将整个子块融合到单个 GPU 内核中来促进快速 GPU 推理。这对于在推理过程中满足 STT 的严格实时性要求非常重要。
QuartzNet 是一个类似 Jasper 的网络,它使用可分离卷积和更大的过滤器大小。它的精度与 Jasper 相当,但参数要少得多。
Citrinet 是 QuartzNet 的一个版本,它使用 1D 时间通道可分离卷积与子字编码、压缩和激发相结合。由此产生的体系结构显著减少了非自回归和序列到序列以及传感器模型之间的差距。
自然语言处理领域
自然语言处理( NLP )是会话人工智能应用的另一个支柱。该领域的任务包括对文本进行分类、理解语言意图、识别关键词或实体、添加自动标点符号和大写字母以及回答给定上下文的问题。
TAO Toolkit 3 。 0 支持 NLP 域中的五种不同任务或模型:
联合意图和槽分类 (tao intent_slot_classification ) 是对意图进行分类并在查询中检测该意图的所有相关插槽(实体)的任务。例如,在查询“明天早上圣塔 Clara 的天气如何?”中,您希望将查询分类为“天气”意图,将“ Santa Clara ”检测为地方插槽,并将“明早”检测为日期和时间狭槽意图和插槽名称通常是特定于任务的,并在培训数据中定义为标签。这是在任何任务驱动的对话 AI 助手中执行的基本步骤。
联合标点与大写 (tao punctuation_and_capitalization ) 对于输入句子或段落中的每个单词,模型必须预测单词后面的标点符号以及单词是否应大写。
问答 (tao question_answering ) 给定一个问题和一个自然语言的上下文,模型必须预测上下文中的跨度,并以开始和结束位置指示问题的答案。
文本分类 (tao text_classification ) 是一项基本但有用的 NLP 任务,可适用于许多应用,如情感分析、领域分类、语言识别和主题分类。例如,在情绪分析中,以下输入“表演令人难以置信!”具有积极情绪,而“既不浪漫也不刺激”具有消极情绪。
令牌分类 (tao token_classification ) 是一项任务,其中输入标记(如单词)中的每个实体在输出中都有相应的标签。命名实体识别( NER )是令牌分类任务的一个应用,其目标是检测和分类文本中的关键信息(实体)。例如,在一句话中,“玛丽住在圣塔 Clara ,在 NVIDIA 工作。”模型应该检测到“玛丽”是一个人“ Santa Clara ”是一个地方“ NVIDIA ”是一个公司。
TAO 工具包中支持的所有 NLP 模型都将 BERT 作为其主干编码器。 BERT 使用一种称为 Transformer 的基于注意的体系结构来学习上下文单词嵌入,表示文本中单词之间的关系。 BERT 的主要创新在于预训练步骤,即使用大型文本语料库对模型进行两个无监督预测任务的训练。对这些无监督任务的培训产生了一个通用语言模型,然后可以对该模型进行快速微调,以在各种 NLP 任务上实现最先进的性能。
结论
你或许会问,“ TAO 工具包最适合谁?”工具包当前形状背后的关键人口统计是已经拥有模型基础架构的用户,他们正试图定制和微调它,以适应其管道中的特定用例。
通过预定义的规范文件、详细的文档、内置加密、与面向推理的 Riva 的开箱即用集成,以及 NGC 上的一组预训练模型, TAO Toolkit 旨在将整个开发部署过程加快 10 倍。我们相信, TAO 工具包可以成为转移学习和对话 AI 的一站式工具。
关于作者
About Disha Mehra是 NVIDIA 的解决方案架构师。她的工作围绕着帮助在 NVIDIA GPU 上开发深度学习解决方案的企业客户展开。她毕业于布法罗大学,获计算机科学硕士学位。
About Mengdi Huang是 NVIDIA 的深度学习工程师,在基于 DL 的人工智能研究和应用领域拥有五年的工作经验,包括可伸缩机器学习、推荐系统、多模态语言、视觉和语音处理。
About Shashank Verma是 NVIDIA 的一名深入学习的技术营销工程师。他负责开发和展示各种深度学习框架中以开发人员为中心的内容。他从威斯康星大学麦迪逊分校获得电气工程硕士学位,在那里他专注于计算机视觉、数据科学的安全方面和 HPC 。
About Tanay Varshney是 NVIDIA 的一名深入学习的技术营销工程师,负责广泛的 DL 软件产品。他拥有纽约大学计算机科学硕士学位,专注于计算机视觉、数据可视化和城市分析的横断面。
