

并行计算平台和NVIDIA编程模型CUDA的更简单介绍
描述
这篇文章是对 CUDA 的一个超级简单的介绍,这是一个流行的并行计算平台和 NVIDIA 的编程模型。我在 2013 年给 CUDA 写了一篇前一篇 “简单介绍” ,这几年来非常流行。但是 CUDA 编程变得越来越简单, GPUs 也变得更快了,所以是时候更新(甚至更容易)介绍了。
CUDA C ++只是使用 CUDA 创建大规模并行应用程序的一种方式。它让您使用强大的 C ++编程语言来开发由数千个并行线程加速的高性能算法 GPUs 。许多开发人员已经用这种方式加速了他们对计算和带宽需求巨大的应用程序,包括支持人工智能正在进行的革命的库和框架 深度学习 。
所以,您已经听说了 CUDA ,您有兴趣学习如何在自己的应用程序中使用它。如果你是 C 或 C ++程序员,这个博客应该给你一个好的开始。接下来,您需要一台具有 CUDA – 功能的 GPU 计算机( Windows 、 Mac 或 Linux ,以及任何 NVIDIA GPU 都可以),或者需要一个具有 GPUs 的云实例( AWS 、 Azure 、 IBM 软层和其他云服务提供商都有)。您还需要安装免费的 CUDA 工具箱 。
我们开始吧!
从简单开始
我们将从一个简单的 C ++程序开始,它添加两个数组的元素,每个元素有一百万个元素。
#include#include // function to add the elements of two arrays void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i]; } int main(void) { int N = 1<<20; // 1M elements float *x = new float[N]; float *y = new float[N]; // initialize x and y arrays on the host for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // Run kernel on 1M elements on the CPU add(N, x, y); // Check for errors (all values should be 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i]-3.0f)); std::cout << "Max error: " << maxError << std::endl; // Free memory delete [] x; delete [] y; return 0; }
首先,编译并运行这个 C ++程序。将代码放在一个文件中,并将其保存为 add.cpp ,然后用 C ++编译器编译它。我在 Mac 电脑上,所以我用的是 clang++ ,但你可以在 Linux 上使用 g++ ,或者在 Windows 上使用 MSVC 。
> clang++ add.cpp -o add
然后运行它:
> ./add Max error: 0.000000
(在 Windows 上,您可能需要命名可执行文件添加. exe 并使用 .dd 运行它。)
正如预期的那样,它打印出求和中没有错误,然后退出。现在我想让这个计算在 GPU 的多个核心上运行(并行)。其实迈出第一步很容易。
首先,我只需要将我们的 add 函数转换成 GPU 可以运行的函数,在 CUDA 中称为 内核 。要做到这一点,我所要做的就是把说明符 __global__ 添加到函数中,它告诉 CUDA C ++编译器,这是一个在 GPU 上运行的函数,可以从 CPU 代码调用。
// CUDA Kernel function to add the elements of two arrays on the GPU __global__ void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i]; }
这些 __global__ 函数被称为 果仁 ,在 GPU 上运行的代码通常称为 设备代码 ,而在 CPU 上运行的代码是 主机代码 。
CUDA 中的内存分配
为了在 GPU 上计算,我需要分配 GPU 可访问的内存, CUDA 中的 统一存储器 通过提供一个系统中所有 GPUs 和 CPU 都可以访问的内存空间,这使得这一点变得简单。要在统一内存中分配数据,请调用 cudaMallocManaged() ,它返回一个指针,您可以从主机( CPU )代码或设备( GPU )代码访问该指针。要释放数据,只需将指针传递到 cudaFree() 。
我只需要将上面代码中对 new 的调用替换为对 cudaMallocManaged() 的调用,并将对 delete [] 的调用替换为对 cudaFree. 的调用
// Allocate Unified Memory -- accessible from CPU or GPU float *x, *y; cudaMallocManaged(&x, N*sizeof(float)); cudaMallocManaged(&y, N*sizeof(float)); ... // Free memory cudaFree(x); cudaFree(y);
最后,我需要 发射 内核,它在 add() 上调用它。 CUDA 内核启动是使用三角括号语法指定的。我只需要在参数列表之前将它添加到对 CUDA 的调用中。
add<<<1, 1>>>(N, x, y);
容易的!我很快将详细介绍尖括号内的内容;现在您只需要知道这行代码启动了一个 GPU 线程来运行 add() 。
还有一件事:我需要 CPU 等到内核完成后再访问结果(因为 CUDA 内核启动不会阻塞调用的 CPU 线程)。为此,我只需在对 CPU 进行最后的错误检查之前调用 cudaDeviceSynchronize() 。
以下是完整的代码:
#include#include // Kernel function to add the elements of two arrays __global__ void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i]; } int main(void) { int N = 1<<20; float *x, *y; // Allocate Unified Memory – accessible from CPU or GPU cudaMallocManaged(&x, N*sizeof(float)); cudaMallocManaged(&y, N*sizeof(float)); // initialize x and y arrays on the host for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // Run kernel on 1M elements on the GPU add<<<1, 1>>>(N, x, y); // Wait for GPU to finish before accessing on host cudaDeviceSynchronize(); // Check for errors (all values should be 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i]-3.0f)); std::cout << "Max error: " << maxError << std::endl; // Free memory cudaFree(x); cudaFree(y); return 0; }
CUDA 文件具有文件扩展名; .cu 。所以把代码保存在一个名为
> nvcc add.cu -o add_cuda > ./add_cuda Max error: 0.000000
这只是第一步,因为正如所写的,这个内核只适用于一个线程,因为运行它的每个线程都将在整个数组上执行 add 。此外,还有一个 竞争条件 ,因为多个并行线程读写相同的位置。
注意:在 Windows 上,您需要确保在 Microsoft Visual Studio 中项目的配置属性中将“平台”设置为 x64 。
介绍一下!
