

用于中文缩略词预测的序列生成模型研究
描述
研究背景
缩略词是单词或短语的缩写形式。为了方便写作和表达,在文本中提及某个实体时,人们倾向于使用缩写名称而不是它的完整形式(名称)。理解缩略词,尤其是实体的缩写名称,是知识图谱构建和应用的关键步骤。缩略词处理主要包括三个任务:缩略词扩展,缩略词识别和提取,以及缩略词预测。毫无疑问,缩略词处理在各种自然语言处理 (NLP) 任务中发挥着重要作用例如信息检索、实体链接等任务。
在本文中,我们重点关注缩略词处理的第三个任务,即缩略词预测,其目标是预测实体完整形式的可能缩写形式。缩略词实际上是一个子序列,由一个词或一些字符按完整形式的顺序排列。不同于英文缩略词(通常是首字母缩略词),中文缩略词形式更加复杂多样。
如表 1 所示,缩略词可以是位于实体完整形式中的第一个词(“复旦”)也可以是最后一个词(“迪士尼”),并且可能包含实体中一些不连续但有序的字符(“北大”)。而且,一个实体的缩略词可以有多种形式(“央视”或“中央台”)。因此,作为一项更具挑战性的任务,中文缩略词预测已成为近年来的研究热点。

▲ 表1. 中文缩略词的几个实例
现有的中文缩略词预测方法可以被认为是基于特征的方法。它们通常是将缩略词预测作为序列标记问题,即对每个 token 作二分类,去判断是否该字符是否应保留在缩略词中。尽管取得了成就,但以前的方法仍然有以下缺点:一方面,他们只使用转移矩阵来寻找最高概率的标签,未能充分利用标签依赖关系;另一方面,他们忽略了实体相关文本的丰富信息,只利用实体本身的语义。事实上,我们可以获取足够的与给定实体相关的文本例如百度百科文本、景点 POI 实体评论和 query 文本,能提供模型预测缩写的信号。
为了解决这些问题,我们将中文缩略词预测看作从全称实体序列到缩略词序列的定长机器翻译任务。贡献包括,首先,我们提出了一种用于中文缩略词预测的序列生成模型。其次,我们将实体相关上下文纳入中文缩略词预测任务,为模型提供了更多语义信息。最后,我们构建了旅游中文缩略词数据集。此外,我们在飞猪搜索系统上部署的缩略词实现了 2.03% 的转化率提升。
研究框架
问题建模:针对给定的一个全称实体 和其对应的相关文本,CETAR 能生成一个其对应的缩略词序列。
模型框架:我们的模型框架由上下文增强编码器和缩略-恢复解码器组成。图 2 是 CETAR 模型架构框架图。

▲ 图2:基于上下文增强和缩略-恢复策略的缩略词transformer框架图
2.1 上下文增强编码器
首先,将实体的完整形式 x 及其相关文本 d 都输入到这个模块。使用与 BERT 相同的初始化操作得到初始 embedding,以及它们的位置 embedding 一起输入 transformer encoder block,生成一些重要的特征表示。为了减少数据的噪音,最终只取实体对应的隐状态输入到解码器当中,以便后续的解码。

2.2 缩略-恢复解码器
这是我们模型生成缩略词序列的关键模块。它是用 transformer decoder block 和缩写及恢复策略对应的两个分类器分别构成。整个解码过程是实际上是一个迭代的过程。具体来说,在每一轮开始时,输入上一轮过程输出的由 n+2 个 token 组成的 token 序列。然后,每个 token 的初始 embedding 附加其位置 embedding,伴随着解码器的输出 H, 然后输入第一个 transformer decoder block。最后,我们将最后一个 block 输出的隐藏状态作为后续两个分类器的输入。

随着所有标记的隐藏状态,缩写分类器或恢复分类器判断序列中哪个 token 应该缩写或恢复。在第k轮解码过程中,缩写分类器首先判断序列中的每个 token 是否应该缩写。类似地,恢复分类器判断序列中每个特殊的缩略词*是应该保留还是恢复到相同位置的源 token。如下式所示,其中:

缩略分类器:

恢复分类器:

最后,缩略词序列中的所有 * 都被删除,并且因此我们得到了源实体的最终缩略词。
实验结果
我们将 CETAR 与基线模型在三个中文缩写数据集上进行了比较,其中两个属于通用领域,一个属于特定的景点领域。后者是基于阿里飞猪景点 POI 实体及其别名构建的中文缩略词数据集。对于通用领域的数据集中的实体,我们选取了其百度百科描述性文本的第一句话作为相关文本;而对于飞猪中文缩略词数据集中的景点 POI 实体,我们则是以其最相关的评论文本及 query 文本作为相关文本。
至于评价指标,首先,我们使用 Hit 作为指标来比较模型的性能。测试样本被视为命中样本如果它的预测缩写和它 ground-truth 缩写一模一样。而 Hit score 是命中样本占所有测试样本的比例。此外,考虑到一些实体有多个缩写,我们进一步考虑了以下指标,这些指标是基于对从测试集中随机选择的 500 个样本的人工评估计算得出的,包括正确样本、NA、NW 和 WOM 在所有人类评估样本中的比例。
具体来说,NA 表示预测的缩略词是正确的,但和 ground-truth 的缩略词不同。NW 代表错误且语言结构异常的预测缩略词,而 WOM 代表错误但语言结构正常的预测缩略词。具体实例可见表 2。
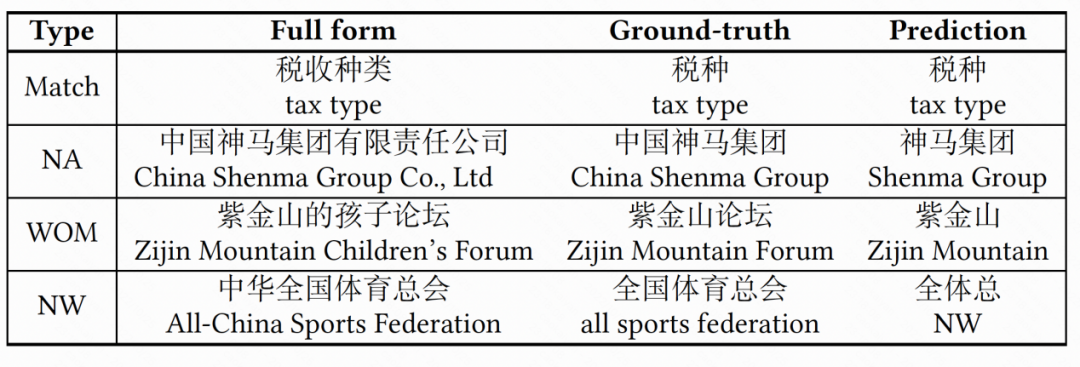
▲ 表2: 缩略词的四种不同形式实例
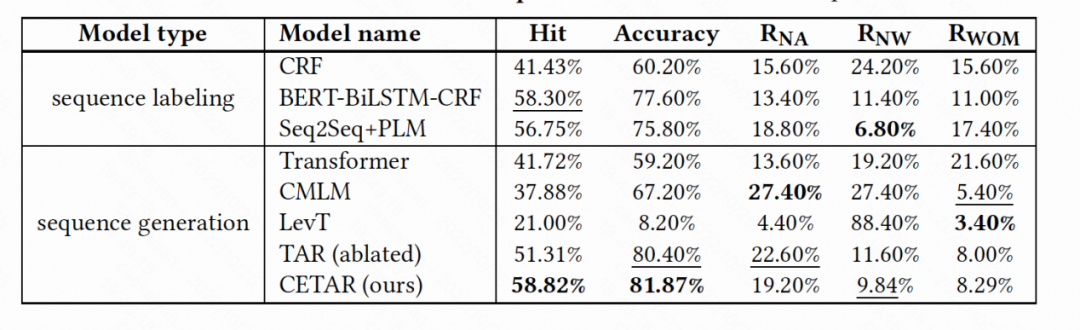
▲ 表3: 数据集一各模型表现

