

基于FPGA的边缘设备开发深度神经网络检测程序
可编程逻辑
描述
机器学习是使用算法解析数据,从中学习,然后做出决策或预测的过程。机器不是准备程序代码来完成任务,而是使用大量数据和算法“训练”以自行执行任务。
机器学习正在使用神经网络 (NN) 算法发生革命性变化,神经网络算法是我们大脑中发现的生物神经元的数字模型。这些模型包含像大脑神经元一样连接的层。许多应用程序都受益于机器学习,包括图像分类/识别、大数据模式检测、ADAS、欺诈检测、食品质量保证和财务预测。
作为机器学习的算法,神经网络包括由多个层组成的广泛的拓扑结构和大小;第一层(“输入层”)、中间层(“隐藏层”)和最后一层(“输出层”)。隐藏层对输入执行各种专用任务并将其传递到下一层,直到在输出层生成预测。
一些神经网络相对简单,只有两层或三层神经元,而所谓的深度神经网络 (DNN) 可能包含多达 1000 层。为特定任务确定正确的 NN 拓扑和大小需要与类似网络进行实验和比较。
设计高性能机器学习应用程序需要网络优化,这通常使用修剪和量化技术完成,以及计算加速,使用 ASIC 或 FPGA 执行。
在本文中,我们将讨论 DNN 的工作原理、为什么 FPGA 在 DNN 推理中越来越受欢迎,并考虑使用 FPGA 开始设计和实现基于深度学习的应用程序所需的工具。
开发 DNN 应用程序的设计流程
设计 DNN 应用程序是一个三步过程。这些步骤是选择正确的网络,训练网络,然后将新数据应用于训练模型进行预测(推理)。
如前所述,DNN 模型中有多个层,每一层都有特定的任务。在深度学习中,每一层都旨在提取不同层次的特征。例如,在边缘检测神经网络中,第一个中间层检测边缘和曲线等特征。然后将第一个中间层的输出馈送到第二层,第二层负责检测更高级别的特征,例如半圆或正方形。第三个中间层组装其他层的输出以创建熟悉的对象,最后一层检测对象。
在另一个示例中,如果我们开始识别停车标志,则经过训练的系统将包括用于检测八边形形状、颜色以及其中的字母“S”、“T”、“O”和“P”的层秩序和孤立。输出层将负责确定它是否是停车标志。
DNN 学习模型
有四种主要的学习模型:
监督:在这个模型中,所有的训练数据都被标记了。NN 将输入数据分类为从训练数据集中学习的不同标签。
无监督:在无监督学习中,深度学习模型被交给一个数据集,而没有明确说明如何处理它。训练数据集是没有特定期望结果或正确答案的示例集合。然后,NN 会尝试通过提取有用的特征并分析其结构来自动找到数据中的结构。
半监督:这包括带有标记和未标记数据的训练数据集。这种方法在难以从数据中提取相关特征时特别有用,并且标记示例对于专家来说是一项耗时的任务。
强化:这是奖励网络以获得结果并提高性能的行为。这是一个迭代过程:反馈的轮次越多,网络就越好。这种技术对于训练机器人特别有用,机器人会在诸如驾驶自动驾驶汽车或管理仓库库存等任务中做出一系列决策。
训练与推理
在训练中,未经训练的神经网络模型从现有数据中学习新的能力。一旦训练好的模型准备好,它就会被输入新数据并测量系统的性能。正确检测图像的比率称为推理。
在图 1 给出的示例中(识别猫),在输入训练数据集后,DNN 开始调整权重以寻找猫;其中权重是每个神经元之间连接强度的度量。
如果结果错误,错误将被传播回网络层以修改权重。这个过程一次又一次地发生,直到它得到正确的权重,这导致每次都得到正确的答案。
