

Python-爬虫开发02
描述
谷歌浏览器分析post地址
- 方式一: 使用浏览器自带开发者工具( f12 快捷键 ),通过查询form表单获取
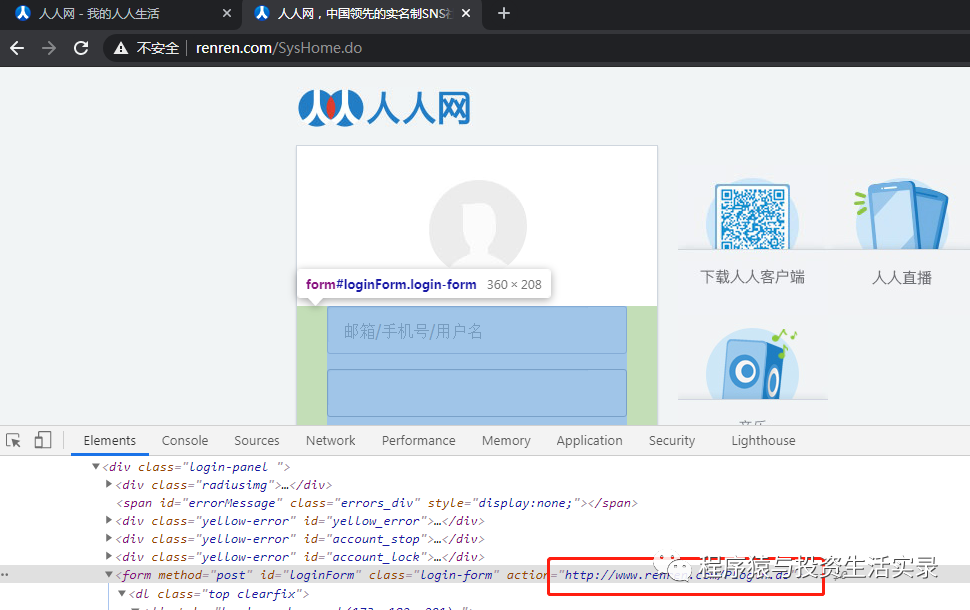
- 方式二: 直接点击登录按钮,查看访问的地址(需要注意下面请求时传递的参数,如果部分参数不知道如何得到,可能需要跟踪js文件查看)
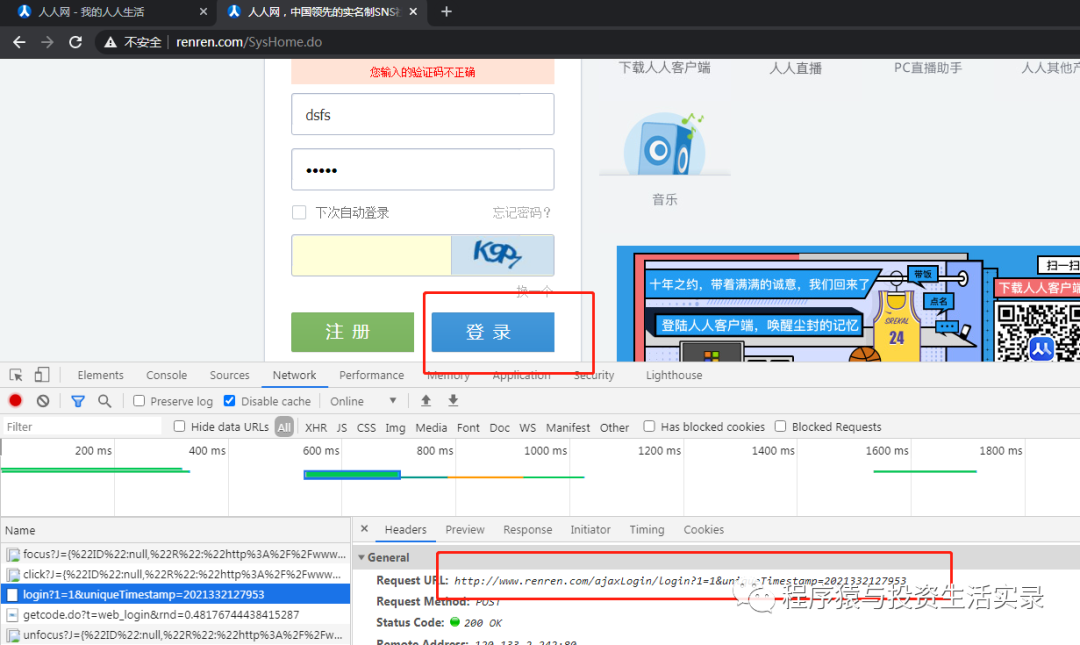
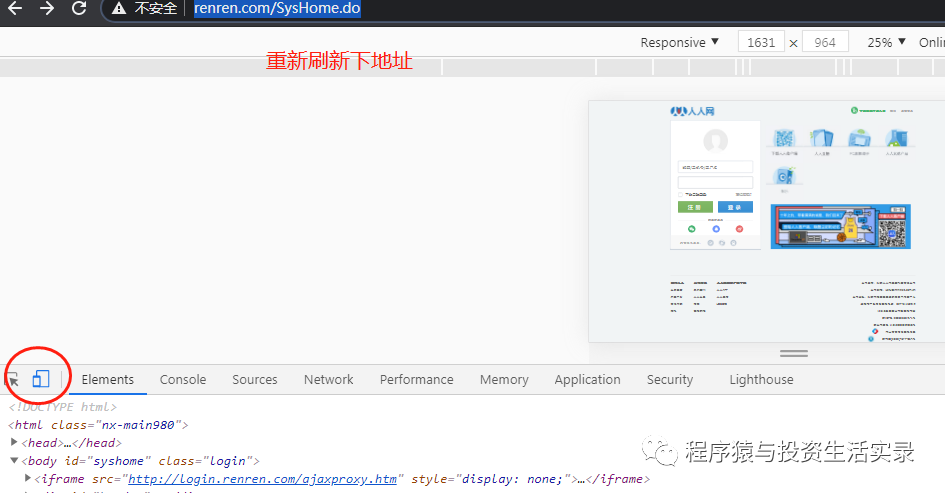
- 方式三: 部分网站的PC端请求时需要的参数较多,但是移动端会少些,所以可以切换到移动端看看请求地址与参数
requests小技巧
- requests.util.dict_from_cookiejar 把cookie对象转化为字典
- 请求SSL证书验证
- r=requests.get(url,verify=False)
- 设置超时
- r=requests.get(url,timeout=时间(单位是秒))
- 使用断言判断状态码是否成功
- assert respnose.status_code==200
爬虫数据处理
数据分类
- 非结构化数据:html 等
- 处理方法:使用 正则表达式、xpath 处理数据
- 结构化数据:json、xml等
- 处理方法:转化为python中的数据类型
数据处理之JSON
- JSON(JavaScript Object Notation) ,是一种轻量级的数据交换格式,它使得人们很容易进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站的前后台之间的数据交互。
- 爬取豆瓣电视剧列表示例
import json
import requests
class DouBanMovie:
def __init__(self):
self.url="https://m.douban.com/rexxar/api/v2/subject_collection/tv_domestic/items?os=android&for_mobile=1&start=0&count=18&loc_id=108288"
self.headers={
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Mobile Safari/537.36",
"Referer": "https://m.douban.com/tv/chinese"
}
def get_data(self):
response = requests.get(self.url, headers=self.headers)
if response.status_code==200:
# 将json字符串转化为python中的数据类型
result=json.loads(response.content.decode())
return result
