

GPU适合训练但不适用于推理的理由
人工智能
描述
在科技行业,如果没有人提及推理、人工智能 (AI) 和机器学习 (ML),您几乎无法进行对话。然而,重要的是要注意,虽然所有这些术语都是相互关联的,但它们也有很大的不同。
在本文中,我们将解释基本差异并强调使用基于张量处理的边缘 AI 技术的重要性,特别是在边缘和嵌入式系统中。与基于图形处理单元 (GPU) 的解决方案相比,张量处理技术 (TPU) 可提供更高效、更具成本效益的性能。我们还将提供一些示例用例,说明您将来可以在哪些地方找到边缘 AI 解决方案。
ML 和推理的基础知识
ML 是指使用代表性数据来训练模型以使机器能够学习如何执行任务的方法。这个过程可能是高度计算密集型的,每条新的训练数据都会产生数万亿次操作。训练过程的迭代特性与实现高精度所需的非常大的训练数据集相结合,推动了对极高性能浮点处理的需求。ML 培训最好作为数据中心基础设施实施,可以在许多不同的客户之间摊销,以证明高昂的资本和运营费用是合理的。
推理是使用经过训练的模型为新数据生成可能匹配的过程,该数据与模型训练所基于的所有代表性数据相关。推理旨在提供可以在几毫秒内得出的快速答案。推理的示例包括语音识别、实时语言翻译、机器视觉和广告插入优化决策。虽然推理需要一小部分的训练处理能力,但它仍然远远超出了传统的基于中央处理器 (CPU) 的系统所提供的处理能力,尤其是对于计算机视觉应用而言。这就是为什么如此多的公司正在转向基于张量的加速解决方案,无论是在 SoC 上作为 IP 还是作为系统内加速器,以实现边缘所需的亚秒级响应时间。现实情况是,在视觉系统中花费一分钟甚至几秒钟来处理图像并不是很有用。工业视觉系统正在寻求毫秒级的处理速度。
将训练与推理分开
为推理工作负载部署训练中使用的相同硬件可能意味着过度配置具有加速器和 CPU 硬件的推理机。过去十年为 ML 开发的 GPU 解决方案不一定是大规模部署 ML 推理技术的最佳解决方案。下图是 TPU 加速器与 GPU 加速器的完美示例。很明显,与基于 GPU 的 AGX 解决方案相比,TPU 加速器能够提供更低的功耗、更低的成本和更高的效率,同时仍然为推理应用程序提供令人信服的性能水平。
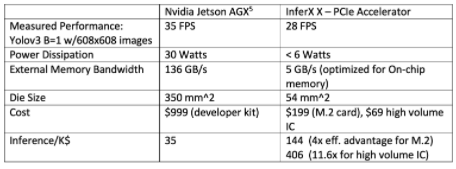
接近 ML 训练和推理解决方案时的另一个重要考虑因素是软件环境。如今,有许多流行的库正在使用,例如用于 NVIDIA GPU 的 CUDA、TensorFlow 和 PyTorch 等 ML 框架、Keras 等优化的跨平台模型库等等。这些工具集对于 ML 模型的开发和训练至关重要,但在推理应用程序方面,需要一组不同且更小的软件工具。
推理工具集专注于在目标平台上运行模型。推理工具支持将经过训练的模型移植到平台。这可能包括一些算子转换、量化和主机集成服务,但这是模型开发和训练所需的一组相当简单的功能。
推理工具受益于从模型的标准表示开始。开放式神经网络交换 (ONNX) 是表示 ML 模型的标准格式。顾名思义,它是一个开放标准,并作为 Linux 基金会项目进行管理。ONNX 等技术允许训练和推理系统解耦,并为开发人员提供了为训练和推理系统选择不同优化平台的自由。
示例视觉应用
随着 ML 和推理处理器技术的不断进步和发展,应用层出不穷。以下只是您将来可能会看到这项技术的几个地方。
工厂、医院、零售店、金融机构等企业的边缘服务器。例如,在工业领域,人工智能可用于帮助管理库存、检测缺陷,甚至在缺陷发生之前进行预测。在零售领域,它可以启用姿势估计等功能,使用计算机视觉技术检测和分析人体姿势。从该分析中获得的数据可以使实体零售商更好地了解其商店中的人类行为和人流量,从而使他们能够以最大限度地提高零售额和客户满意度的方式开设商店。
适用于机器人、工业自动化/检测、医学成像、科学成像、监控和物体识别相机、光子学等应用的高精度/高质量成像。 例如,机器学习方法已被证明可以通过处理数字 X 射线来检测癌症。这样做的过程是开发一个 ML 模型,该模型旨在处理 X 射线图像,通常使用经过训练的语义分割算法来检测癌症。在训练阶段,放射科专家识别出的癌症图像用于训练网络以了解什么不是癌症、什么是癌症以及不同类型的癌症是什么样子。训练的 ML 模型越多,它们在最大化正确诊断和最小化错误诊断方面就越好。这意味着机器学习既依赖于智能模型设计,但同样重要的是依赖于大量(如数十万到数百万)精心策划的数据示例,其中癌症已被专家识别。
智能购物车——几家公司正在开发和部署能够识别产品的智能购物系统,而不是通过其 UPC 条形码,而是通过包装本身的视觉外观。此功能允许购物者只需将产品放入卡中或将其放在结帐系统上,而无需查找 UPC 代码并使用 UPC 激光扫描仪进行扫描。这项技术使购物过程更准确、更快捷、更方便。
做出正确的决定
公司需要评估当今所有可用的解决方案,并根据其特定用例做出最佳选择。他们也不能仅仅假设所有 AI 解决方案都最好在 GPU 设备上实现,因为基于 TPU 的解决方案提供了更高的处理效率和更低的硅利用率,从而降低了功耗和成本。
审核编辑:郭婷
-
gdb7没有MI接口,不适用于Eclipse CDT2019-01-18 0
-
STM8S发现示例不适用于Raisonance2019-04-15 0
-
STVP擦除选项不适用于STM8S105K42019-05-20 0
-
专用乘法器不适用于FPGA2019-05-29 0
-
为什么ST PMSM FOC库不适用于ARM-GCC?2019-07-02 0
-
充分利用Arm NN进行GPU推理2022-04-11 0
-
请问STM32H743 DMA不适用于ADC是何原因呢2023-01-03 0
-
高级中断不适用于IDF V5.0吗?2023-03-02 0
-
PN7161 NFC不适用于nrf52840吗?2023-04-21 0
-
yolov5训练的tflite模型进行对象检测不适用于NNStreamer 2.2.0-r0?2023-05-17 0
-
S32K118EVB不适用于PE Micro Multilink Universal FX吗?2023-05-18 0
-
jscrane/TTS库不适用于NodeMCU 1.0吗?2023-06-01 0
-
车和家创始人李想:互联网思维不适用于造车2018-05-14 2820
-
边缘生成式人工智能推理技术现状2023-09-28 1077
-
芯曜途科技发布适用于MEMS传感器阵列的STN100近感AI推理芯片2023-12-15 757
全部0条评论

快来发表一下你的评论吧 !