如何实现高性能 DNN 应用
使用 DNN 进行分类需要大数据集,从而提高准确性。然而,一个缺点是它为模型产生了许多参数,这增加了计算成本并且需要高内存带宽。
优化 DNN 应用程序有两种主要方法。首先是通过修剪冗余连接和量化权重并融合神经网络来缩小网络规模的网络优化。
修剪: 这是 DNN 压缩的一种形式。它减少了与其他神经元的突触连接数,从而减少了数据总量。通常,接近零的权重会被移除。对于分类 [2] 等任务,这有助于消除冗余连接,但精度会略有下降。
量化: 这样做是为了使神经网络达到合理的大小,同时实现高性能的准确性。这对于内存大小和计算数量必然受到限制的边缘应用程序尤其重要。在此类应用中,为了获得更好的性能,模型参数保存在本地内存中,以避免使用 PCIe 或其他互连接口进行耗时的传输。在该方法中,执行通过低位宽数的神经网络(INT8)来逼近使用浮点数的神经网络(FTP32)的过程。这极大地降低了使用神经网络的内存需求和计算成本。通过量化模型,我们稍微损失了精度和准确度。但是,对于大多数应用程序来说,不需要 32 位浮点。
优化 DNN 的第二种方法是通过计算加速,使用 ASIC 或 FPGA。其中,后一种选择对机器学习应用程序有很多好处。这些包括:
电源效率: FPGA 提供了一种灵活且可定制的架构,它只允许使用我们需要的计算资源。在 ADAS 等许多应用中,为 DNN 配备低功耗系统至关重要。
可重构性: 与 ASIC 相比,FPGA 被认为是原始可编程硬件。此功能使它们易于使用,并显着缩短了上市时间。为了赶上每天发展的机器学习算法,拥有对系统重新编程的能力是非常有益的,而不是等待 SoC 和 ASIC 的长时间制造。
低延迟: 与最快的片外存储器相比,FPGA 内部的 Block RAM 提供的数据传输速度至少快 50 倍。这是机器学习应用程序的游戏规则改变者,低延迟是必不可少的。
性能可移植性: 您无需任何代码修改或回归测试即可获得下一代 FPGA 设备的所有优势。
灵活性: FPGA 是原始硬件,可以针对任何架构进行配置。没有固定的架构或数据路径可以束缚您。这种灵活性使 FPGA 能够进行大规模并行处理,因为数据路径可以随时重新配置。灵活性还带来了任意对任意 I/O 连接能力。这使 FPGA 无需主机 CPU 即可连接到任何设备、网络或存储设备。
功能安全:: FPGA 用户可以在硬件中实现任何安全功能。根据应用程序,可以高效地进行编码。FPGA 广泛用于航空电子设备、自动化和安全领域,这证明了这些设备的功能安全性,机器学习算法可以从中受益。
成本效率: FPGA 是可重新配置的,应用程序的上市时间非常短。ASIC 非常昂贵,如果没有出现错误,制造时间需要 6 到 12 个月。这是机器学习应用程序的一个优势,因为成本非常重要,而且 NN 算法每天都在发展。
现代 FPGA 通常在其架构中提供一组丰富的 DSP 和 BRAM 资源,可用于 NN 处理。但是,与 DNN 的深度和层大小相比,这些资源已不足以进行完整和直接的映射;当然不会像前几代神经网络加速器中经常使用的那样。即使使用像 Zynq MPSoC 这样的设备(即使是最大的设备也仅限于 2k DSP 片和总 BRAM 大小小于 10 MB),将所有神经元和权重直接映射到 FPGA 上也是不可能的。
那么,我们如何利用 FPGA 的功率效率、可重编程性、低延迟等特性进行深度学习呢?