我认为找出运行内核需要多长时间的最简单的方法是用 nvprof 运行它,这是一个带有 CUDA 工具箱的命令行 GPU 分析器。只需在命令行中键入 nvprof ./add_cuda :
$ nvprof ./add_cuda ==3355== NVPROF is profiling process 3355, command: ./add_cuda Max error: 0 ==3355== Profiling application: ./add_cuda ==3355== Profiling result: Time(%) Time Calls Avg Min Max Name 100.00% 463.25ms 1 463.25ms 463.25ms 463.25ms add(int, float*, float*) ...
上面是来自 nvprof 的截断输出,显示了对 add 的单个调用。在 NVIDIA Tesla K80 加速器上需要大约半秒钟的时间,而在我 3 岁的 Macbook Pro 上使用 NVIDIA GeForce GT 740M 大约需要半秒钟的时间。
让我们用并行来加快速度。
把线捡起来
既然你已经用一个线程运行了一个内核,那么如何使它并行?键是在 CUDA 的 <<<1, 1>>> 语法中。这称为执行配置,它告诉 CUDA 运行时要使用多少并行线程来启动 GPU 。这里有两个参数,但是让我们从更改第二个参数开始:线程块中的线程数。 CUDA GPUs 运行内核时使用的线程块大小是 32 的倍数,因此 256 个线程是一个合理的选择。
add<<<1, 256>>>(N, x, y);
如果我只在这个修改下运行代码,它将为每个线程执行一次计算,而不是将计算分散到并行线程上。为了正确地执行它,我需要修改内核。 CUDA C ++提供了关键字,这些内核可以让内核获得运行线程的索引。具体来说, threadIdx.x 包含其块中当前线程的索引, blockDim.x 包含块中的线程数。我只需修改循环以使用并行线程跨过数组。
__global__ void add(int n, float *x, float *y) { int index = threadIdx.x; int stride = blockDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; }
add 函数没有太大变化。事实上,将 index 设置为 0 , stride 设置为 1 会使其在语义上与第一个版本相同。
将文件另存为 add_block.cu ,然后再次在 nvprof 中编译并运行。在后面的文章中,我将只显示输出中的相关行。
Time(%) Time Calls Avg Min Max Name 100.00% 2.7107ms 1 2.7107ms 2.7107ms 2.7107ms add(int, float*, float*)
这是一个很大的加速( 463 毫秒下降到 2 . 7 毫秒),但并不奇怪,因为我从 1 线程到 256 线程。 K80 比我的小 MacBookProGPU 快( 3 . 2 毫秒)。让我们继续取得更高的表现。
走出街区
CUDA GPUs 有许多并行处理器组合成流式多处理器或 SMs 。每个 SM 可以运行多个并发线程块。例如,基于 Tesla 的 Tesla P100 帕斯卡 GPU 体系结构 有 56 个短消息,每个短消息能够支持多达 2048 个活动线程。为了充分利用所有这些线程,我应该用多个线程块启动内核。
现在您可能已经猜到执行配置的第一个参数指定了线程块的数量。这些平行线程块一起构成了所谓的 网格 。因为我有 N 元素要处理,每个块有 256 个线程,所以我只需要计算块的数量就可以得到至少 N 个线程。我只需将 N 除以块大小(注意在 N 不是 blockSize 的倍数的情况下向上取整)。
int blockSize = 256; int numBlocks = (N + blockSize - 1) / blockSize; add<<<numBlocks, blockSize>>>(N, x, y);