def write_file(self,fileName,data):
'''写入文件'''
# json.dumps能够把python中的类型数据转化成json字符串
data=json.dumps(data,ensure_ascii=False)
with open(fileName,"w",encoding="utf-8") as f:
f.write(data)
def read_file(self,fileName):
'''读取文件数据'''
with open(fileName, "r", encoding="utf-8") as f:
# 加载json类型数据的文件
result=json.load(f)
return result
def run(self):
# 获取数据
result=self.get_data()
# 将豆瓣数据写入文件
self.write_file("douban.txt",result)
# 读取文件内容
readResult=self.read_file("douban.txt")
print(readResult)
if __name__ == '__main__':
douban=DouBanMovie()
douban.run()
数据处理之正则表达式
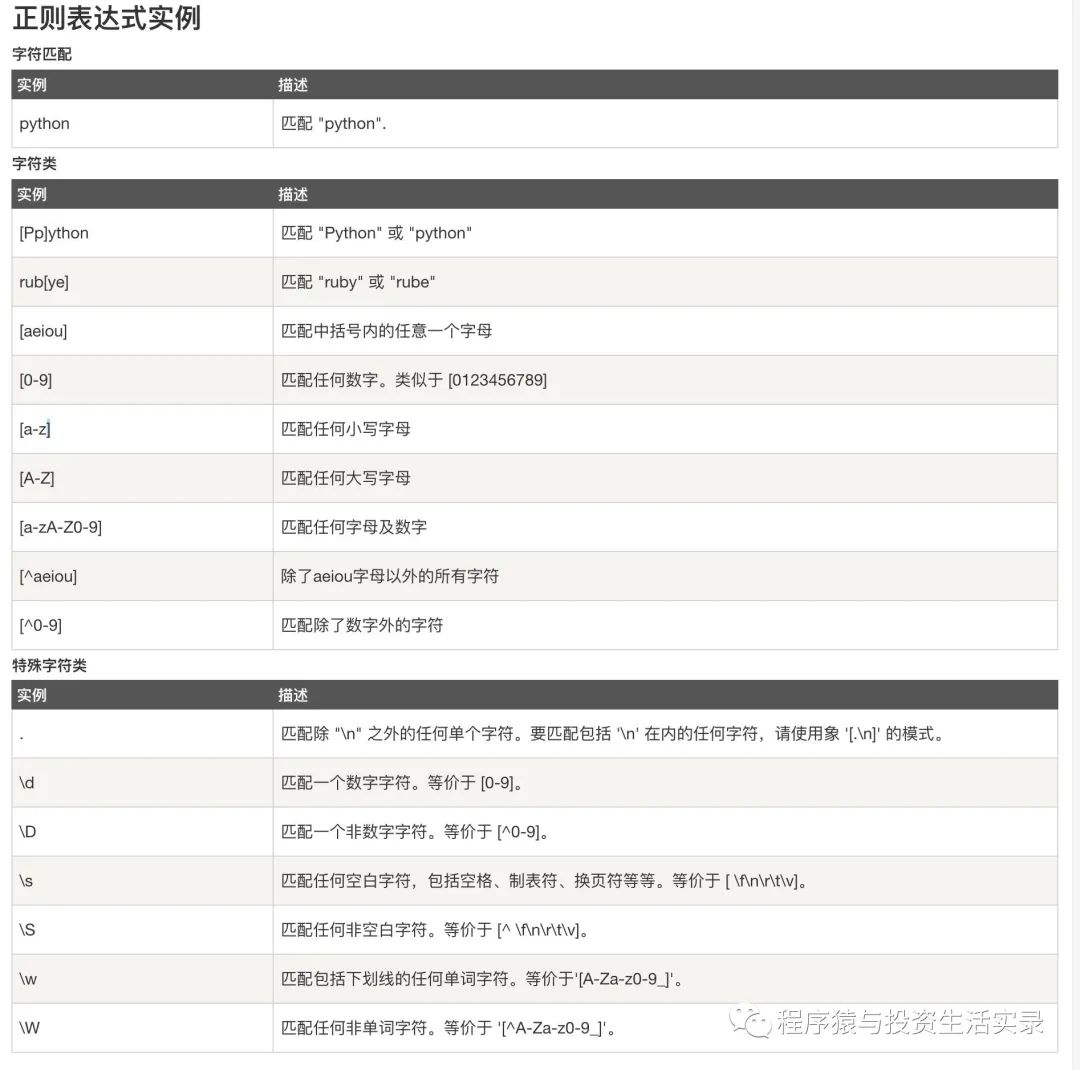
- 正则表达式定义
- 就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个” 规则字符串 “,这个”规则字符串“用来表达对字符串的一种过滤逻辑
- 常用正则表达式的方法
- re.compile(编译)
- pattern.match(从头开始匹配一个)
- pattern.search(从任何位置开始匹配一个)
- pattern.findall(匹配所有)
- pattern.sub(替换)
- Python正则表达式中的re.S,re.M,re.I的作用
- 正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志


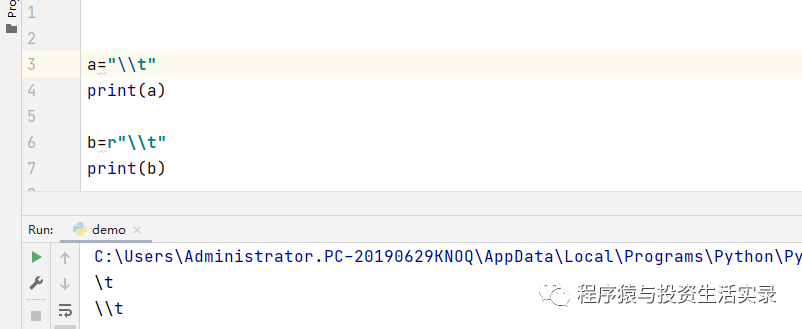
- python中 r 的用法
- 'r'是防止字符转义的 如果路径中出现'\\t'的话 不加r的话\\t就会被转义 而加了'r'之后'\\t'就能保留原有的样子
- 示例(提取成语故事)
import requests
import re
class ChengYu:
def __init__(self):
self.url="http://www.hydcd.com/cy/gushi/0259hs.htm"
self.headers={
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Mobile Safari/537.36"
}
def get_data(self):
response=requests.get(self.url,self.headers)
