

一文解读人工智能产业链
描述
近几年来,人工智能行业飞速发展。麦肯锡预测人工智能可在未来十年为全球GDP增长贡献1.2个百分点,为全球经济活动增加13万亿美元产值,其贡献率可以与历史上第一次“工业革命”中蒸汽机等变革技术的引入相媲美。
从产业链来看,人工智能可以分为技术支撑层、基础应用层和产品层,各层面环环相扣,基础层和支撑层提供技术运算的平台、资源、算法,应用层的发展离不开基础层和技术的应用。
人工智能产业链

资料来源:凯联资本投研部
基础层分为硬件和软件。硬件即具备储存、运算能力的芯片,以及获取外部数据信息的传感器;软件则为用以计算的大数据。这里我们着重分析硬件部分的智能芯片。
1、智能芯片
按技术架构来看,智能芯片可分为通用类芯片(CPU、GPU、FPGA)、基于FPGA的半定制化芯片、全定制化ASIC芯片、类脑计算芯片(IBMTureNorth)。对于绝大多数智能需求来说,基于通用处理器的传统计算机成本高、功耗高、体积大、速度慢,难以接受。因此以CPU、GPU、FPGA、ASIC和类脑芯片为代表的计算芯片以高性能计算能力被引入深度学习。
AI半导体分类
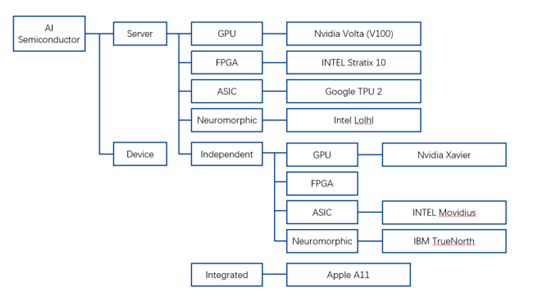
资料来源:谷歌,凯联资本投研部
2017年各AI企业公开芯片数据
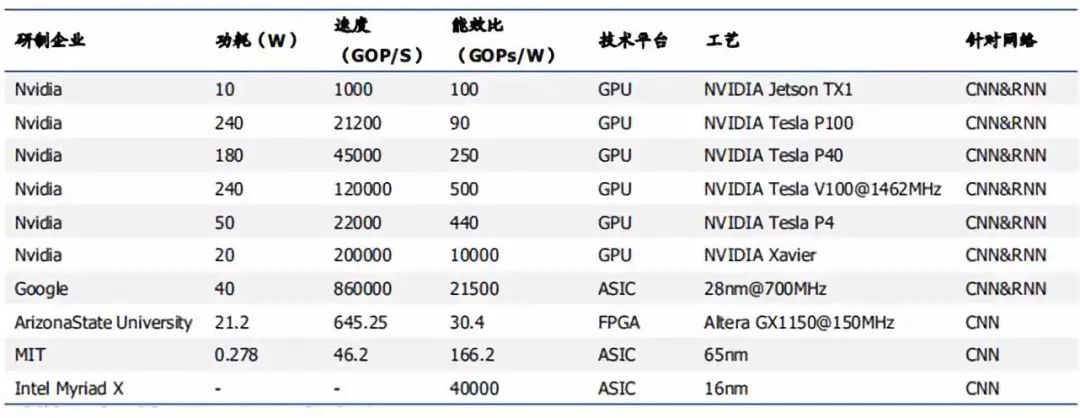
资料来源:中国科学院自动化研究所,凯联资本投研部
(1)GPU
大规模数据量下,传统CPU运算性能受限。遵循的是冯诺依曼架构,其核心就是:存储程序,顺序执行。随着摩尔定律的推进以及对更大规模与更快处理速度的需求的增加,CPU执行任务的速度受到限制。GPU在计算方面具有高效的并行性。用于图像处理的GPU芯片因海量数据并行运算能力,被最先引入深度学习。CPU中的大部分晶体管主要用于构建控制电路(如分支预测等)和Cache,只有少部分的晶体管来完成实际的运算工作。GPU 与 CPU 的设计目标不同,其控制电路相对简单,而且对Cache的需求较小,所以大部分晶体管可以组成各类专用电路和多条流水线,使GPU的计算速度有了突破性的飞跃,拥有惊人的处理浮点运算的能力。
