

一种简单而有效的转换方法来降低预测情感标签的难度
描述
01
研究动机
面向目标的多模态情感分类(TMSC)是方面级情感分析的一个新的子任务,旨在预测一对句子和图片中提到的意见目标的情感极性。该任务背后的假设是图片信息可以帮助文本内容识别意见目标的情感。图1给出了两个代表性的示例。我们可以看到仅仅根据非正式的简短句子很难检测出意见目标的情感,但与意见目标相关的视觉内容(即笑脸)可以清晰地反映其情感极性。
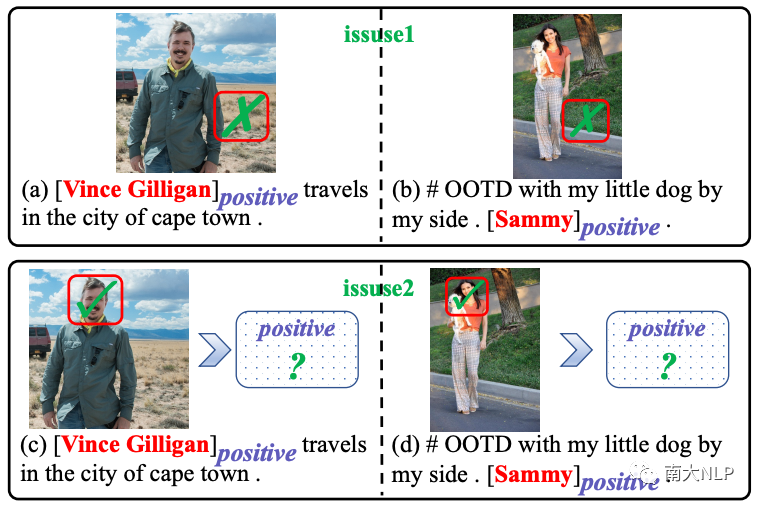
图1:面向目标的多模态情感分类 (TMSC) 的两个示例。意见目标及其相应的情感极性在句子中突出显示。红色边框表示意见目标关注到的视觉线索。
从上面的示例中我们可以看出,对齐两种模态的意见目标并捕获有用的视觉情感特征在TMSC任务中起着至关重要的作用。鉴于其重要性,主流的工作采用了注意力机制来自动学习文本和图片的对齐关系,然后将捕获的意见目标的视觉表示聚合为证据来进行情感预测。
尽管取得了一些改进,但上述方法仍然存在两个关键问题:
(1)由于文本和图片中意见目标的粒度存在很大的差距,之前的这些方法很难对齐两种模态。具体来说,图片中出现的意见目标通常是指粗粒度的对象(例如,图片中的man),而句子中的意见目标通常是细粒度的实体(例如,人名 “Vince Gilligan)。意见目标粒度的不一致导致视觉注意力有时无法捕捉到相应的视觉表征。
(2)即使捕获到了,表达相同情绪的多样化视觉表示也给情感预测带来了很大的挑战。以图1(c)和图1(d)为例,意见目标“Vince Gilligan”和“Sammy”分别关注了图片中的粗粒度对象man和girl,从他们的面部表情我们可以看出他们都在微笑,但微笑的角度和幅度却大不相同。视觉表示的多样性不可避免地导致其稀疏性,这使得学习视觉表示和情感标签之间的映射函数变得困难。
在这项工作中,我们提供了解决上述问题的新思路,即利用从图片中提取的形容词-名词对 (ANPs) . (例如图2(a)中的“nice clouds”, “bad car”, “happy man”, “clear sky” 和“dry grass”)。对于第一个问题,我们观察到 ANPs 中的名词也是粗粒度的概念,因此一个很直观的想法是将细粒度的意见目标(例如“Vince Gilligan”)映射到粗粒度名词中(例如“man”)。