result=None
if response.status_code==200:
result=response.content.decode("gb2312")
return result
def handle_data(self,html_str_list):
if html_str_list==None or len(html_str_list)==0:
return None
html_str=html_str_list[0]
result=re.sub(r"\\r|\\t|
","",html_str)
return result
def run(self):
# 访问网页信息
html_str=self.get_data()
# 用正则表达式提取 成语故事
html_str_list=re.findall(r"(.*?)",html_str,re.S)
# 处理语句中的换行、制表等标识体符
result=self.handle_data(html_str_list)
print(result)
if __name__ == '__main__':
chengYu=ChengYu()
chengYu.run()
数据处理之xpath
- lxml 是一款高性能的python html/xml 解析器,我们可以利用xpath,来快速定位特定元素以及获取节点信息
- xpath(xml path langueage)是一门在 html/xml 文档中查找信息的语言,可以用来在html/xml 文档中对元素和属性进行遍历
- 官网地址:https://www.w3school.com.cn/xpath/index.asp
- xpath 节点选择语法
- xpath 使用路径表达式来选取xml,文档中的节点或者节点集,这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似
| 表达式 | 描述 |
|---|---|
| node name | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
- 常用节点的选择工具
- Chrome插件 XPath Helper
- 开源的 XPath表达式编辑工具:XML Quire(xml 格式文件可用)
- Firefox插件 XPath Checker
- lxml库
- 安装lxml:pip install lxml
- 使用方法:** from lxml import etree**
- 利用 etree.HTML ,将字符串转化为 Element对象
- Element对象具有xpath的方法:html=etree.HTML(字符串)
- 示例
import requests
import re
from lxml import etree
class ChengYu:
def __init__(self):
self.url="http://www.hydcd.com/cy/gushi/0259hs.htm"
