

音频边缘处理器提供上下文感知音频体验
今日头条
描述
在过去十年,视频通话和语音设备的参与度大幅增加,主要是通过大流行造成的在家工作趋势。但是,我们对视频通话的使用不仅限于工作 Zoom 会议。我们现在正在使用视频通话进行教学、锻炼课程、体验现场音乐、作为在会议上进行互动的工具等等。这种虚拟参与通过笔记本电脑、智能手机、平板电脑、家庭助理和其他物联网设备(如 Amazon Echo Show、Facebook Portal、Peloton、Tempo Studio 等)进行。
限制令人愉快和引人入胜的交互式音频、视频通话或家庭助理体验的一个因素是在存在噪音和其他干扰物的情况下保持一致的音质。设备智能管理声音的能力决定了您的沟通能力。
提高音频和语音的复杂性需要新技术
被产品制造商称为“智能声音”的音频智能是设备处理声音以提供最佳用户体验的能力。随着用于通信、娱乐和健康管理的语音优先设备的增加,对具有更多功能的无缝、低障碍体验的需求也在增加。
用户现在希望设备能够理解的不仅仅是简单的唤醒或关键字(例如 Alexa),并寻求能够以卓越的音质在设备和应用程序之间移动,以实现身临其境的无缝体验,无论是用于专业会议还是个人娱乐。设备应该能够将您的语音和/或语音命令与您的个人偏好和环境数据相结合,以使声音处理适应您的特定环境。这被称为情境意识。
情境意识解释
上下文感知设备结合用户特定信息,例如位置、偏好和环境传感器数据,以更好地了解用户的要求并更准确地执行功能以响应特定命令或触发器。
常听设备使用信号处理技术结合 机器学习 (ML) 来区分声音类型,例如自然声音、声音、背景干扰等。这些声音通常分为“场景”和“事件”。场景是用户设置,例如嘈杂的机场航站楼或安静的工作空间,而事件包括有人说话、玻璃破碎或狗吠。情境感知设备可以处理这些声音组,以确保行动的意图,无论是视频通话还是语音命令,以获得最佳体验。
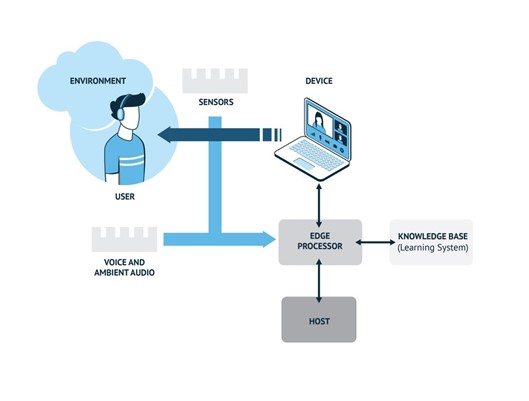
上下文感知系统示意图(图片:Knowles Corp.)
为什么要使用专用音频边缘处理器?
具有 ML 优化内核和专注于音频保真度的专用音频边缘处理器是支持上下文感知和高质量音频通信设备的关键。这些处理器可以提供足够的计算能力来使用传统和 ML 算法处理音频,同时使用通用数字信号处理 (DSP) 实现的一小部分能量。
虽然云可能提供一些巨大的好处,但边缘处理允许用户随时利用其设备的全部功能,而无需高带宽的互联网连接。例如,边缘音频处理器通过对具有上下文数据的音频进行低延迟处理,同时保持上下文数据的本地和安全,从而在虚拟通信中实现卓越的用户体验。
了解专业的音频边缘处理器
音频边缘处理器必须具备多项功能才能提供卓越的音频和语音命令体验。
噪音和距离
波束成形,使用信号处理算法,将声音集中或引导到特定方向,以提高音质,而噪声抑制使日常场景中的对话成为可能。听音设备确定语音和噪声源的方向。ML 分类技术用于确定哪些波束中有语音或噪声。
然后,DSP 将注意力集中在具有语音内容的波束上,仅用于进一步的语音 UI 处理。例如,在会议系统中,设备必须识别声音的方向,并且必须始终以 360 度的方式跟踪多个扬声器。噪声源还可以分类用于音频事件检测,如玻璃破碎、火灾警报等,进一步将其作用扩展到音频感知智能家居系统。
接近检测对于动态的听力和口语体验也是必不可少的。该设备检测用户靠近麦克风并调整麦克风的增益。此功能支持用于演示、锻炼和学习环境的活动视频会议。这些功能是高级视频会议设备设计的核心,例如亚马逊的新 Echo Show,它的屏幕随着用户的移动而旋转,因此屏幕始终面向用户。
潜伏
在我们开始互相交谈之前,人类 通常可以容忍 长达 200 毫秒的端到端延迟。因此,边缘处理器中的低延迟处理是确保高质量语音通信的关键要求。
能量消耗
采用专有架构、硬件加速器和特殊指令集设计的音频边缘处理器可以优化运行音频和机器学习算法。这些优化有助于降低音频密集型用例(如视频会议)的功耗。
