

介绍ICRA 2022中关于事件相机的几篇文章
描述
本文介绍ICRA 2022中关于事件相机的几篇工作,由于是关键字查找,可能有遗漏,且能力有限文章难免出现疏漏,请读者批判性阅读并指出问题。
[1] Asynchronous Optimisation forEvent-based Visual Odometry
本文面向纯事件(不需要frame)和无地图(map-free),提出了在SE(3)上的单目视觉里程计VO,核心思想是采用增量式最大后验(MAP)优化。 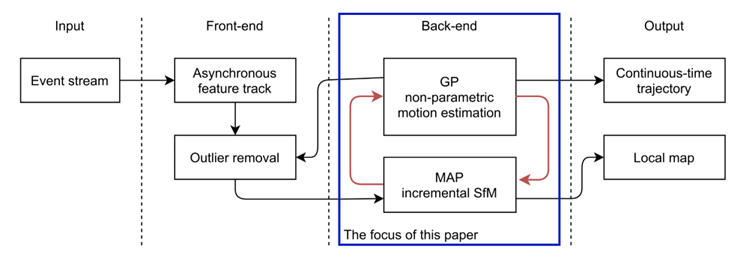
上图清晰指出了本文的主要贡献,在SLAM框架中,针对后端的优化,采用增量式SfM和高斯过程(GP)迭代,计算出地图和轨迹。本人认为,这个图做的非常好,值得学习借鉴,非常直观的告诉了读者本文的主要工作。
围绕后端的优化问题,文章在相关工作部分总结了优化时不同的batching策略,分成了frame-based(固定时间/数量)、event-driven(逐事件)和event-drivenand tracking(事件驱动和跟踪的),见下图。 
核心的算法涉及了较多数学知识,感兴趣请查阅原文。但文章指出方法的缺陷是计算量较大(由于涉及了迭代等操作),在1min左右的数据上计算时间约10min。
[2] Learning Local Event-basedDescriptor for Patch-based Stereo Matching
本文的主要工作是提出了两种在双目配准中event的编码和配准方法。分别是“高效表示和网络(Efficiency representation/Net)”以及“精准表示与网络(Accuracyrepresentation/Net)”。
在表示上,高效表示采用了voxel-grid的方式进行切片,精准表示则将一段时间内的event生成6个channel的图片:两种极性的x-y,x-t,y-t图。在配准网络上,高效网络采用了全2D卷积的方式提高计算速度,精确网络则包含了Squeeze-and-Excitation层以提高特征的recalibration。
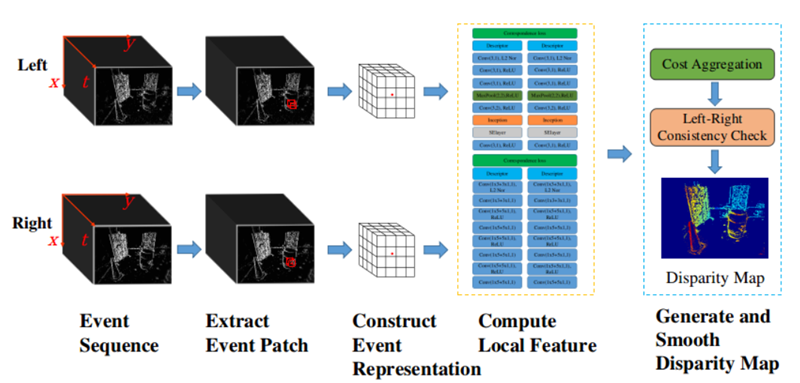
[3] Kinematic Structure Estimation ofArbitrary Articulated Rigid Objects for Event Cameras
本文解决的是rigid object的kinematic structure(KS)任务。对这个不太了解,我的理解是分析出刚体的结构并对其运动进行提取,如下图。 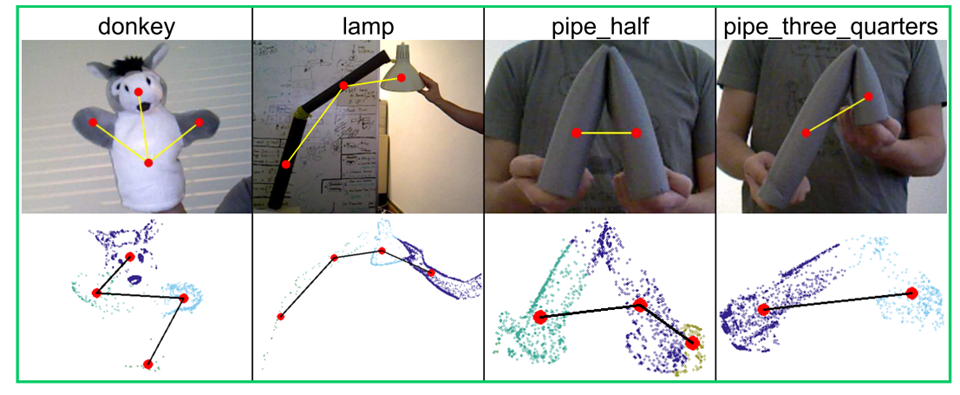
核心算法是叫做“增量式基于事件的运动估计”,基本原理由这两个作者在2020和21年两篇文章中提出[A1][A2]。由于不了解,本推送不做展开介绍。
[4] Fusing Event-based and RGB camerafor Robust Object Detection in Adverse Conditions
提出了一种针对不同条件(主要是图像质量降低)的融合frame和event的目标检测算法。算法的核心是从RGB和event中提取特征,再经过FPN(FeaturePyramid Net)网络进行融合,以实现不同尺度上的检测。 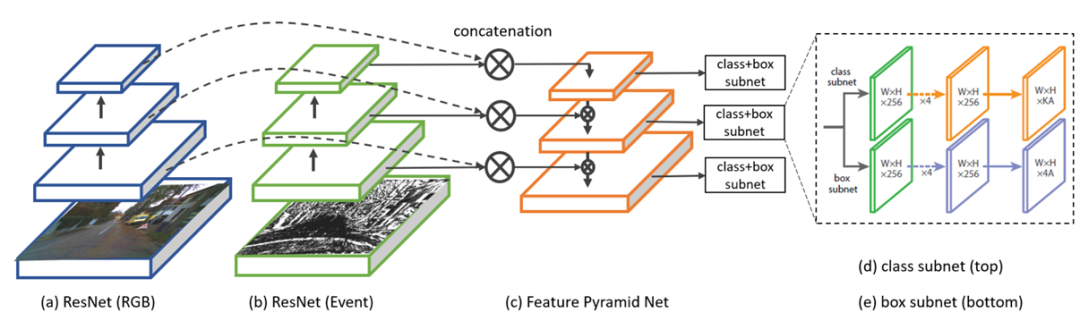
从上图可以看出,网络结构很简单,RGB图采用了ResNet提取特征,Event通过voxel-grid的方式成图后也提取特征,之后不同尺度的特征通过FPN进行检测。
值得提一句的是,本文所提出的图像质量降低是基于[A3]给出的图像15种降质,包括噪声、模糊、天气和数字化四类。但作者实验时,将DSEC数据集的图片降质后使用,而并没有处理event对应的数据,因此我认为存在不合理之处。但作者做了event-only实验的对比,验证了融合低质图像的有效性。
另外,我最近看到了不少FPN网络在event融合中的使用,各位可以关注下。
[5] A Linear Comb Filter for EventFlicker Removal
这篇文章很有趣,采用梳齿滤波器对事件的抖动进行去除,具体来说是消除了日光灯50hz频闪产生的噪声。作者是Ziwei Wang,熟悉的朋友应该知道她之前和Cedric有不少合作,基本上都是围绕滤波的。