通过这种方式更容易弥合两种模态的粒度差距并对齐文本和图片。对于第二个问题,我们观察到 ANPs 通常可以从表达相同情绪的不同视觉内容中提取到相同的形容词,因此一个很直观的想法是将多样化的视觉表征(例如笑脸)映射到同一个形容词(例如“happy”)。显然,学习这些相同形容词和情感标签之间的映射函数更容易。
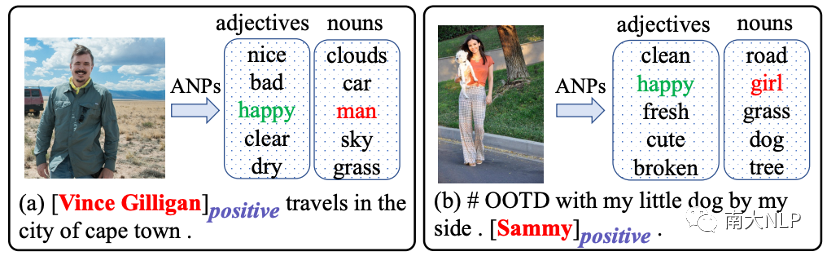
图2:从每个图片中提取前 5 个形容词-名词对 (ANPs)
为了使用 ANPs 促进 TMSC 任务,我们提出了一个知识增强框架(简称KEF), 它主要包含两个组件:视觉注意力增强器和情感预测增强器。前者首先使用我们设计的映射方法从 ANPs 中找到与意见目标最相关的名词,然后用它来提高视觉注意力的有效性。后者的目的是建立形容词和目标相关视觉表示之间的联系,然后将其用作视觉表示的补充信息,以降低预测情感标签的难度。
02
贡献
1.据我们所知,我们是第一个提出利用从图片中提取的形容词-名词对 (ANPs) 来帮助TMSC 任务对齐文本和图片的工作;
2.我们提出了一种新颖的知识增强框架(KEF),它包含一个视觉注意力增强器来提高视觉注意力的有效性,以及一个情感预测增强器来降低情感预测的难度。
3.KEF 具有良好的兼容性,很容易组合或者扩展到现有的基于注意力的多模态模型。在这项工作中,我们将其应用于两个最新的 TMSC 模型:SaliencyBERT[6]和 TomBERT[2]。 两个公开数据集的实验结果证明了我们框架的有效性。
03
解决方案
图 3 展示了 KEF 的整体架构,主要包含两个组件:视觉注意力增强器和情感预测增强器。具体来说,我们首先基于TomBERT[2] 和 SaliencyBERT模型抽象出一个通用的注意力架构。然后,在 ANPs 的帮助下,我们依次提出了视觉注意力增强器和情感预测增强器。前者旨在通过映射方法和重构损失来提高视觉注意力的有效性,后者引入了一种简单而有效的转换方法来降低预测情感标签的难度。