需要新的 NN 算法和架构修改才能在 FPGA 等内存资源有限的平台上进行 DNN 推理。
现代 DNN 将应用程序分成更小的块,由 FPGA 处理。由于 FPGA 中的片上存储器不足以存储网络所需的所有权重,我们只需要存储当前阶段的权重和参数,它们是从外部存储器(可能是 DDR 存储器)加载的。
然而,在 FPGA 和内存之间来回传输数据将使延迟增加多达 50 倍。首先想到的是减少内存数据。除了上面讨论的网络优化(剪枝和量化)之外,还有:
权重编码:在FPGA中,编码格式可以随意选择。可能会有一些准确性损失,但是与数据传输引起的延迟及其处理的复杂性相比,这可以忽略不计。权重编码创建了二元神经网络 (BNN),其中权重减少到只有一位。这种方法减少了传输和存储的数据量,以及计算复杂度。然而,这种方法只会导致具有固定输入宽度的硬件乘法器的小幅减少。
批处理:在这种方法中,我们使用流水线方法将芯片上已有的权重用于多个输入。它还减少了从片外存储器传输到 FPGA [5] 的数据量。
在 FPGA 上设计和实现 DNN 应用
让我们深入研究在 FPGA 上实现 DNN。在此过程中,我们将利用最合适的商用解决方案来快速跟踪应用程序的开发。
例如,Aldec 有一个名为TySOM-3A-ZU19EG的嵌入式开发板。除了广泛的外设,它还搭载 Xilinx Zynq UltraScale+ MPSoC 系列中最大的 FPGA,该器件具有超过一百万个逻辑单元,并包括一个运行频率高达 1.5GHz 的四核 Arm Cortex-A53 处理器。
重要的是,就我们的目的而言,这款庞大的 MPSoC 还支持赛灵思为机器学习开发人员创建的深度学习处理单元 (DPU)。
DPU 是专用于卷积神经网络 (CNN) 处理的可编程引擎。它旨在加速计算机视觉应用中使用的 DNN 算法的计算工作量,例如图像/视频分类和对象跟踪/检测。
DPU 有一个特定的指令集,使其能够有效地与许多 CNN 一起工作。与常规处理器一样,DPU 获取、解码和执行存储在 DDR 内存中的指令。该单元支持多种 CNN,如 VGG、ResNet、GoogLeNet、YOLO、SSD、MobileNet、FPN 等 [3]。
DPU IP 可以作为一个块集成到所选 Zynq®-7000 SoC 和 Zynq UltraScale™+ MPSoC 器件的可编程逻辑 (PL) 中,并直接连接到处理系统 (PS)。
为了创建 DPU 的说明,Xilinx 提供了深度神经网络开发套件 (DNNDK) 工具包。赛灵思声明:
DNNDK 被设计为一个集成框架,旨在简化和加速深度学习处理器单元 (DPU) 上的深度学习应用程序开发和部署。DNNDK是一个优化推理引擎,它使DPU的计算能力变得容易获得。它为开发深度学习应用程序提供了最佳的简单性和生产力,涵盖了神经网络模型压缩、编程、编译和运行时启用 [4] 的各个阶段。
DNNDK 框架包括以下单元:
DECENT: 执行剪枝和量化以满足低延迟和高吞吐量
DNNC: 将神经网络算法映射到 DPU 指令
DNNAS:将 DPU 指令组装成 ELF 二进制代码
N 2 Cube:充当 DNNDK 应用程序的加载器,处理资源分配和 DPU 调度。其核心组件包括 DPU 驱动程序、DPU 加载程序、跟踪器和用于应用程序开发的编程 API。
Profiler:由 DPU 跟踪器和 DSight 组成。D 跟踪器在 DPU 上运行 NN 时收集原始分析数据。DSight 使用此数据生成可视化图表以进行性能分析。
Dexplorer:为 DPU 提供运行模式配置、状态检查和代码签名检查。