图:日光灯频闪前后的事件热度图(下)和重建图(上) 文章的核心算法是“梳齿滤波器”,这种滤波器形似梳子,抑制特定频率整数倍的信号,而对非特定频率的信号影响不大。
作者提出了前向后向反馈的梳齿滤波器,抑制50hz的周期信号。所设计的系统框图和伯德图见下。 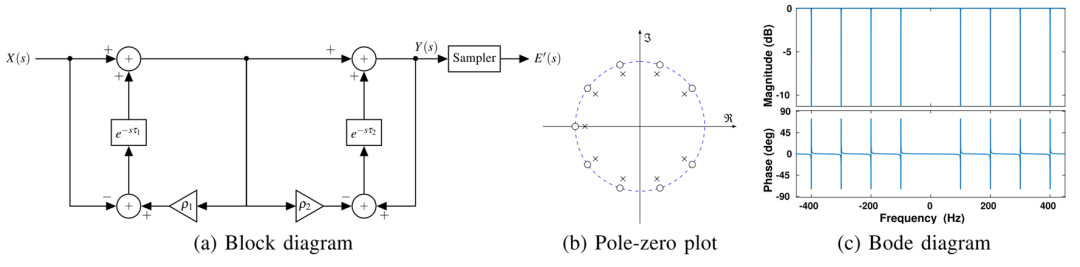
文章很有趣,但我也指出两个问题供读者思考:1. 文章看起来需要保持相机和灯管相对静止,如果有运动怎么办,是否可以扩展?2. 从热度图上可以看出仍然没有去除全部的噪声,原因是什么,是否是由于事件的jitter或on/off的不一致造成的,是否可以优化?
[6] DEVO: Depth-Event Camera VisualOdometry in Challenging Conditions
本文提出了一种事件相机+深度相机的VO算法,基本思想是使用RGBD提供了深度,更方便地帮助event相机建立地图与位姿估计。
关于这篇文章,今年2月在arxiv上看到了作者上传的预印本,并在之前的推送中做了详细介绍,本次推送不做展开。
[7] VISTA 2.0: An Open, Data-drivenSimulator for Multimodal Sensing and Policy Learning for Autonomous Vehicles
这篇文章并不算严格意义上的事件相机研究,只是做了个面向policy-learning的仿真器,涉及了event的生成。推送简单介绍:文章提出了一种基于虚拟视角的方法,对现有的实际场景数据集进行合成,合成了不同视角下的image和Lidar,并利用改进的ESIM方法生成了event数据。做无人驾驶相关的朋友如感兴趣可以进一步了解。
审核编辑:刘清
-
机器视觉中工业相机与民用相机的区别志强视觉科技 2023-12-05
-
几篇关于MATLAB的论文2011-01-07 0
-
求几篇关于MP3播放器制作的英文文献2013-03-19 0
-
(分享)给想了解CRC校验的朋友们推荐几篇文章2014-01-20 0
-
关于LabVIEW数据采集和处理的几篇学位论文2015-03-27 0
-
Labview软件与工业相机的兼容技术介绍2015-11-18 0
-
分享几篇最新获得的成果论文2016-10-22 0
-
相机标定——张正友文献原文2018-05-04 0
-
ICRA 2018 DJI RoboMaster 人工智能挑战赛报名正式启动2018-05-15 0
-
STM32下推式磁悬浮装置介绍2021-07-20 0
-
2022中国开源发展蓝皮书(简体中文版本)2022-07-21 0
-
LG InnoTek或为2022款iPhone供应潜望式相机2020-12-09 1334
-
几篇不错的BLE技术文章分享2020-12-16 1629
-
国际顶级机器人盛会ICRA 2022看点2022-05-26 5886
-
ESC的具体功能介绍2022-08-16 5801
全部0条评论

快来发表一下你的评论吧 !
