

EDA与代码实现方案及相关实验设计
EDA/IC设计
描述
数据增强可以算作是做深度学习算法的一个小trick。该介绍主要出自论文:EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks[1]
论文中的中文文本分类数据增强的代码实现可参考EDA_NLP_for_Chinese[2],当然在实际使用中可以根据具体情况再做修改。文中介绍的代码是我个人对该源码的根据我个人书写习惯进行的修改。
论文简介主要内容
这篇论文中作者提出所谓的简单数据增强(Easy Data Augmentation, EDA),包括了四种方法:「同义词替换、随机插入、随机交换、随机删除」。作者使用了CNN和RNN分别在五种不同的文本分类任务中做了实验,实验表明,EDA提升了分类效果。作者也表示,平均情况下,仅使用50%的原始数据,再使用EDA进行数据增强,能取得和使用所有数据情况下训练得到的准确率。
文中作者提出「通用的」NLP数据增强技术,命名为EDA。同时作者表示,他们是第一个给数据增强引入文本编辑技术的人。EDA的提出也是一定程度上受计算机视觉上增强技术的启发而得到。下面详细介绍EDA的四个方法:
对于训练集中的每个句子,执行下列操作:
同义词替换(Synonym Replacement, SR):从句子中随机选取n个不属于停用词集的单词,并随机选择其同义词替换它们;
随机插入(Random Insertion, RI):随机的找出句中某个不属于停用词集的词,并求出其随机的同义词,将该同义词插入句子的一个随机位置。重复n次;
随机交换(Random Swap, RS):随机的选择句中两个单词并交换它们的位置。重复n次;
随机删除(Random Deletion, RD):以 的概率,随机的移除句中的每个单词;
这些方法里,只有SR曾经被人研究过,其他三种方法都是本文作者首次提出。
值得一提的是,长句子相对于短句子,存在一个特性:长句比短句有更多的单词,因此长句在保持原有的类别标签的情况下,能吸收更多的噪声。为了充分利用这个特性,作者提出一个方法:基于句子长度来变化改变的单词数,换句话说,就是不同的句长,因增强而改变的单词数可能不同。具体实现:对于SR、RI、RS,遵循公式: = * , 表示句长, 表示一个句子中需要改变的单词数的比例。在RD中,让 和 相等。另外,每个原始句子,生成 个增强的句子。
相关实验
实验设置作者使用了5个不同的Benchmark数据集,就有了5种文本分类任务,使用了两个state-of-the-art文本分类的模型:LSTM-RNN[3]和CNNs[4]。并将有无EDA作为对比,同时因为欲得到EDA在小数据集上的实验效果,将训练数据集大小分为500、2000、5000、完整这4个量级。每个训练效果是在5个文本分类任务上的效果均值。
实验结果在完整的数据集上,平均性能提升0.8%;在大小为500的训练集上,提升3.0%。具体见如下:
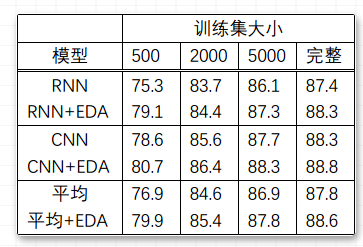
作者指出,EDA在小训练集上有更好的性能效果。若使用完整的训练集数据,不使用EDA的情况下,最佳的平均准确率达到88.3%。若使用50%的训练集数据并且使用EDA的情况下,最佳的平均准确率达到88.6%,超过前述情况。
问题总结问题1:若句子中有多个单词被改变了,那么句子的原始标签类别是否还会有效?
作者做了实验:首先,使用RNN在一未使用EDA过的数据集上进行训练;然后,对测试集进行EDA扩增,每个原始句子扩增出9个增强的句子,将这些句子作为测试集输入到RNN中;最后,从最后一个全连接层取出输出向量。应用t-SNE技术,将这些向量以二维的形式表示出来。实验结果就是,增强句子的隐藏空间表征紧紧环绕在这些原始句子的周围。作者的结论是,句子中有多个单词被改变了,那么句子的原始标签类别就可能无效了。
对于EDA中的每个方法,单独提升的效果如何?