DDump:转储 DPU ELF、混合可执行文件或 DPU 共享库中的信息。它加速了用户的调试和分析。
这些符合图 2 所示的流程。
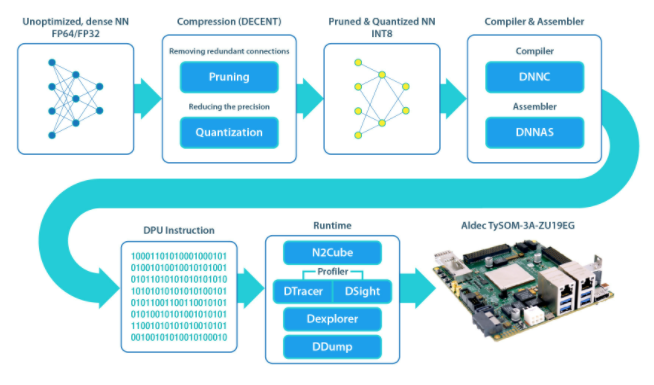
图 2.上述深度神经网络开发套件 (DNNK) 框架使基于 FPGA 的机器学习项目的设计过程对开发人员来说更加容易。
使用 DNNDK 可以让开发人员更轻松地设计基于 FPGA 的机器学习项目;此外,Aldec 的 TySOM-3A-ZU19EG 板等平台也可提供宝贵的启动功能。例如,Aldec 准备了一些针对板的示例——包括手势检测、行人检测、分割和交通检测——这意味着开发人员不是从一张白纸开始的。
让我们考虑一下今年早些时候在 Arm TechCon 上展示的一个演示。这是使用 TySOM-3A-ZU19EG 和 FMC-ADAS 子卡构建的交通检测演示,该子卡为 5 倍高速数据 (HSD) 摄像头、雷达、激光雷达和超声波传感器提供接口和外围设备——大多数人的感官输入ADAS 应用程序。
图 3 显示了演示的架构。FPGA 中实现了两个 DPU,它们通过 AXI HP 端口连接到处理单元,以执行深度学习推理任务,例如图像分类、对象检测和语义分割。DPU 需要指令来实现由 DNNC 和 DNNAS 工具准备的神经网络。他们还需要访问输入视频和输出数据的内存位置。
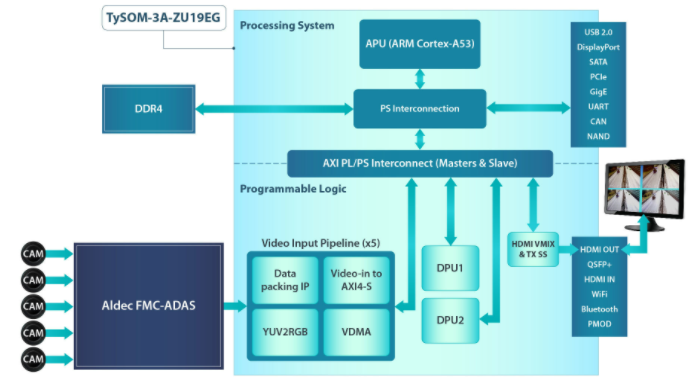
图 3. 流量检测演示具有 5 个视频输入管道,用于数据打包、AXI4 到 AXI 流数据传输、色彩空间转换 (YUV2RGB) 以及将视频发送到内存。
应用程序在应用程序处理单元 (APU) 上运行,以通过管理中断和执行单元之间的数据传输来控制系统。DPU 和用户应用程序之间的连接是通过 DPU API 和 Linux 驱动程序实现的。有一些功能可以将新图像/视频读取到 DPU、运行处理并将输出发送回用户应用程序。
开发和训练模型是使用 FPGA 之外的 Caffe 完成的,而优化和编译是使用作为 DNNDK 工具包的一部分提供的 DECENT 和 DNNC 单元完成的(图 2)。在本设计中,SSD 对象检测 CNN 用于背景、行人和车辆检测。
在性能方面,使用四个输入通道实现了 45 fps,展示了使用 TySOM-3A-ZU19EG 和 DNNDK 工具包的高性能深度学习应用程序。
审核编辑:郭婷
-
神经网络Matlab程序2009-09-15 0
-
神经网络资料2019-05-16 0
-
基于赛灵思FPGA的卷积神经网络实现设计2019-06-19 0
-
解析深度学习:卷积神经网络原理与视觉实践2020-06-14 0
-
基于带NNIE神经网络海思3559A方案边缘计算主板开发及接口定义2020-06-20 0
-
如何移植一个CNN神经网络到FPGA中?2020-11-26 0
-
基于FPGA的神经网络的性能评估及局限性2021-04-30 0
-
深度神经网络是什么2021-07-12 0
-
轻量化神经网络的相关资料下载2021-12-14 0
-
基于深度神经网络的激光雷达物体识别系统2021-12-21 0
-
卷积神经网络模型发展及应用2022-08-02 0
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 0
-
一种基于深度神经网络的基音检测算法2017-01-07 776
-
基于深度神经网络的多领域实时目标检测算法2022-11-04 1119
-
卷积神经网络和深度神经网络的优缺点 卷积神经网络和深度神经网络的区别2023-08-21 2448
全部0条评论

快来发表一下你的评论吧 !