▲ 表4: 数据集二和数据集三各模型表现
从表 3 和表 4,我们得到以下结论:
1. 在命中率和准确性方面,我们的 CETAR 在通用领域数据集( 和 )和特定领域数据集()上都优于所有基线。
2. 所有模型的 NW 分数几乎都高于其 WOM 分数,说明不正确的分词是导致错误预测的主要原因。因此,单词边界的信息对于准确的缩略词预测非常重要。
3. 我们还发现,大多数模型在 上的准确度得分都优于 和 。这是因为旅游 POI 的缩写通常由完整形式的连续标记组成,例如“杭州西湖风景区-西湖”,而一般领域的实体缩略词通常由不连续的标记组成。前者更容易让模型实现准确的预测。

▲ 表5: CETAR 针对数据集二中输入实体不同长度的文本(摘要)预测结果
3.1 消融实验
事实上,输入过多的文本可能会产生过多的噪音,也会消耗更多的计算资源。为了寻求输入文本的最佳长度,我们比较了 CETAR 在 D2 上输入百度百科实体摘要的前 1∼4 个句子时的性能。
表 5 表明,输入摘要的第一句表现最好。通过对从数据集中随机抽取的 300 个样本的调查,我们发现大约 75.33% 的第一句话提到了源实体的类型。这也证明了实体类型是促使 CETAR 生成正确缩略词序列的关键信息。

▲ 表6: CETAR 针对数据集三中输入实体不同长度的文本(评论)预测结果

▲ 表7: CETAR 针对数据集三中输入实体不同长度的文本(query)预测结果
同样,作为数据集三(表 6 & 表 7),CETAR 在将语义最相关(第一个)的评论或查询集作为相关文本时取得了最佳性能。通过深入调查,我们发现热门评论(查询)更有可能包含目标实体的缩略词,帮助 CETAR 实现更准确的预测。
3.2 应用
为了验证缩略词在搜索系统中提高召回率和准确捕捉用户搜索意图的有效性,我们将 CETAR 预测的 56,190 个 POI 实体的缩略词部署到飞猪的搜索系统中。然后,我们进行了持续 4 天的大规模 A/B 测试,发现处理桶与对照桶相比,获得了 2.03% 的 CVR 提升。那为什么有意义呢?例如,基于精确关键字匹配的搜索系统不会为查询“迪士尼乐园”返回酒店“上海迪士尼乐园酒店”,因为酒店的名称与查询不完全匹配。但是,如果预先将“迪士尼”识别为“迪士尼度假区”的缩略词,则可以更轻松地将酒店与查询相关联。
总结
在本文中,我们提出了用于中文缩略词预测的 CETAR,它利用了与源实体相关的信息上下文。CETAR 通过迭代解码过程生成准确的缩略词序列,其中缩略分类器和恢复分类器交替工作。我们的实验证明了 CETAR 优于 SOTA 方法的中文缩略词预测。此外,我们在景点领域成功构建了一个中文缩略词数据集,并已部署在现实世界的飞猪搜索系统上。系统的在线A/B测试实现了CVR的显著提升,验证了缩略词在促进业务方面的价值。
审核编辑:郭婷
- 相关推荐
- nlp
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 0
-
基于小波的灰色动态组合模型及其在变形预测中的应用2010-04-24 0
-
GPRS小区流量预测中时序模型的比较研究2010-05-06 0
-
经济预测模型2011-08-15 0
-
开发和设计实现LSTM模型用于家庭用电的多步时间序列预测相关资料分享2021-07-05 0
-
介绍有关时间序列预测和时间序列分类2021-07-12 0
-
怎样去搭建一套用于多步时间序列预测的LSTM架构?2021-07-22 0
-
为什么生成模型值得研究2021-09-15 0
-
自回归滞后模型进行多变量时间序列预测案例分享2022-11-30 0
-
LabVIEW进行癌症预测模型研究2023-12-13 0
-
表面活性剂常用缩略词释义2010-10-03 912
-
usb术语和缩略词2008-06-17 1050
-
离散序列AR模型定阶方法研究衡思坤2017-03-15 504
-
小波回声状态网络的时间序列预测2018-01-13 766
-
船舶自动识别系统轨迹序列预测模型2021-05-07 577
全部0条评论

快来发表一下你的评论吧 !
