

基于优化的元学习方法
描述
1. 简介
Prompt通过将输入文本填入预设prompt模板的方式,将下游NLP任务形式与语言模型预训练任务统一起来,来更好地利用预训练阶段学习到的知识,使模型更容易适应于下游任务,在一系列NLP任务上取得了很好的效果[1]。Soft prompt方法使用可学习的参数来替代prompt模板中固定的token,尽管在少标注文本分类任务上性能优异[2],但是其表现随模型初始化参数不同会出现很大的波动[1, 3]。人工选择soft prompt模型参数需要对语言模型内部工作机理的深入理解和大量试错,并且在遇到不同少标注任务时难以复用。
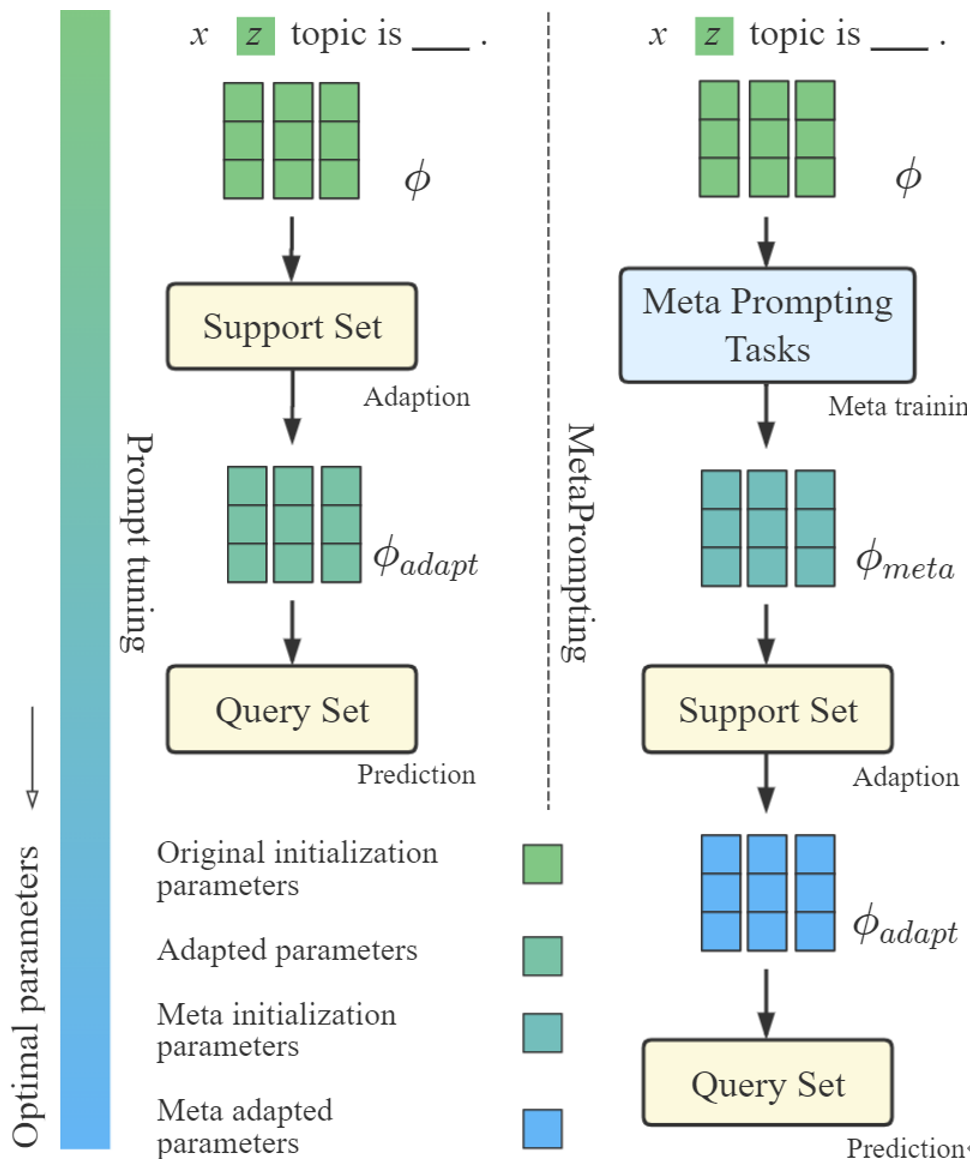
图1 MetaPrompting帮助模型找到一个更优参数初始化点,以更快、更好地适应于新的少标注任务
为了解决上述问题,本文将目光从任务专用的soft prompt模型设计转移到任务通用的模型参数初始化点搜索,以帮助模型快速适应到不同的少标注任务上。本文采用近年提出的基于优化的元学习方法,例如MAML[4]、Reptile[5]等,来搜索更优的soft prompt模型参数初始化点,以解决模型对初始化点过于敏感的问题。
本文在四个常用的少标注文本分类数据集上进行了充分的实验,结果表明MetaPrompting相比其他基于元学习和prompt方法的强基线模型取得了更好的效果,达到了新的SOTA。
2. 方法
2.1 Soft prompt方法