GPU与CPU结构对比
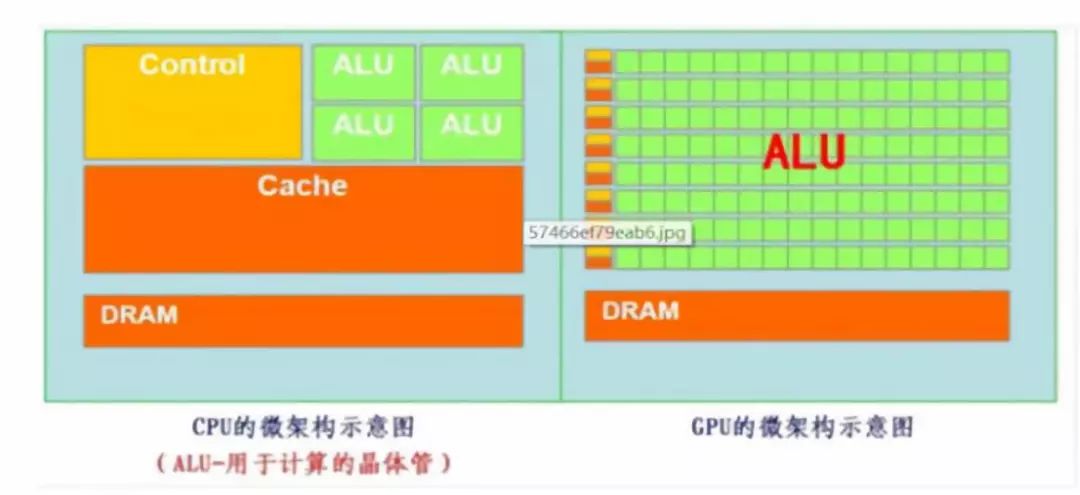
资料来源:谷歌,凯联资本投研部
(2)FPGA
FPGA(可编程门阵列,Field Programmable GateArray)是一种集成大量基本门电路及存储器的芯片,最大特点为可编程。可通过烧录FPGA配置文件来来定义这些门电路及存储器间的连线,从而实现特定的功能。此外可以通过即时编程烧入修改内部逻辑结构,从而实现不同逻辑功能。FPGA具有能耗优势明显、低延时和高吞吐的特性。不同于采用冯诺依曼架构的CPU与GPU,FPGA 主要由可编程逻辑单元、可编程内部连接和输入输出模块构成。FPGA每个逻辑单元的功能和逻辑单元之间的连接在写入程序后就已经确定,因此在进行运算时无需取指令、指令译码,逻辑单元之间也无需通过共享内存来通信。因此,尽管FPGA主频远低于CPU,但完成相同运算所需时钟周期要少于CPU,能耗优势明显,并具有低延时、高吞吐的特性。
FPGA结构图
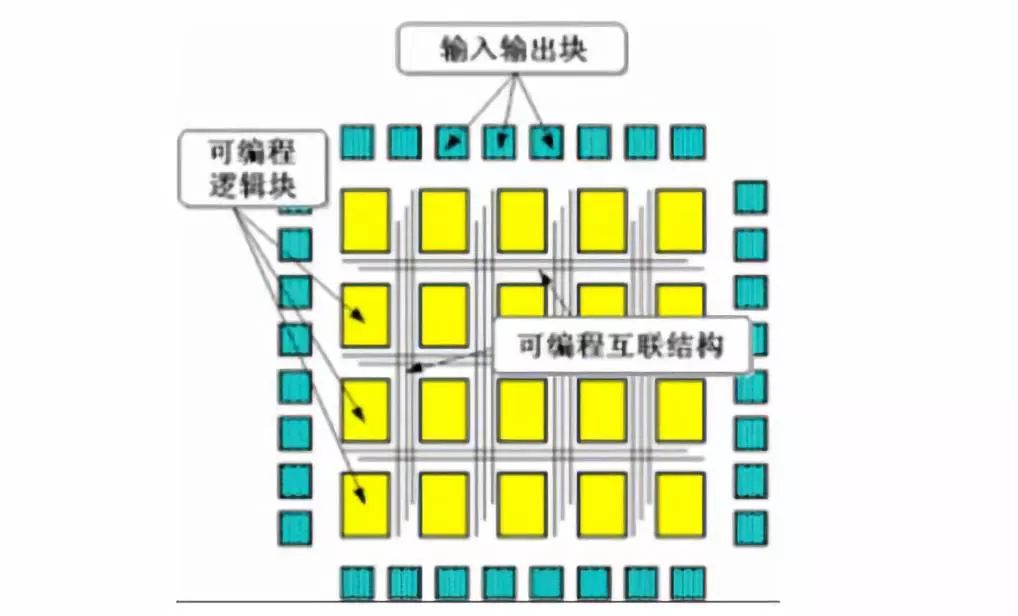
资料来源:谷歌,凯联资本投研部
(3)ASIC
ASIC 芯片是专用定制芯片,为实现特定要求而定制的芯片。除了不能扩展以外,在功耗、可靠性、体积方面都有优势,尤其在高性能、低功耗的移动端。谷歌的TPU、寒武纪的GPU,地平线的BPU都属于ASIC芯片。谷歌的TPU比CPU和GPU的方案快30-80倍,与CPU和GPU相比,TPU把控制缩小了,因此减少了芯片的面积,降低了功耗。其缺点在于开发周期长、投入成本大,一般公司难以承担。
张量处理器(tensor processing unit,TPU)是Google为机器学习定制的专用芯片(ASIC),专为Google的深度学习框架TensorFlow而设计。与GPU相比,TPU采用低精度(8 位)计算,以降低每步操作使用的晶体管数量。降低精度对于深度学习的准确度影响很小,但却可以大幅降低功耗、加快运算速度。Google在2016年首次公布了TPU。2017年公布第二代TPU,并将其部署在Google云平台之上,第二代TPU的浮点运算能力高达每秒180 万亿次。