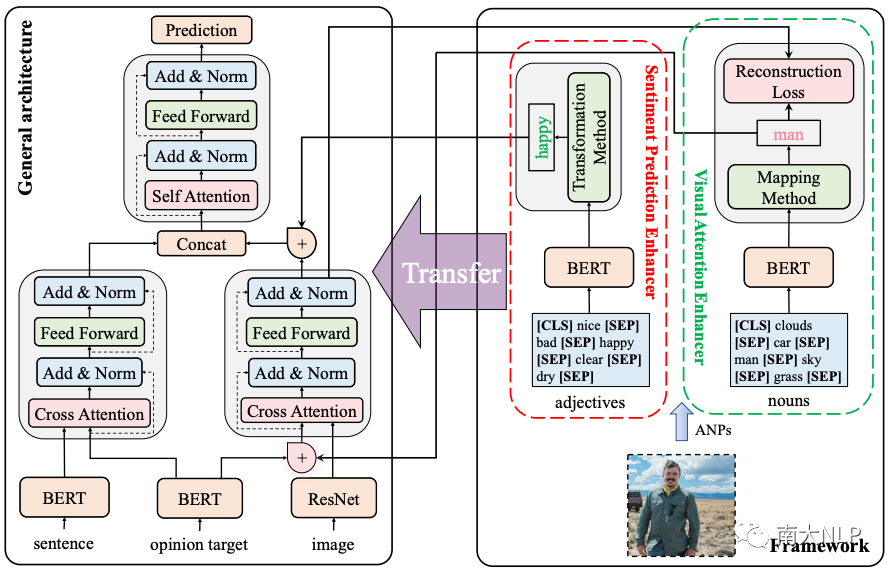
图3:知识增强框架(KEF)的整体架构
3.1 视觉注意力增强器
问题
如前所述,图片中出现的意见目标是一个粗粒度的概念,而句子中提到的意见目标是一个细粒度的概念,意见目标粒度的不一致导致了视觉注意力有时无法捕获到相应的视觉表示。
基本的直觉
显然,从图片中提取出来的名词也是粗粒度的概念,所以一个直观的想法是将细粒度的意见目标映射到粗粒度的名词上,然后将它作为桥梁来捕获粗粒度的视觉特征.。但是,从图片中提取的大部分名词都是与意见目标无关的,因此我们不能直接使用它们。
映射方法(Mapping Method.)
为了应对上述挑战,我们首先通过计算嵌入空间中名词表示和目标表示之间的语义相似度来衡量目标-名词相关性的强度:
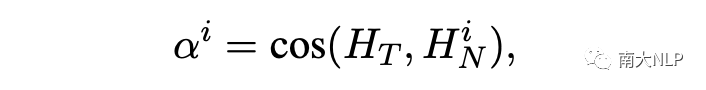
根据最大相似度得分,我们可以找到与意见目标最相关的名词:
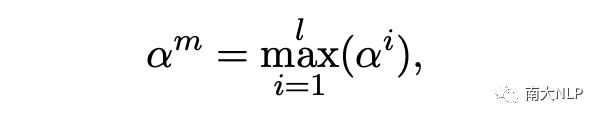
接下来,我们将它们聚合在一起作为意见目标的补充信息以捕获相应的视觉表示:
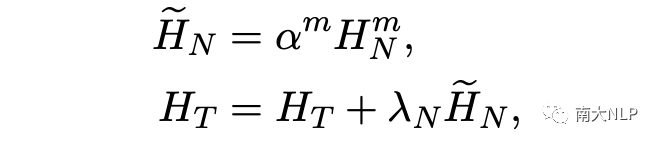
重构损失(Reconstruction Loss.)
为了确保视觉注意力能够更准确地捕获到与意见目标相关的视觉特征,我们还设计了一种重构损失来最小化目标相关名词表示和目标相关视觉表示之间的差异:
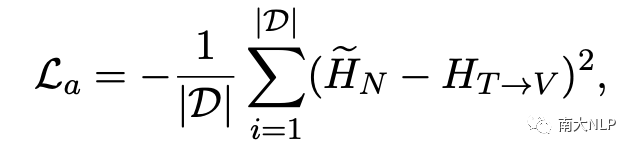
3.2 情感预测增强器
问题
即使视觉特征被捕获到了,但是表达相同情绪的视觉表征之间仍然存在显着差异,这给学习视觉表征和情感标签之间的映射函数带来了挑战。
基本的直觉
考虑到 ANPs 通常可以从表达相同情绪的不同视觉表征中提取相同的形容词,因此一个直观的想法是将多样化的视觉表征映射到同一个形容词。然而,与视觉表示最相关的形容词是未知的,我们需要明确地找到它。
转换方法(Transformation Method.)