Prompt方法通过将下游任务转化成语言模型预训练目标的形式,帮助模型更好地在下游任务上发挥性能。如图2所示,对于一个新闻文本分类任务,可以通过将输入文本填入prompt模板的方式,将该文本分类任务转化为MLM任务形式。之后将模型在[MASK]位置填入各个词语的概率映射到不同标签上,即可完成文本分类任务的处理。
Soft prompt模型中,部分prompt tokens以可训练embedding的形式给出,并可以和预训练模型的参数一起进行优化,在保留离散token中语义信息的同时,给予模型更多的灵活性。
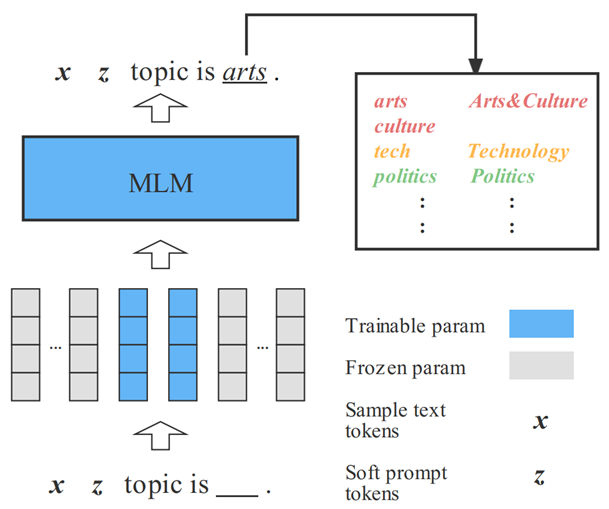
图2 Soft prompt方法
2.2 将基于优化的元学习方法应用于soft prompt模型
少标注任务构建
本文使用元阶段(episode)风格的少标注学习范式。具体而言,每一个少标注任务包含支持集和查询集两个部分,支持集中每个类别所对应标注样本数量极少,本文通过将模型在支持集上进行适配,在查询集上进行测试的方法,衡量模型的少标注学习性能。本文将不同标签对应的样本分别划分成用于训练、验证和测试的少标注任务,以衡量模型从源领域学习通用元知识来处理目标领域少标注任务的能力。
基于元学习的soft prompt模型优化过程
MetaPrompting的整体优化过程如图3所示。元训练阶段,模型在少标注任务的支持集上进行试探性参数更新,并在查询集上进行梯度回传。元测试阶段,模型在未见过的少标注任务上进行适配和预测。令和分别表示预训练模型和soft prompt的参数,在元训练阶段,模型在一个少标注任务支持集上进行适配的过程如下式所示:
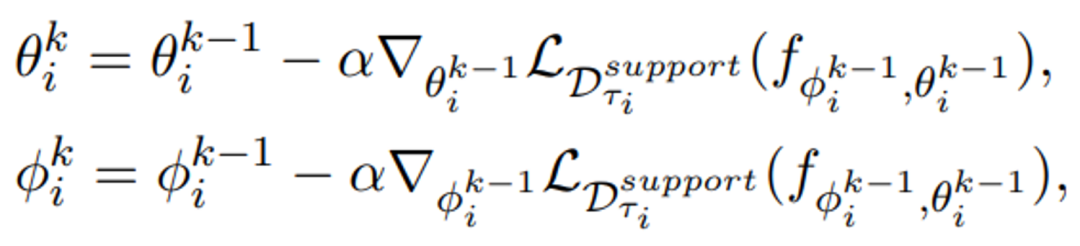
其中α是适配过程的学习率,表示模型进行适配学习的步数。令模型在少标注任务上适配学习之后的参数为和,可将模型在该少标注任务上的优化目标描述为:
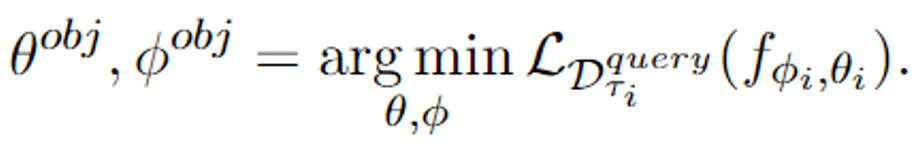
该优化目标模拟了模型在少标注场景下进行试探性参数更新,并根据试探性更新之后的情况优化模型参数的策略。这种策略更多关注了模型在一步或多步更新之后的情况,因而可以帮助模型找到一个能快速适应于新的少标注任务的参数初始化点。
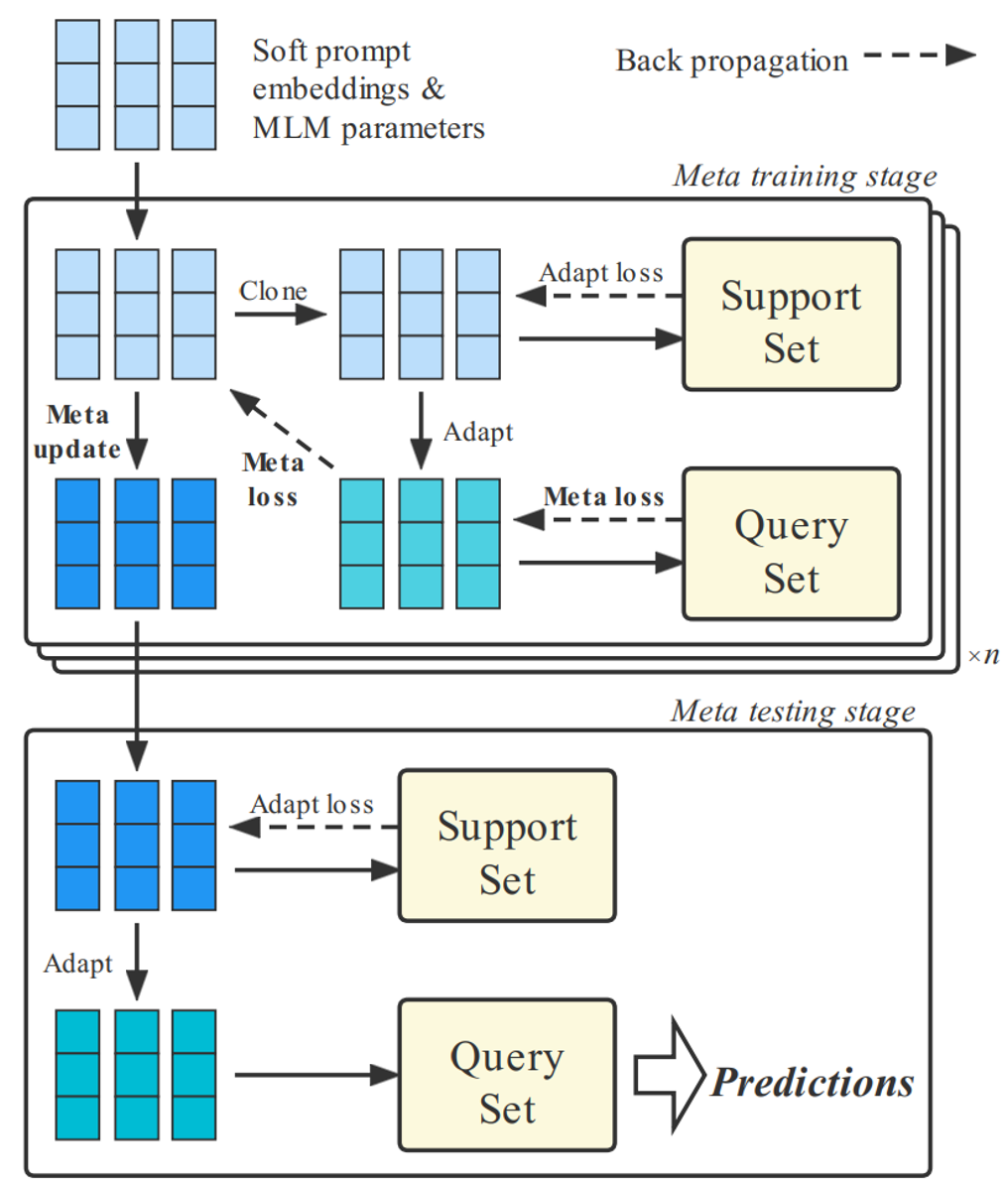
图3 MetaPrompting模型参数更新过程
实验中,本文还使用了MAML++[6]中的多步梯度回传技巧,来使得优化过程更加稳定,达到更好的效果。
3. 实验
本文分别采用5way 1shot和5way 5shot的少标注学习设定来测试模型性能。实验选择了HuffPost、Amazon、Reuters和20newsgroup四个广泛使用的文本分类数据集,结果以分类准确率%给出。
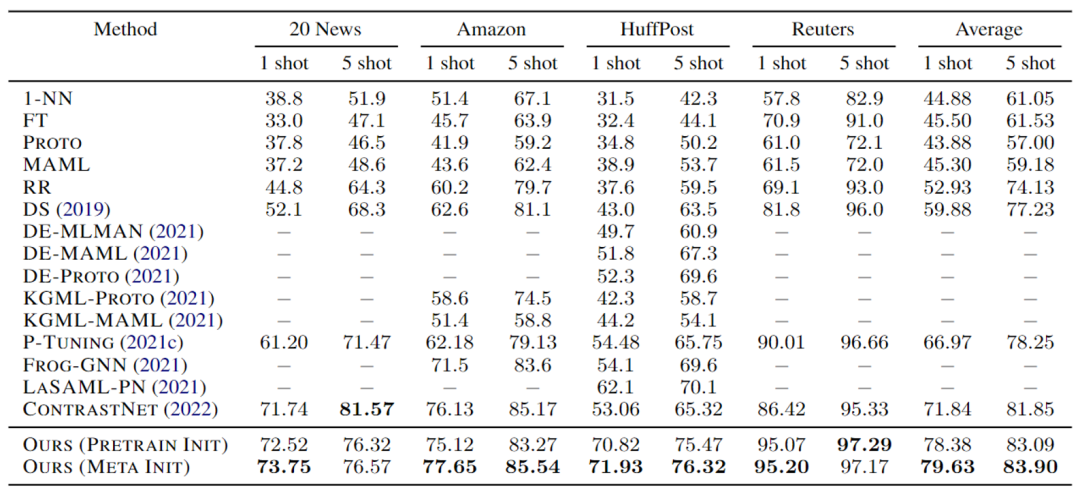
实验结果如表1所示,表中20newsgroup数据集性能由于数据构造问题与原文略有出入,现为勘误后结果,勘误不影响实验结论。由实验结果可见,MetaPrompting性能优于当前的SOTA模型ContrastNet[7]和其他基于元学习和提示学习的方法,取得了明显的性能提升。相比于不使用元学习优化目标的Ours (Pretrain Init),引入元学习搜索模型参数初始化点的Ours (Meta Init)也得到了更好的性能,说明了元学习方法在soft prompt模型参数优化中的有效性。
