

JEDEC定义了四种主要类型的DRAM
电子说
描述
内存层次结构的变化是稳定的,但是访问内存的方式和位置会产生很大的影响。
数据的指数增长和对提高数据处理性能的需求催生了各种新的处理器设计和封装方法,但它也推动了内存方面的巨大变化。
虽然底层技术看起来仍然非常熟悉,但真正的转变在于这些存储器与系统内处理元件和各种组件的连接方式。这会对系统性能、功耗甚至整体资源利用率产生重大影响。
多年来出现了许多不同类型的存储,尽管有一些交叉和独特的用例,但大多数都有明确的用途。其中包括 DRAM 和 SRAM、闪存和其他专用存储器。DRAM 和 SRAM 是易失性存储器,这意味着它们需要电源来维护数据。非易失性存储器不需要电力来保留数据,但读/写操作的数量是有限的,并且它们会随着时间的推移而磨损。
所有这些都适合所谓的内存层次结构,从SRAM开始——一种非常快速的内存,通常用于各种级别的缓存。SRAM 速度极快,但由于每比特成本高,其应用受到限制。同样在最低级别,通常嵌入到 SoC 或连接到 PCB 的 NOR 闪存通常用于启动设备。它针对随机访问进行了优化,因此它不必遵循任何特定的存储位置顺序。
在内存层次结构中向上移动一步,DRAM是迄今为止最受欢迎的选择,部分原因是它的容量和弹性,部分原因是它的每比特成本低。这部分是由于领先的 DRAM 供应商已经全面折旧他们的晶圆厂和设备,但随着新型 DRAM 的上线,价格一直在上涨,为新的竞争对手打开了大门。
几十年来,人们一直在谈论要取代 DRAM,但事实证明,从市场的角度来看,DRAM 比任何人预期的都要更有弹性。在高带宽内存(HBM) 的 3D 配置中,它也被证明是一种极快、低功耗的选择。
JEDEC 定义了四种主要类型的 DRAM:
标准内存的双倍数据速率 (DDRx);
低功耗 DDR (LPDDRx),主要用于移动或电池供电设备;
图形 DDR (GDDRx),最初是为高速图形应用程序设计的,但也用于其他应用程序,以及
高带宽内存 (HBMx),主要用于高性能应用,例如 AI 或数据中心内部。
与此同时,NAND 闪存通常用作可移动存储(SSD/USB 记忆棒)。由于较长的擦除/写入周期和较低的使用寿命,闪存不适合 CPU/GPU 和系统应用。 “内存标准机构 JEDEC 正在完善双倍数据速率 (DDR5) 和低功耗版本的 LPDDR5 规范,”西门子 EDA解决方案产品工程师 Paul Morrison 说。“DDR6 和 LPDDR6 也在开发中。其他流行的 DRAM 内存包括高带宽内存(HBM2 和 HBM3)和图形 DDR(GDDR6,即将发布 GDDR7)。” 但小型电池供电设备的增长以及对设备快速启动的需求也推高了对闪存的需求。NOR 闪存通常更小,约为 1 Gbit。相比之下,NAND 闪存用于 SSD。密度现在从每单元一位到每单元四位不等,预计每单元有五位和六位版本。此外,从 2D 到 3D 阵列的转变进一步增加了密度。 “在 AI 和许多其他领域,内存性能对于良好的系统性能至关重要,” Rambus的研究员和杰出发明家 Steven Woo 说。“以最高数据速率运行内存将提高系统性能,但考虑数据结构如何映射到内存可以提高带宽、功率效率和容量利用率。增加内存容量还可以带来更好的性能,而 CXL 的引入将为 AI 和其他处理器提供一种方式来增加内存容量,这超出了直连内存技术目前所能提供的范围。”
距离很重要
