

基于 Boosting 框架的主流集成算法介绍(上)
电子说
描述
本文是决策树的第三篇,主要介绍基于 Boosting 框架的主流集成算法,包括 XGBoost 和 LightGBM。
XGBoost

XGBoost 是大规模并行 boosting tree 的工具,它是目前最快最好的开源 boosting tree 工具包,比常见的工具包快 10 倍以上。Xgboost 和 GBDT 两者都是 boosting 方法,除了工程实现、解决问题上的一些差异外,最大的不同就是目标函数的定义。故本文将从数学原理和工程实现上进行介绍,并在最后介绍下 Xgboost 的优点。
1.1 数学原理
1.1.1 目标函数
我们知道 XGBoost 是由 k 个基模型组成的一个加法运算式:
其中 为第 k 个基模型, 为第 i 个样本的预测值。
损失函数可由预测值 与真实值 进行表示:
其中 n 为样本数量。
我们知道模型的预测精度由模型的偏差和方差共同决定,损失函数代表了模型的偏差,想要方差小则需要简单的模型,所以目标函数由模型的损失函数 L 与抑制模型复杂度的正则项 组成,所以我们有:
为模型的正则项,由于 XGBoost 支持决策树也支持线性模型,所以这里不再展开描述。
我们知道 boosting 模型是前向加法,以第 t 步的模型为例,模型对第 i 个样本 的预测为:
其中 由第 t-1 步的模型给出的预测值,是已知常数, 是我们这次需要加入的新模型的预测值,此时,目标函数就可以写成:
求此时最优化目标函数,就相当于求解 。
泰勒公式是将一个在 处具有 n 阶导数的函数 f(x) 利用关于 的 n 次多项式来逼近函数的方法,若函数 f(x) 在包含 的某个闭区间 上具有 n 阶导数,且在开区间 (a,b) 上具有 n+1 阶导数,则对闭区间 上任意一点 x 有 其中的多项式称为函数在 处的泰勒展开式, 是泰勒公式的余项且是 的高阶无穷小。
根据泰勒公式我们把函数 在点 x 处进行泰勒的二阶展开,可得到如下等式:
我们把 视为 视为 ,故可以将目标函数写为:
其中 为损失函数的一阶导, 为损失函数的二阶导,注意这里的求导是对 求导。
我们以平方损失函数为例:
则:
由于在第 t 步时 其实是一个已知的值,所以 是一个常数,其对函数的优化不会产生影响,因此目标函数可以写成:
所以我们只需要求出每一步损失函数的一阶导和二阶导的值(由于前一步的 是已知的,所以这两个值就是常数),然后最优化目标函数,就可以得到每一步的 f(x) ,最后根据加法模型得到一个整体模型。
1.1.2 基于决策树的目标函数
我们知道 Xgboost 的基模型不仅支持决策树,还支持线性模型,这里我们主要介绍基于决策树的目标函数。
我们可以将决策树定义为 ,x 为某一样本,这里的 q(x) 代表了该样本在哪个叶子结点上,而 w_q 则代表了叶子结点取值 w ,所以 就代表了每个样本的取值 w (即预测值)。