表1 MetaPrompting主实验结果
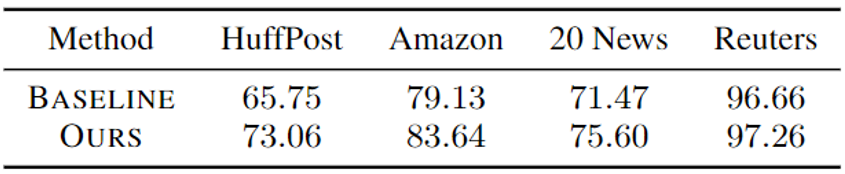
主实验中,为了与其他基线模型进行公平的对比,将soft prompt参数和预训练模型参数一起进行了优化。为了更好地说明MetaPrompting针对soft prompt参数初始化的作用,本文还参数进行了固定预训练模型的实验。实验结果如表2所示,相比于参数随机初始化的soft prompt模型,MetaPrompting取得了明显的性能提升。
表2 MetaPrompting在固定预训练模型参数时的性能
现实应用场景中,往往难以得到内容、形式十分相近的源领域数据。因此本文还对MetaPrompting在分布外数据上的性能进行了测试。实验结果如表3所示,即使源领域的数据内容、形式上有较大的差异,MetaPrompting仍然可以学习到任务通用的元知识,来辅助在目标领域少标注任务上的学习。
表3 MetaPrompting在不同内容、形式的源领域数据上进行元学习的性能

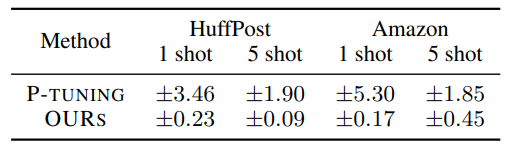
本文还对MetaPrompting对于不同prompt模板的鲁棒性进行了测试。如表4所示,相比于随机初始化的soft prompt模型,MetaPrompting寻找到的参数初始化点在不同prompt模板下性能方差更小,鲁棒性更强。