内存和处理器之间的距离曾经是一个平面规划问题,但随着需要处理的数据量的增加以及功能的缩小,在内存和处理器之间来回移动更多数据所需的能量元素增加。更细的电线需要更多的能量来移动电子,而将它们移动更长的距离需要更多的能量并增加延迟。 这引发了对近内存和内存计算的新兴趣,其中至少一些数据可以被分区和优先处理、处理和显着减少。这减少了使用的能源总量,并且可能对性能产生重大影响。 内存计算 (又名内存处理或内存计算)是指在内存(例如 RAM)内进行处理或计算。前段时间,在芯片级完成此操作之前,已经证明通过将数据分布在多个 RAM 存储单元并结合并行处理,在投资银行等案例中的性能提高了 100 倍。因此,虽然内存/近内存计算已经存在了很长时间,并且从 AI 设计中得到了又一次推动,但直到最近芯片制造商才开始展示这种方法的一些成功。 2021 年,三星的内存业务部门推出了在 HBM 内存中集成 AI 内核的内存处理 (PIM) 技术。在使用 Xilinx Virtex Ultrascale 和 (Alveo) AI 加速器的语音识别测试中,PIM 技术能够实现 2.5 倍的性能提升和 62% 的能耗降低。SK 海力士和美光科技等其他存储芯片制造商也在研究这种方法。 在内存计算领域,最近获得博士学位的万维尔领导的国际研究团队宣布了一项突破性进展。毕业于斯坦福大学 Philip Wong 的实验室,他在加州大学圣地亚哥分校从事这个想法。其他博士为这项研究做出重大贡献的加州大学圣地亚哥分校的毕业生现在在圣母大学和匹兹堡大学经营自己的实验室。 通过将神经形态计算与电阻式随机存取存储器紧密结合,NeuRRAM 芯片以高精度执行 AI 边缘计算——在 MNIST 手写数字识别任务上的准确率达到 99%,在 CIFAR-10 图像分类任务上达到 85.7%。与当今最先进的边缘 AI 芯片相比,NeuRRAM 芯片能够提供低 1.6 到 2.3 倍的能量延迟积(EDP;越少越好)和高 7 到 13 倍的计算密度。这为降低运行各种 AI 任务的芯片的功率提供了机会,同时又不影响未来几年的准确性和性能。 “提高内存性能的关键因素之一一直是最大限度地减少数据移动,”西门子 EDA 技术产品经理 Ben Whitehead 说。“通过这样做,它还可以降低功耗。以 SSD 为例,一次数据查找可以将传输速度提高 400 到 4000 倍。另一种方法是将计算移到内存附近。内存计算的概念并不新鲜。在内存中添加智能将减少数据移动。该概念类似于边缘计算,通过执行本地计算而不是来回将数据发送到云。DRAM 中的内存计算仍处于早期阶段,但这将继续成为未来内存发展的趋势。”
内存标准更新
目前正在进行的三个主要标准组/工作可能会对所有这些产生重大影响: JEDEC:组织继续其 50 多年来作为微电子行业内存标准领导机构的角色。它开发并发布了许多标准,重点关注主内存(DDR4 和 DDR5 SDRAM)、闪存(UFS、e.MMC、SSD、XFMD)、移动内存(LPDDR、Wide I/O)等。它将继续成为内存标准的主导机构。 JEDEC 最近发布了两个新标准。2022 年 8 月,它发布了 DDR5 SDRAM 规范,该规范定义了 x4、x8 和 x16 DDR5 SDRAM 设备的 8 Gb 到 32 Gb 的最低要求。这项工作是基于 DDR4 标准以及部分 DDR、DDR2、DDR3 和 LPDDR4 标准完成的。此外,2021 年 7 月 JEDEC 增加了 LPDDR5 和 LPDDR5X,定义密度范围从 2 Gb 到 32 Gb 的 x16 单通道 SDRAM 设备和 x8 单通道 SDRAM 设备的最低要求。