About Evelina Bakhturina是 Nvidia 的一个深学习应用科学家,专注于自然语言处理任务和英伟达 NeMo 框架。她毕业于纽约大学,获得数据科学硕士学位。
About Jocelyn Huang是 NVIDIA 的一名深度学习软件工程师,她致力于 NeMo 框架和语音模型的开发。她毕业于卡内基梅隆大学,获得计算机科学学士学位和机器学习硕士学位。
About Vlad Getselevich:是 NVIDIA 的高级应用研究科学家,专注于对话 AI 研究主题及其在实际应用中的使用。在此之前,他开发了三个大型对话系统,每个系统都有数十万用户在生产中。他拥有以色列 Technion 的计算机科学硕士学位。
About Vahid Noroozi是一名应用研究科学家,在 NVIDIA 的人工智能应用小组工作。他的主要研究集中在语音和自然语言处理的深度学习上。他获得了博士学位。来自芝加哥伊利诺伊大学的计算机科学。
About Sergei Nikolaev是 NVIDIA 人工智能应用团队的软件工程师。他有数学博士学位。
About Yang Zhang是英伟达人工智能应用集团的一名深度学习软件工程师。她目前的重点是自然语言处理、对话管理和文本(去规范化)。在过去,她一直致力于大型 ASR 模型和语言模型预培训的可扩展培训。她在卡内基梅隆大学获得机器学习硕士学位,在德国卡尔斯鲁厄理工学院获得计算机科学学士学位。
About Purnendu Mukherjee是一名高级深度学习软件工程师,在 NVIDIA 的人工智能应用小组工作。他的主要工作是将最先进的、基于深度学习的语音和自然语言处理模型作为开发 Jarvis 平台的一部分投入生产。在加入 NVIDIA 之前, PurnNuu 毕业于佛罗里达大学,拥有计算机科学硕士学位,专门从事基于自然语言的深度学习。
About Varun Praveen是智能视频分析团队的高级软件工程师,致力于创建深度学习解决方案并将其部署到边缘。 2017 年加入英伟达之前,他在克莱姆森大学获得了电气工程硕士学位。他的研究兴趣是数字信号处理、计算机视觉和机器学习。
About Tomasz Kornuta是 NVIDIA 的高级应用研究科学家,致力于多模态机器学习和对话人工智能。在加入 NVIDIA 之前,他曾在加利福尼亚州 IBM research 担任研究人员五年,从事视觉感知、认知科学、推理和深度学习方面的研究。托马斯兹拥有博士学位。在机器人技术和控制方面拥有深厚的专业知识,包括软件工程、机器人技术、视觉感知和机器学习。他撰写或合著了 80 多篇同行评议会议和期刊论文,专门讨论这些主题。
审核编辑:郭婷
-
Labview X-net工具包编号的程序,生成应用程序后其他电脑无法使用其功能,求解!!2018-10-23 0
-
AWS与NVIDIA通过嵌入式AI简化构建应用程序2020-12-25 1489
-
NVIDIA JetPack SDK AI应用程序指南2021-04-06 700
-
什么是TAO和TAO工具套件2021-09-05 2453
-
使用NVIDIA Riva构建转录和实体识别应用程序2022-03-31 1445
-
利用TAO工具包加速AI工作流过程的方法2022-04-08 1030
-
使用NVIDIA TAO工具包和Appen实现AI模型微调2022-04-13 1095
-
使用最新的TAO工具包简化AI模型开发2022-06-21 1167
-
使用NVIDIA Omniverse构建3D工具和应用程序2022-07-14 949
-
使用 NVIDIA TAO 工具套件和预训练模型加快 AI 开发2022-12-15 778
-
创建端到端零售愿景AI应用程序2023-07-05 270
-
OneInstall Windows驱动程序和应用程序工具包2023-07-26 189
-
OneInstall Windows驱动程序和应用程序工具包分享2023-07-27 151
-
OneInstall驱动程序和应用程序工具包为Windows2023-08-02 115
-
OneInstall Windows驱动和应用程序工具包2023-08-03 157
全部0条评论

快来发表一下你的评论吧 !