实际上,在映射方法中,我们发现名词表示与目标感知视觉表示最相关。由于形容词是名词的修饰语,因此与该名词对应的形容词也与目标感知视觉表示最相关。最后,我们将其用作视觉表示的补充信息,以降低情感预测的难度: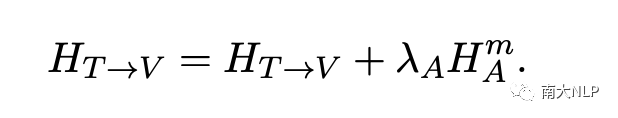
04
实验
我们在两个公开的数据集Twitter2015和Twitter2017上进行了实验,并且使用准确率 (Accuracy) 和 Macro-F1 分数作为评估指标。KEF 包含两个即插即用的组件,可以轻松组合或扩展到现有的基于注意力的方法。为了更好地验证 KEF 的有效性,我们选择了两个最近的基于 BERT 的多模态模型作为我们工作的基础,即 TomBERT 和 Saliencybert。
换句话说,我们将 KEF 集成到TomBERT 和 Saliencybert 中,得到最终模型 KEF-TomBERT 和 KEF-Saliencybert。从表1可以看出,KEF-Saliencybert 和 KEF-TomBERT 在 TWITTER-15 和 TWITTER-17 数据集上均取得了具有竞争力的结果。
具体来说,与TomBERT 相比,KEF-TomBERT 在 Macro-F1 和 Accuracy 分别获得了大约 2.0% 和 1.5% 的改进。相比之下,KEF-Saliencybert 的表现平均优于Saliencybert 1.5% 和 1.7%。这些结果表明我们的框架具有良好的兼容性。此外,在大多数情况下,KEF-TomBERT 的表现优于KEFSaliencybert,这表明我们的框架对 TomBERT 更有效。
表1:主实验结果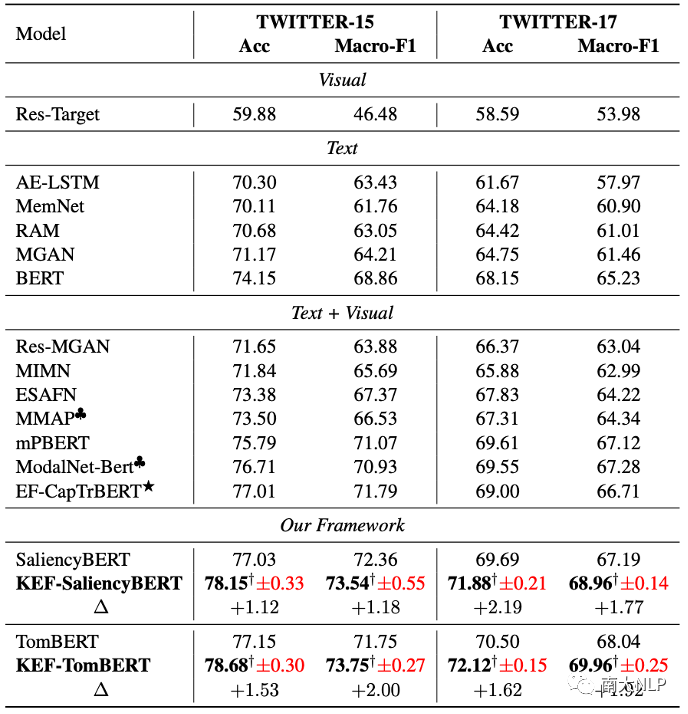
在不失一般性的情况下,我们选择 KEF-TomBERT 模型进行消融实验,以研究 KEF 中单个模块对模型整体效果的影响。视觉注意力增强器简称VAE,情感预测增强器简称SPE。根据表 2 报告的结果,我们可以观察到以下几点:
表2:消融实验结果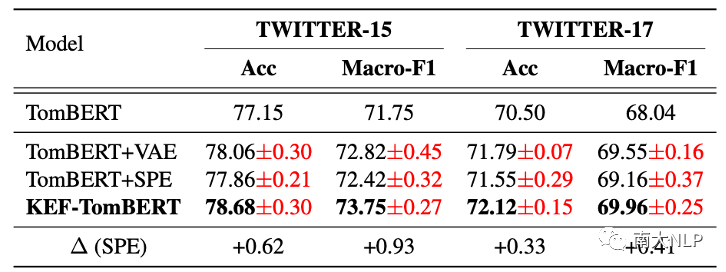
1. 与基础模型 TomBERT 相比,TomBERT+VAE 和TomBERT+SPE在两个数据集上均取得了具有竞争力的表现,这验证了利用形容词-名词对提高视觉注意力能力和情感预测能力的合理性;