AI芯片主要性能对比
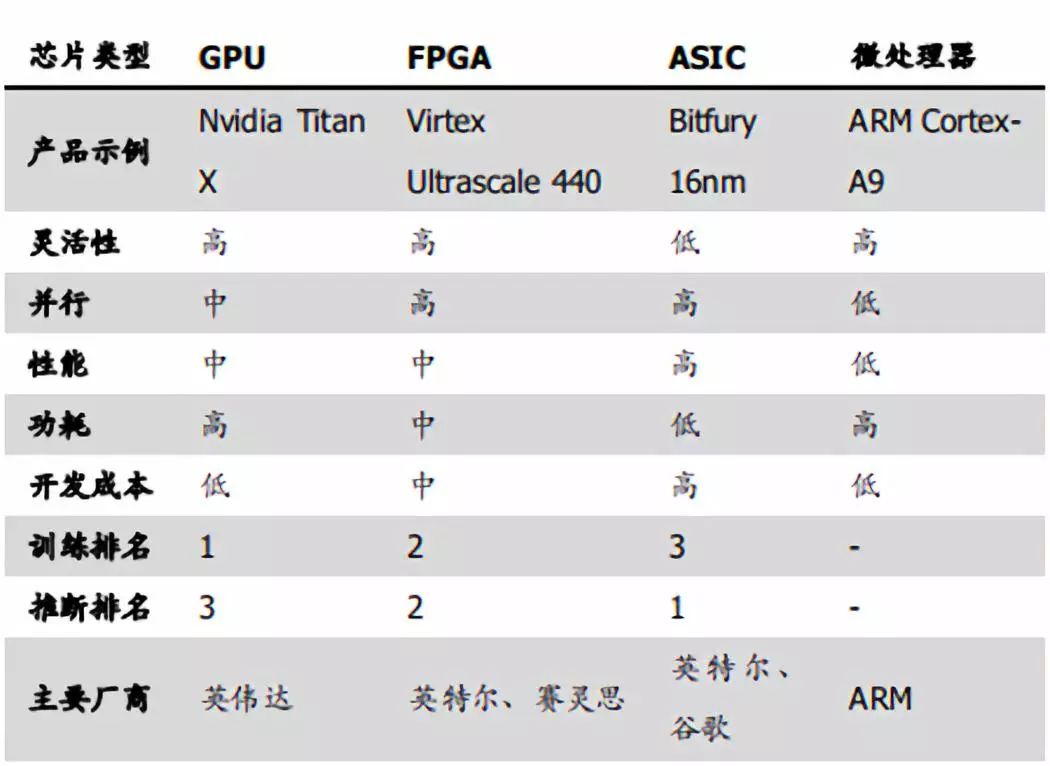
资料来源:学术论文,凯联资本投研部
2、智能芯片架构
架构创新是解决成本不断上涨的关键。随着市场对芯片计算能力的需求提高,芯片制造工艺也在不断提高,与之而来的是芯片制造成本不断涨高,解决这个问题的关键则是架构创新。目前 AI 芯片主要架构有CPU+GPU、CPU+FPGA、CPU+ASIC等。
主流AI处理器的制程和架构
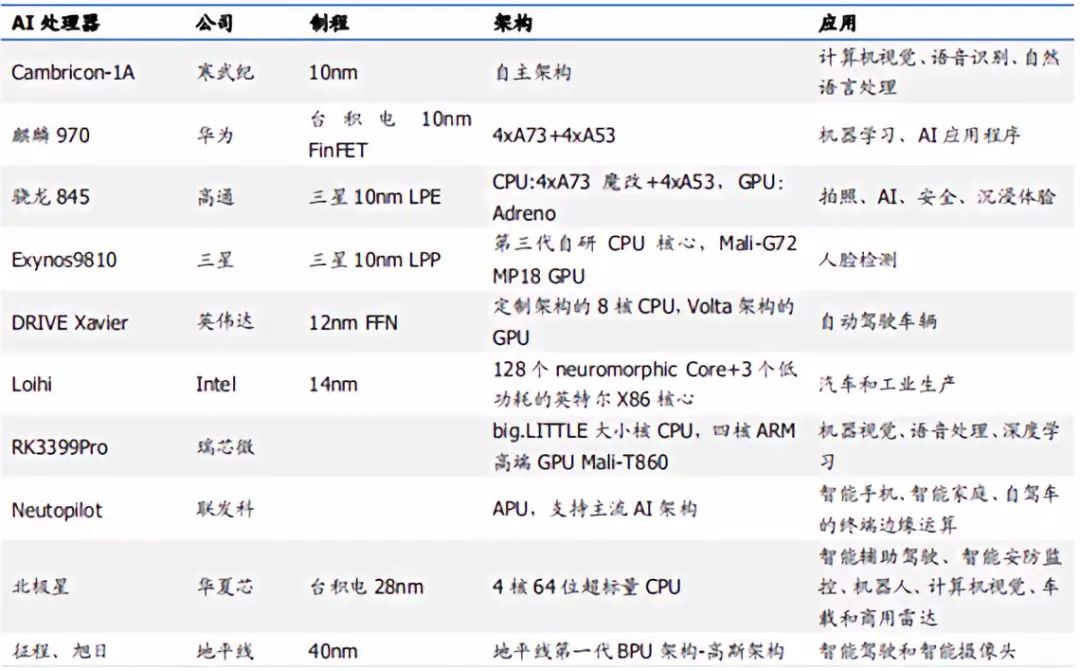
资料来源:电子发烧友,凯联资本投研部
3、智能芯片的应用
深度学习主要分为训练和推断两个环节:在数据训练(training)阶段,大量的标记或者未标记的数据被输入深度神经网络中进行训练,随着深度神经网络模型层数的增多,与之相对应的权重参数成倍的增长,从而对硬件的计算能力有着越来越高的需求,此阶段的设计目标是高并发高吞吐量。
推断(inference)则分为两大类——云侧推断与端侧推断,云侧推断推断不仅要求硬件有着高性能计算,更重要的是对于多指令数据的处理能力。就比如Bing搜索引擎同时要对数以万计的图片搜索要求进行识别推断从而给出搜索结果;端侧推断更强调在高性能计算和低功耗中寻找一个平衡点,设计目标是低延时低功耗。
因此从目前市场需求来看,人工智能芯片可以分为三个类别:
1) 用于训练(training)的芯片:主要面向各大AI企业及实验室的训练环节市场。目前被业内广泛接受的是“CPU+GPU”的异构模式,由于AMD在通用计算以及生态圈构建方面的长期缺位,导致了在深度学习GPU加速市场 NVIDIA一家独大。面临这一局面,谷歌今年发布TPU2.0 能高效支持训练环节的深度网络加速。我们在此后进行具体分析;