表4 MetaPrompting在不同prompt模板下性能的方差
4. 总结
本文提出了MetaPrompting,将基于优化的元学习方法推广到soft prompt模型中,来处理少标注文本任务。MetaPrompting利用源领域数据进行元学习,搜索能够更快、更好地适应于新的少标注人物的模型参数初始化点。在4个少标注文本分类数据集上的实验结果表明,MetaPrompting相比于朴素的soft prompt模型以及其他基于元学习的基线模型取得了更好的效果,达到了新的SOTA性能。
审核编辑 :李倩
-
嵌入式Linux学习方法2012-08-20 0
-
MCU的学习方法2013-05-23 0
-
快速的学习方法?2016-06-25 0
-
FPGA技术的学习方法2017-01-11 0
-
Linux建议的学习方法2020-04-15 0
-
统计的学习方法2020-07-15 0
-
STM32的学习方法分享?2020-08-14 0
-
嵌入式系统学习方法2021-12-17 0
-
STM32的学习方法2023-09-28 0
-
模拟电子电路的学习方法2009-08-07 913
-
嵌入式linux学习方法总结2008-09-10 3451
-
第1章 ZigBee简介和学习方法2015-12-07 537
-
ZigBee 简介和学习方法2016-04-15 569
-
单片机学习方法总结资料分享2021-11-13 457
-
联合学习在传统机器学习方法中的应用2023-07-05 544
全部0条评论

快来发表一下你的评论吧 !