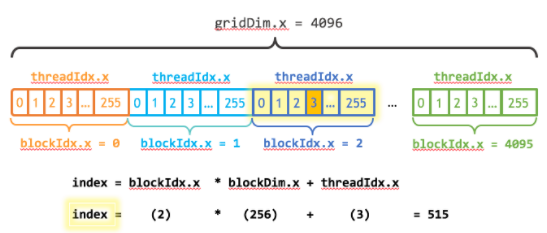
我还需要更新内核代码来考虑线程块的整个网格。 threadIdx.x 提供了包含网格中块数的 gridDim.x 和包含网格中当前线程块索引的 blockIdx.x 。图 1 说明了使用 CUDA 、 gridDim.x 和 threadIdx.x 在 CUDA 中索引数组(一维)的方法。其思想是,每个线程通过计算到其块开头的偏移量(块索引乘以块大小: blockIdx.x * blockDim.x ),并将线程的索引添加到块内( threadIdx.x )。代码 blockIdx.x * blockDim.x + threadIdx.x 是惯用的 CUDA 。
__global__ void add(int n, float *x, float *y) { int index = blockIdx.x * blockDim.x + threadIdx.x; int stride = blockDim.x * gridDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; }
更新的内核还将 stride 设置为网格中的线程总数( blockDim.x * gridDim.x )。 CUDA 内核中的这种类型的循环通常称为 栅格步幅循环 。
将文件另存为&[EZX63 ;&[编译并在&[EZX37 ;&]中运行它]
Time(%) Time Calls Avg Min Max Name 100.00% 94.015us 1 94.015us 94.015us 94.015us add(int, float*, float*)
这是另一个 28 倍的加速,从运行多个街区的所有短信 K80 !我们在 K80 上只使用了 2 个 GPUs 中的一个,但是每个 GPU 都有 13 条短信。注意,我笔记本电脑中的 GeForce 有 2 条(较弱的)短信,运行内核需要 680us 。
总结
下面是三个版本的 add() 内核在 Tesla K80 和 GeForce GT 750M 上的性能分析。
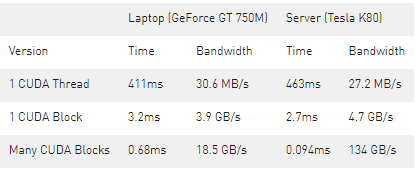
如您所见,我们可以在 GPUs 上实现非常高的带宽。这篇文章中的计算是非常有带宽限制的,但是 GPUs 也擅长于密集矩阵线性代数 深度学习 、图像和信号处理、物理模拟等大量计算限制的计算。
关于作者
Mark Harris 是 NVIDIA 杰出的工程师,致力于 RAPIDS 。 Mark 拥有超过 20 年的 GPUs 软件开发经验,从图形和游戏到基于物理的模拟,到并行算法和高性能计算。当他还是北卡罗来纳大学的博士生时,他意识到了一种新生的趋势,并为此创造了一个名字: GPGPU (图形处理单元上的通用计算)。
审核编辑:郭婷
-
NVIDIA Tesla K40C K40M 高精密并行计算GPU2014-09-02 0
-
NVIDIA CUDA 计算统一设备架构2019-03-05 0
-
并行编程模型有什么优势2019-07-11 0
-
Concurrent iHawk实时并行计算机仿真系统2020-12-29 0
-
什么是异构并行计算2021-07-19 0
-
可扩展并行计算技术、结构与编程2006-03-25 696
-
并行计算系列丛书并行计算—结构 · 算法 · 编程(修 订 版)陈国良编著2017-09-18 911
-
基于异构并行计算的两个子概念异构和并行的简单分析2018-01-25 6291
-
CUDA的异构并行计算详细资料介绍2019-07-04 585
-
Nvidia CUDA并行计算开发平台未来将不再支持苹果macOS系统开发2019-11-26 3078
-
CUDA并行计算平台的C/C++接口的简单介绍2022-04-11 1254
-
CUDA简介: CUDA编程模型概述2022-04-20 2501
-
GPU平台生态,英伟达CUDA和AMD ROCm对比分析2023-05-18 1698
-
Raspberry Pi 4B+ IoT板上的并行计算变得简单2023-06-16 349
全部0条评论

快来发表一下你的评论吧 !