2) 用于云侧推断(inferenceoncloud)的芯片:在云端推断环节,GPU不再是最优的选择,取而代之的是,目前 3A(阿里云、Amazon、微软 Azure)都纷纷探索“云服务器+FPGA”模式替代传统CPU以支撑推断环节在云端的技术密集型任务。但是以谷歌TPU为代表的ASIC也对云端推断的市场份额有所希冀;
3) 用于端侧推断(inferenceondevice)的芯片:未来在相当一部分人工智能应用场景中,要求终端设备本身需要具备足够的推断计算能力,而显然当前ARM等架构芯片的计算能力,并不能满足这些终端设备的本地深度神经网络推断,业界需要全新的低功耗异构芯片,赋予设备足够的算力去应对未来越发增多的人工智能应用场景。我们预计在这个领域的深度学习的执行将更多的依赖于ASIC。
-
2015年智能照明市场及相关产业链发展趋势报告2015-01-15 0
-
机器人的“脑洞大开”产业链2015-06-04 0
-
人工智能是什么?2015-09-16 0
-
分享:人工智能算法将带领机器人走向何方?2017-08-16 0
-
AI人工智能:54份行业重磅报告汇总(附下载)2017-11-21 0
-
人工智能将助力智能家居产业发展2018-04-19 0
-
中美贸易战对全球半导体产业链的影响2018-08-30 0
-
AI智能芯片火热,全芯片产业链都积极奔着人工智能去2018-10-10 0
-
解读人工智能的未来2018-11-14 0
-
2019年人工智能技术峰会落幕,大咖演讲PPT火热出炉!2019-07-02 0
-
一图读懂:河南省新一代人工智能产业发展行动方案2019-09-02 0
-
目前人工智能教育研究最深入最经典的白皮书:德勤《全球人工智能发展白皮书2019》精选资料分享2021-07-27 0
-
快速发展的物联网产业链2021-07-27 0
-
一文看懂人工智能语音芯片 精选资料分享2021-07-29 0
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 0
全部0条评论

快来发表一下你的评论吧 !