2. 将SPE集成到TomBERT+VAE后,KEF-TomBERT实现了state-of-the-art的性能,这证明了SPE可以通过形容词-名词对提高情感预测能力;
3. VAE 比 SPE 更有效,这是合理的因为注意力机制的有效性是情感预测的核心因素。因此,它对我们的框架贡献更大;
4. 如图 4 所示,我们可以看到 KEF-TomBERT 学习到的多模态表示明显比 TomBERT+VAE 学习的更可分离,这表明SPE确实可以降低情感预测的难度。
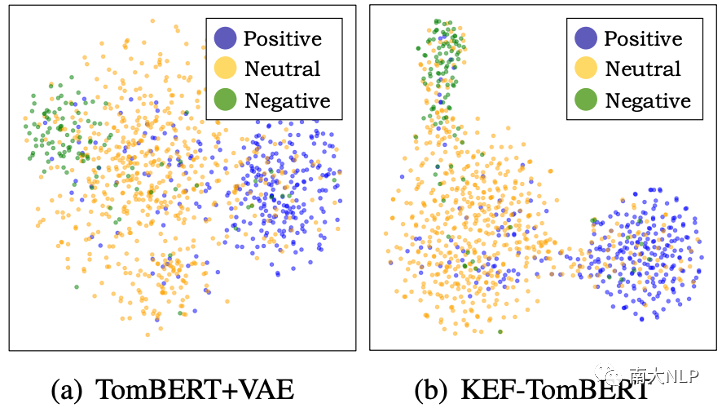
图4:TomBERT+VAE 和 KEF-TomBERT 的多模态表示的可视化
为了验证 ANPs 对 KEF-TomBERT 模型的影响,我们从每张图片中提取前 1、3、5 和 7 个 ANPs进行了实验,结果如图 5 所示。显然,随着 ANPs 数量的增加,KEF-TomBERT 的性能变得更好。而且当 ANPs 的数量等于 5 时,KEF-TomBERT 的效果最好。
但是,一旦 ANP 的数量大于 5,性能就不会继续增加,甚至开始下降。这背后的原因可能是:每个句子最多包含5个意见目标,所以当ANPs的数量大于意见目标的最大数量时会带来一些噪音。
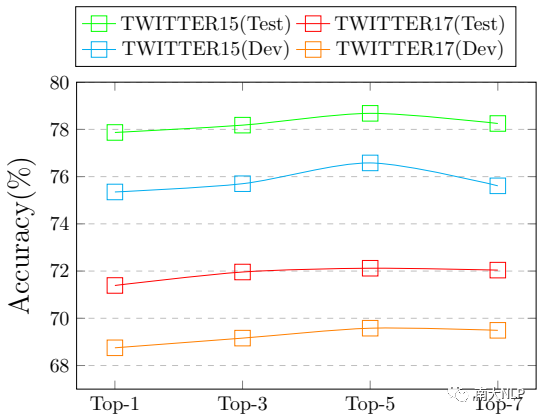
图5:不同数量 ANPs 对KEF-TomBERT的影响
05
案例分析
为了更好地理解视觉注意力增强器 (VAE) 和情感预测增强器 (SPE) 的优势,我们从 Twitter 数据集中随机选择一些样本进行案例研究。
视觉注意力增强器的影响
如图 6(a) 所示,基础模型 TomBERT 错误地预测了意见目标“Korkie”的情感。这是合理的因为我们发现 TomBERT关注了与意见目标无关的视觉线索(由黄色边界框突出显示)。在将 VAE 集成到 TomBERT 之后,TomBERT+VAE将细粒度的意见目标“Korkie”映射到 ANPs 中的粗粒度名词“man”。在名词“man”的帮助下,TomBERT+VAE 成功地捕捉到了目标相关的视觉线索(由红色边界框突出显示),从而给出了正确的预测。
情感预测增强器的影响