决策树的复杂度可由叶子数 T 组成,叶子节点越少模型越简单,此外叶子节点也不应该含有过高的权重 w (类比 LR 的每个变量的权重),所以目标函数的正则项可以定义为:
即决策树模型的复杂度由生成的所有决策树的叶子节点数量,和所有节点权重所组成的向量的 范式共同决定。
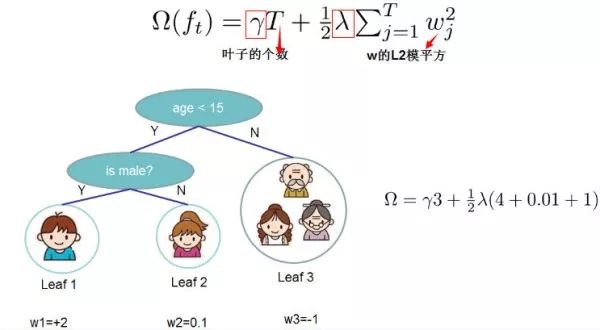
这张图给出了基于决策树的 XGBoost 的正则项的求解方式。
我们设 为第 j 个叶子节点的样本集合,故我们的目标函数可以写成:
第二步到第三步可能看的不是特别明白,这边做些解释:第二步是遍历所有的样本后求每个样本的损失函数,但样本最终会落在叶子节点上,所以我们也可以遍历叶子节点,然后获取叶子节点上的样本集合,最后在求损失函数。即我们之前样本的集合,现在都改写成叶子结点的集合,由于一个叶子结点有多个样本存在,因此才有了 和 这两项, 为第 j 个叶子节点取值。
为简化表达式,我们定义 ,则目标函数为:
这里我们要注意 和 是前 t-1 步得到的结果,其值已知可视为常数,只有最后一棵树的叶子节点 不确定,那么将目标函数对 求一阶导,并令其等于 0 ,则可以求得叶子结点 j 对应的权值:
所以目标函数可以化简为:
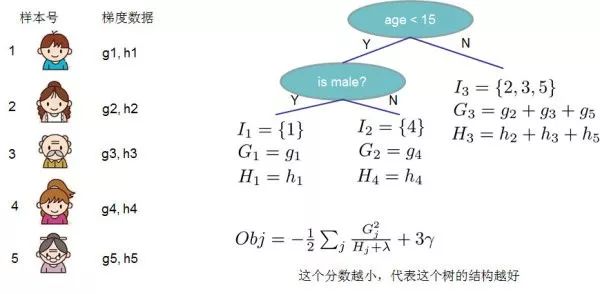
上图给出目标函数计算的例子,求每个节点每个样本的一阶导数 和二阶导数 ,然后针对每个节点对所含样本求和得到的 和 ,最后遍历决策树的节点即可得到目标函数。
1.1.3 最优切分点划分算法
在决策树的生长过程中,一个非常关键的问题是如何找到叶子的节点的最优切分点,Xgboost 支持两种分裂节点的方法——贪心算法和近似算法。
1)贪心算法
- 从深度为 0 的树开始,对每个叶节点枚举所有的可用特征;
- 针对每个特征,把属于该节点的训练样本根据该特征值进行升序排列,通过线性扫描的方式来决定该特征的最佳分裂点,并记录该特征的分裂收益;
- 选择收益最大的特征作为分裂特征,用该特征的最佳分裂点作为分裂位置,在该节点上分裂出左右两个新的叶节点,并为每个新节点关联对应的样本集
- 回到第 1 步,递归执行到满足特定条件为止
那么如何计算每个特征的分裂收益呢?
假设我们在某一节点完成特征分裂,则分列前的目标函数可以写为:
分裂后的目标函数为:
则对于目标函数来说,分裂后的收益为:
注意该特征收益也可作为特征重要性输出的重要依据。
对于每次分裂,我们都需要枚举所有特征可能的分割方案,如何高效地枚举所有的分割呢?
我假设我们要枚举所有 x < a 这样的条件,对于某个特定的分割点 a 我们要计算 a 左边和右边的导数和。
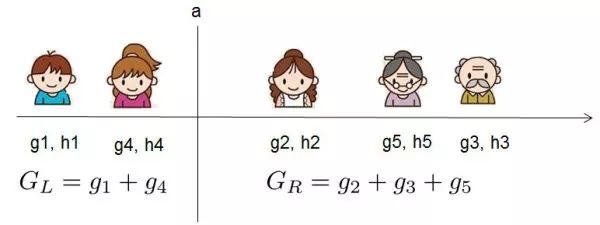
我们可以发现对于所有的分裂点 a,我们只要做一遍从左到右的扫描就可以枚举出所有分割的梯度和 和 。然后用上面的公式计算每个分割方案的分数就可以了。
2)近似算法
贪婪算法可以的到最优解,但当数据量太大时则无法读入内存进行计算,近似算法主要针对贪婪算法这一缺点给出了近似最优解。