这项工作是根据以前的规范完成的,包括 DDR2、DDR3、DDR4、LPDDR、LPDDR2、LPDDR3 和 LPDDR4。 CXL:CXL联盟是一个开放的行业标准组,支持 Compute Express Link ( CXL ),这是一种行业支持的高速缓存一致性互连,用于处理器、内存扩展和加速器。该技术定义了 CPU 内存空间和附加设备上的内存之间的互连,以实现资源共享,这可以提高性能,同时最大限度地降低软件和系统成本。它还有助于定义 AI/ML 中使用的加速器。该联盟最近发布了 CXL 2.0 规范,该规范增加了开关功能,以启用设备扇出、内存扩展、扩展、内存池、链路级完整性和数据加密 (CXL IDE) 以保护数据。 UCIe:在小芯片方面是最近发布的通用小芯片互连快速(UCIe) 标准。芯片制造商将继续采用 UCIe 连接小芯片,包括存储器。当前的重点包括物理层(具有行业领先 KPI 的芯片到芯片 I/O)和协议 (CXL/PCIe),以确保互操作性。 “CXL 帮助加速器与系统的其他部分保持一致,因此传递数据、消息和执行信号量更加高效,”英特尔高级研究员兼 CXL 联盟委员会技术任务组主席 Debendra Das Sharma 说。“此外,CXL 解决了这些应用程序的内存容量和带宽需求。CXL 将推动内存技术和加速器的重大创新。”
关于性能优化的想法
其中一些内存方法已经存在了几十年,但没有什么是静止的。内存仍然被视为功率、性能和面积/成本范式中的关键元素,权衡可能会对所有这些元素产生重大影响。 “内存技术不断发展,”西门子 EDA 产品经理 Gordon Allan 说。“例如,HBM 是目前 AI 应用程序的完美选择,但明天可能会有所不同。主要内存标准机构 JEDEC 定义了 DDR4 和 5、DIMM 4 和 5、LRDIM 以及当今的其他内存。但对于未来的内存扩展,用于定义 PCIe 和 UCIe 接口的 CXL 标准正在获得认可和发展势头。” 每个处理器都需要内存来存储数据。因此,了解内存的特性及其行为将如何影响整体系统性能非常重要。设计和选择存储器的一些关键考虑因素包括:
在给定的能量单位内最大化性能;
功率预算和热管理;
将内存与处理需求相匹配,例如需要更高内存性能的 AI 系统,以及重复使用设计、密度和封装(2D、2.5D、3D-IC)
根据应用程序,考虑数据如何在系统内和系统之间传输也很重要。 “要优化性能,您需要关注系统级别,” Cadence DDR、HBM、闪存/存储和 MIPI IP 集团产品营销总监 Marc Greenberg 说. “为了让您的系统实现高吞吐量,它可能需要 80 多个内存连接到处理器。有不同的方法可以提高效率。其中之一是优化流量访问的顺序,并在给定时钟频率下以最小总线周期完成的任务数量最大化。一个简单的类比是杂货店的结账过程。例如,客户有五罐菠萝、一个西瓜和其他东西。为了提高结账效率,您可以将所有五个罐头作为一组呈现,而不是先呈现一个罐头,然后是西瓜,然后是另一个罐头。同样的概念也适用于内存。此外,在一个点上拥有一个智能内存控制器(PHY 和控制器 IP)来管理多个内存的流量协议将在内存设计中实现更好的优化。” 人工智能在许多设备中的推出使这些考虑变得更加重要。 “在 AI 训练中,提供最高带宽、容量和功率效率的存储器很重要,”Rambus 的 Woo 说。“HBM2E 内存非常适合许多训练应用,尤其是大型模型和大型训练集。使用HBM2E的系统实现起来可能更复杂,但如果可以容忍这种复杂性,那么它是一个不错的选择。另一方面,对于许多推理应用程序来说,需要高带宽、低延迟和良好的功率效率,同时具有良好的性价比。对于这些应用,GDDR6 内存可能更适合。对于物联网等端点应用,也可以与 LPDDR 结合使用的片上存储器是有意义的。”