作者做实验得出的结论是,对于每个方法在小数据集上取得的效果更明显。 如果太大的话,甚至会降低模型表现效果,=0.1似乎是最佳值。
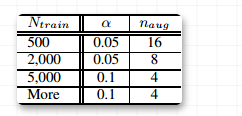
如何选取合适的增强语句个数?
在较小的数据集上,模型容易过拟合,因此生成多一点的语料能取得较好的效果。对于较大的数据集,每句话生成超过4个句子对于模型的效果提升就没有太大帮助。因此,作者推荐实际使用中的一些参数选取如下表所示,其中, :每个原始语句的增强语句个数;:训练集大小
EDA提高文本分类的效果的原理是什么?
生成类似于原始数据的增强数据会引入一定程度的噪声,有助于防止过拟合;
使用EDA可以通过同义词替换和随机插入操作引入新的词汇,允许模型泛化到那些在测试集中但不在训练集中的单词;
为什么使用EDA而不使用语境增强、噪声、GAN和反向翻译?
上述的其它增强技术作者都希望你使用,它们确实在一些情况下取得比EDA较好的性能,但是,由于需要一个深度学习模型,这些技术往往在其取得的效果面前,付出的实现代价更高。而EDA的目标在于,使用简单方便的技术就能取得相接近的结果。
EDA是否有可能会降低模型的性能?
确实有可能。原因在于,EDA有可能在增强的过程中,改变了句子的意思,但其仍保留原始的类别标签,从而产生了标签错误的句子。
中文文本分类数据增强代码实现代码实现中是需要jieba分词,停用词,以及一个提供同义词的包(Synonyms[5]),本代码参考地址:ChineseTextEDA[6]
使用方式
本代码暂时不考虑上传到pip上,本代码只需要进入chinese-text-eda目录下后,执行:
python setup.py install
即可安装使用。也可以将代码复制到项目录下使用。
在中文文本分类过程中需要使用数据增强的方式能够在数据量少的情况起到一定效果。
固定格式数据增强
该种方式提供只需要将待增强的数据处理成如下格式,然后在书写一个py脚本,在命令行运行即可。
label sentence
其中数据的标签在前,文本在后,标签和文本之间使用\t(tab)分割。
使用方式如下,python 文件为example.py
from eda import SimpleEDAEnhancesed = SimpleEDAEnhance()sed.simple_eda_enhance()
然后在控制台中输入相关参数即可。控制台输入样例如下:
python example.py --input train.txt --output eda_train.txt --num_aug 2 --alpha 0.2
相关参数说明:
--input: 原始数据的输入文件, must
--output: 增强数据后的输出文件, optional,如果未填写,会在input目录下生成一个eda开头的结果
--num_aug: 一条数据增强几条数据,optional, default 9
--alpha: 每条语句中将会被改变的单词数占比, optional, default 0.1
自定义格式数据增强
有时数据格式相对复杂,这时需要我们将增强的方法嵌入到数据处理的程序中,这时可以参考如下方法, 案例代码如下,这也是实例化EDA这个类
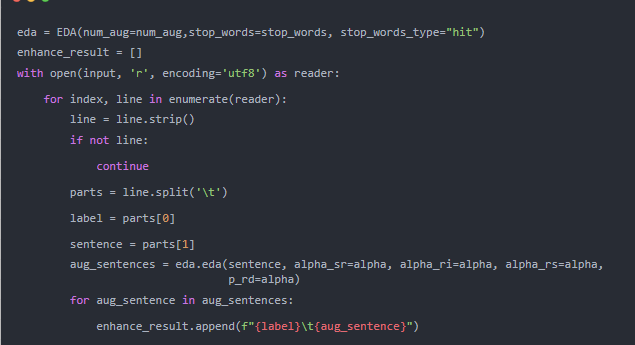
其中,EDA初始化类的参数如下:
num_aug: 一条数据增强到多少条,optional, default 9
stop_words: 增强过程使用的停用词, optional, default use hit提供的停用词
stop_words_type: 停用词类型,optional, select scope: [“hit”, “cn”, “baidu”, “scu”]
EDA类中的数据增强方法的分数如下:
sentence: must, 待增强的语句;
alpha_sr: default=0.1,近义词替换词语的比例
alpha_ri: default=0.1,随机插入词语个数占语句词语数据的比例
alpha_rs: default=0.1,随机交换词语个数占语句词语数据的比例
p_rd: default=0.1,随机删除词语个数占语句词语数据的比例
一个简单的测试如下:
from ChineseTextEDA.eda import EDAeda = EDA()res = eda.eda(“我们就像蒲公英,我也祈祷着能和你飞去同一片土地”)print(res)
结果如下:
[‘我们 就 像 蒲公英 , 我 也 天主 着 能 和 你 飞去 同 一片 土地’, ‘我们 就 像 蒲公英 , 我 也 祈祷 着 能 和 你 飞去 同 一片 土地’, ‘我们 就 像 蒲公英 , 我 也 祈祷 和 能 着 你 飞去 同 一片 土地’, ‘我们 就 像 蒲公英 , 我 也 祈祷 着 聚花 能 和 你 飞去 同 一片 土地’, ‘我们 就 像 蒲公英 , 我 也 祈祷 着 能 和 飞去 你 同 一片 土地’, ‘我们 就 像 蒲公英 , 我 也 祈祷 能 和 你 飞去 同 一片 土地’, ‘我们 就 像 , 我 也 祈祷 着 能 和 你 飞去 同 一片 土地’, ‘我们 就 像 蒲公英 , 我 也 祈祷 着 能 和 你 飞去 同 假如 一片 土地’, ‘我们 就 像 蒲公英 , 我 也 祈祷 着 能 和 你 直奔 同 一片 土地’, ‘我们 就 像 蒲公英 , 我 也 祈祷 着 能 和 你 飞去 同 一片 土地’]
Reference
[1]EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks:
https://arxiv.org/abs/1901.11196[2]EDA_NLP_for_Chinese:
https://github.com/zhanlaoban/eda_nlp_for_Chinese[3]LSTM-RNN:
https://arxiv.org/abs/1605.05101[4]CNNs:
https://arxiv.org/abs/1408.5882[5]Synonyms:
https://github.com/chatopera/Synonyms[6]ChineseTextEDA:
https://gitee.com/JackPi/chinese-text-eda/tree/dev/
-
labview实验设计2012-05-28 0
-
如何在matlab新建的GUI界面显示各种实验设计表2012-12-28 0
-
基于labview的高频电子虚拟实验设计2013-04-26 0
-
基于LabVIEW的虚拟示波器仿真实验设计2013-04-26 0
-
基于STM32CubeMX (HAL库) 的点灯和串口通信实验设计实现2022-02-18 0
-
基于FPGA开发板的矩阵键盘实验设计与实现2022-07-08 0
-
FPGA内部AD多通道采样实验设计与实现2022-07-15 0
-
实验设计基础2009-06-29 404
-
基于PCS7的过程控制实验设计_史冬琳2017-01-12 834
-
基于DSP的数字信号处理实验设计2017-02-07 700
-
基于STM32的步进电机转速控制实验设计2017-09-28 1371
-
利用Visual_Baisc实现媒体文件浏览器的实验设计2020-07-07 562
-
视频采集方案的研究现状实验设计2021-03-16 478
-
直流电压进行AD转换实验设计2021-03-17 697
-
基于单片机的简易流水灯实验设计方案2021-03-19 863
全部0条评论

快来发表一下你的评论吧 !