一体化
开放其架构和开发环境的音频边缘处理器通过为音频应用程序开发人员提供创建新设备和应用程序的工具和支持来加速创新。未来的音频设备将是协作的成果。
安全
边缘处理可以最大限度地减少对云连接的需求,并提供许多好处,包括提高数据安全性。例如,大多数消费者对来自个人智能家居设备的数据不断传输到云端进行处理感到不舒服。 过去几年领先设备制造商的几起重大违规事件已证明这些担忧是真实 的。
在设备上处理个人数据以进行分析或推理时,可以让您高枕无忧。一个很好的例子是智能家居安全设备,它经过训练可以听到某些事件的声音,例如玻璃破碎,作为提醒房主的触发器。由于声音和警报的处理发生在边缘处理器上,它不需要持续连接到云端,从而增强了系统的安全性。
结论
专用的音频边缘处理器将定义下一代音频和语音设备,创造更多的情境感知、身临其境和无缝的音频通信体验。它们能够实现低功耗和低延迟语音通信的高效处理、降噪、上下文感知和传感器输入的加速 ML 推理,这为人机界面新用户体验的爆炸式增长提供了可能性。
关于作者:
 Raj Senguttuvan 是一位具有电气工程背景的成功创新和商业领袖。Raj 在消费和工业应用的新技术开发、早期业务开发以及多家半导体公司的项目管理方面拥有超过 15 年的经验。
Raj Senguttuvan 是一位具有电气工程背景的成功创新和商业领袖。Raj 在消费和工业应用的新技术开发、早期业务开发以及多家半导体公司的项目管理方面拥有超过 15 年的经验。
作为 Knowles 战略营销总监,Raj 负责指导音频解决方案战略、推动风险投资和合作伙伴关系以及物联网和消费技术(包括音频处理器、算法、麦克风、传感器和接收器)的营销。
Raj 拥有康奈尔大学的 MBA 学位和佐治亚理工学院的电气工程博士学位。
 Vikram Shrivastava 在半导体和技术行业的产品营销、战略和管理方面拥有近 30 年的经验。Vikram 在电气工程方面的教育背景,特别是在控制系统和硅设计方面,使他能够理解、执行和传达适合工程师、开发人员和 OEM 的技术需求的营销策略。
Vikram Shrivastava 在半导体和技术行业的产品营销、战略和管理方面拥有近 30 年的经验。Vikram 在电气工程方面的教育背景,特别是在控制系统和硅设计方面,使他能够理解、执行和传达适合工程师、开发人员和 OEM 的技术需求的营销策略。
Vikram 目前担任 Knowles 物联网营销高级总监一职,他开发战略和产品,以使物联网平台具有智能语音功能。
Vikram 拥有加州大学伯克利分校哈斯商学院的 MBA 学位。
审核编辑 黄昊宇
-
关于进程上下文、中断上下文及原子上下文的一些概念理解2018-09-06 0
-
进程上下文与中断上下文的理解2018-12-11 0
-
JavaScript的执行上下文2019-05-29 0
-
进程上下文/中断上下文及原子上下文的概念2021-01-13 0
-
中断中的上下文切换详解2023-03-23 0
-
基于多Agent的用户上下文自适应站点构架2009-04-11 430
-
基于交互上下文的预测方法2009-10-04 402
-
移动设备的个性化推荐在上下文感知应用2010-01-15 517
-
终端业务上下文的定义方法及业务模型2010-03-06 487
-
基于Pocket PC的上下文菜单实现2011-07-25 703
-
传感器提供上下文感知的物联网和物联网应用2017-05-22 791
-
基于上下文相似度的分解推荐算法2017-11-27 713
-
基于上下文语境的词义消歧方法2018-01-12 814
-
如何分析Linux CPU上下文切换问题2022-05-05 1659
-
网络安全中的上下文感知2022-09-20 1861
全部0条评论

快来发表一下你的评论吧 !