对于每个特征,只考察分位点可以减少计算复杂度。
该算法会首先根据特征分布的分位数提出候选划分点,然后将连续型特征映射到由这些候选点划分的桶中,然后聚合统计信息找到所有区间的最佳分裂点。
在提出候选切分点时有两种策略:
- Global:学习每棵树前就提出候选切分点,并在每次分裂时都采用这种分割;
- Local:每次分裂前将重新提出候选切分点。
直观上来看,Local 策略需要更多的计算步骤,而 Global 策略因为节点没有划分所以需要更多的候选点。
下图给出不同种分裂策略的 AUC 变换曲线,横坐标为迭代次数,纵坐标为测试集 AUC,eps 为近似算法的精度,其倒数为桶的数量。
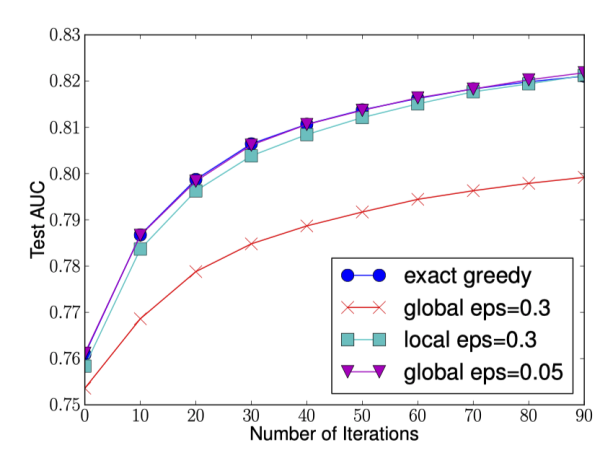
我们可以看到 Global 策略在候选点数多时(eps 小)可以和 Local 策略在候选点少时(eps 大)具有相似的精度。此外我们还发现,在 eps 取值合理的情况下,分位数策略可以获得与贪婪算法相同的精度。

- 第一个 for 循环:对特征 k 根据该特征分布的分位数找到切割点的候选集合 。XGBoost 支持 Global 策略和 Local 策略。
- 第二个 for 循环:针对每个特征的候选集合,将样本映射到由该特征对应的候选点集构成的分桶区间中,即 ,对每个桶统计 G,H 值,最后在这些统计量上寻找最佳分裂点。
下图给出近似算法的具体例子,以三分位为例:
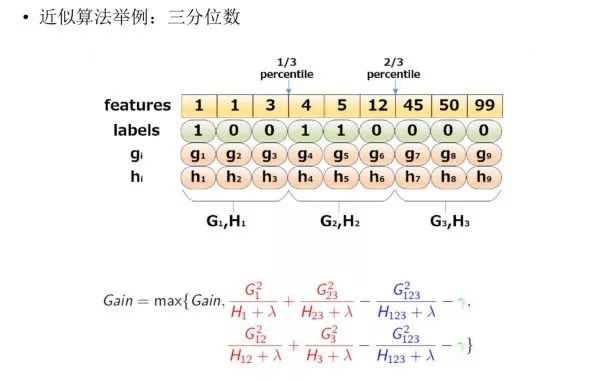
根据样本特征进行排序,然后基于分位数进行划分,并统计三个桶内的 G,H 值,最终求解节点划分的增益。
-
集成学习和Boosting提升方法2019-06-05 0
-
请问怎样去实现自适应波束形成算法?2021-04-28 0
-
3D图像生成算法的原理是什么?2021-06-04 0
-
五步直线扫描转换生成算法2009-06-06 798
-
基于负相关神经网络集成算法及其应用2011-05-26 560
-
基于OFDM系统的时域频域波束形成算法2011-12-14 626
-
基于加权co-occurrence矩阵的聚类集成算法2012-02-29 626
-
MIDI合成算法及其FPGA实现2012-04-16 1008
-
三种SPWM波形生成算法的分析与实现2016-08-24 845
-
基于修正的直觉模糊集成算子2017-11-17 647
-
基于boosting框架的混合秩矩阵分解模型2021-06-11 539
-
基于Xie-Beni指数的选择性聚类集成算法2021-06-17 665
-
基于并行Boosting算法的雷达目标跟踪检测系统2021-06-30 585
-
基于 Boosting 框架的主流集成算法介绍(中)2023-02-17 468
-
基于 Boosting 框架的主流集成算法介绍(下)2023-02-17 2326
全部0条评论

快来发表一下你的评论吧 !