如图 6(b) 和6(c) 所示,虽然 TomBERT+VAE 准确地捕捉到了意见目标的相应视觉表征(即笑脸),但微笑表情的多样化增加了情感预测的难度,因此 TomBERT +VAE 错误地预测了图 6(c) 中“Sammy”的情感。在将 SPE 集成到 TomBERT+VAE 之后,KEFTomBERT 将不同的笑脸映射到同一个形容词“happy”。显然,KEF-TomBERT 更容易学习这些“happy”和情感标签“positive”之间的映射函数,从而做出正确的预测。
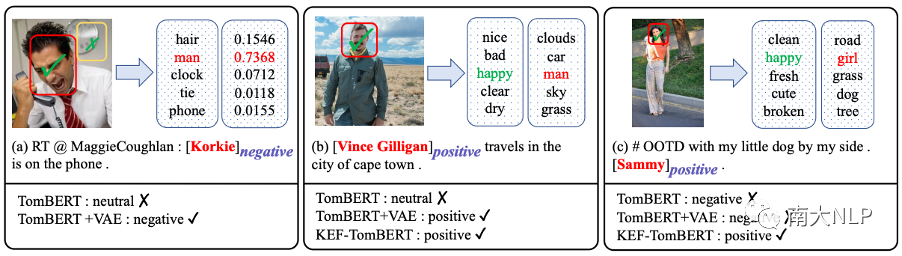
图6:案例分析
06
总结
在本文中,我们为 TMSC 任务提出了一种新颖的知识增强框架 (KEF)。具体来说,在 ANPs 的帮助下,我们设计了两个新颖的知识增强器,视觉注意力增强器和情感预测增强器,以提高 TMSC 任务的视觉注意力能力和情感预测能力。大量实验的结果表明,我们的框架与其它最先进的方法相比具有更好的性能。进一步的分析也验证了我们框架的优越性。
在未来,我们希望将我们的想法应用于其他多模态任务,因为从图片中提取的形容词-名词对很容易扩展到其他多模态任务,例如多模态实体链接、多模态机器理解和多模态对话生成。
审核编辑:刘清
-
一种有效的可转换的认证加密方案2009-06-14 0
-
一种简单的逆变器输出直流分量消除方法2011-12-27 0
-
一种简单有效的限流保护电路的设计2012-08-20 0
-
是否有一种方法来确定GPIF接口在等待GPIF主机的数据时干还是空2019-05-27 0
-
简单而有效的电源时序控制方法介绍2019-07-03 0
-
有没有一种方法来配置MPLAX X来从RAM运行应用程序?2019-09-12 0
-
请问有另一种方法来测量RTD传感器而不使用IDAC吗?2019-10-11 0
-
介绍一种解决overconfidence简洁但有效的方法2022-08-24 0
-
特征选择在减少预测推理时间方面的有效性展示2022-09-07 0
-
一种更通用的方法来监测处理器中的电压噪声2022-11-01 0
-
探索一种降低ViT模型训练成本的方法2022-11-24 0
-
软件驱动程序是否有一种相当简单的方法来检测安装了哪个rtc设备?2023-04-06 0
-
是否有一种“简单”的方法来增加允许的“打开”文件的最大数量?2023-05-15 0
-
一种实现高性能锂金属电池的简单而有效的策略2022-09-20 688
-
一种简单的方法来将振荡器相位噪声转换为时间抖动2023-11-23 89
全部0条评论

快来发表一下你的评论吧 !