self.headers={
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Mobile Safari/537.36"
}
def get_data(self):
response=requests.get(self.url,self.headers)
result=None
if response.status_code==200:
result=response.content.decode("gb2312")
return result
def handle_data(self,html_str_list):
if html_str_list==None or len(html_str_list)==0:
return None
html_str=html_str_list[0]+html_str_list[1]
result=re.sub(r"\\r|\\t|
","",html_str)
return result
def run(self):
# 访问网页信息
html_str=self.get_data()
# 用xpath提取元素
html=etree.HTML(html_str)
result=html.xpath("//font[@color=\\"#10102C\\"]/text()")
# 处理语句中的换行、制表等标识体符
result=self.handle_data(result)
print(result)
if __name__ == '__main__':
chengYu=ChengYu()
chengYu.run()
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
Python数据爬虫学习内容2018-05-09 0
-
Python爬虫与Web开发库盘点2018-05-10 0
-
0基础入门Python爬虫实战课2021-07-25 0
-
Python爬虫简介与软件配置2022-01-11 0
-
python网络爬虫概述2022-03-21 0
-
python-控制khr3hv-master机器人2016-11-22 760
-
详细用Python写网络爬虫2017-09-07 727
-
完全自学指南Python爬虫BeautifulSoup详解2017-09-07 727
-
WebSpider——多个python爬虫项目下载2018-03-26 614
-
Python爬虫8个常用的爬虫技巧分析总结2018-08-18 4895
-
python爬虫入门教程之python爬虫视频教程分布式爬虫打造搜索引擎2018-08-28 1340
-
python爬虫框架有哪些2019-03-22 6490
-
用Python写网络爬虫2021-06-01 594
-
Python-爬虫开发012023-02-16 418
-
利用Python编写简单网络爬虫实例2023-02-24 312
全部0条评论

快来发表一下你的评论吧 !