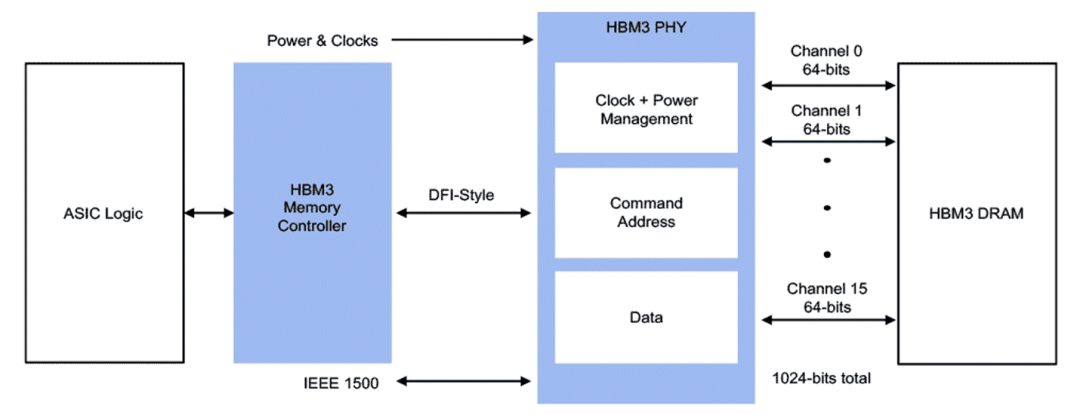
HBM 内存控制器和 PHY IP 优化了内存管理功能 根据美光的说法,内存系统比看起来更复杂。在给定的内存带宽内,系统性能可能会受到访问模式、位置和解决时间等因素的影响。例如,自然语言处理模型需要 50 TB/s 的内存带宽来支持 7mS 的延迟时间来解决问题。如果可以容忍更长的延迟,则可以相应地调节它们的内存带宽。 美光指出,架构会随着对解决方案堆栈的全面了解而得到改进——从软件到架构再到内存系统。因此,出发点是优化算法内的访问模式、数据放置和延迟缓解(即数据预取),同时利用内存架构的固有优势并解决其局限性。 JEDEC 不断改进内存,以应对更高密度、低延迟、低功耗、更高带宽等挑战。通过遵循规范,内存制造商和系统设计人员将能够利用新的创新。近年来,来自 Synopsys 和 Siemens EDA 等公司的先进工具已可用于执行所需的功能,例如测试、仿真和验证。 “JEDEC 的目标之一是继续提供支持进一步扩展的架构创新,”新思科技定制设计与制造集团的产品营销总监 Anand Thiruvengadam 说。“更新的内存规格将继续实现更高的密度、更低的功耗和更高的性能。例如,DDR4 的电源要求是 1.2V,而 DDR 5 是 1.1V。在此电压缩放期间,必须考虑信号完整性和如何打开眼图等因素。热管理也得到了改进。DDR5 每个引脚有两到三个温度传感器,比只有一个的 DDR4 有所改进。因此,遵循规范是有益的。” 但遵循规范是一回事。满足规范是另一回事。“根据规范测试产品很重要,确保它通过所有最坏的情况,”Thiruvengadam 说。“复杂的分析和模拟可能需要数周时间。幸运的是,更新的仿真软件解决方案可以将这一时间缩短到几天。”
结论
JEDEC 将继续定义和更新存储器规格,涵盖 DRAM、SRAM、FLASH 等。随着 CXL 和 UCIe 标准的加入,内存开发社区将受益于未来的系统和小芯片互连。尽管 UCIe 相对较新,但它有望在生态系统中开辟小芯片的新世界。 此外,预计 AI/ML 将继续推动对高性能、高吞吐量内存设计的需求。持续的斗争将是平衡低功耗要求和性能。但涉及内存计算的突破将为世界带来更快的发展加速。更重要的是,这些先进的内存开发将有助于推动未来基于人工智能的边缘和端点 (IoT) 应用。
审核编辑 :李倩
-
FPGA 设计的四种常用思想与技巧2012-08-11 0
-
FPGA设计的四种常用思想与技巧2012-08-20 0
-
PADS封装中的四种库2015-03-06 0
-
四种无线充电技术简单原理2016-07-28 0
-
四种常用的FPGA设计思想与技巧2017-11-05 0
-
大数据的四种思维方式2019-08-12 0
-
四种波形发生器2020-03-11 0
-
USB的四种传输类型2020-10-09 0
-
IO口的四种使用方法2021-01-12 0
-
四种主要的负电源轨生成方案如何选择2021-03-11 0
-
单片机四种输入模式2021-08-24 0
-
变频器主要支持四种模式2021-09-03 0
-
C++中的四种类型转换分别是哪些?C++中析构函数的作用是什么2021-12-24 0
-
为什么四种DDR验证BIST测试类型无法执行并且颜色编码指示?2023-04-06 0
全部0条评论

快来发表一下你的评论吧 !
