

数据采集技术常用的采集方法包括几种
电子说
描述
大数据的来源主要包括:商业数据、互联网数据、物联网数据。其中,商业数据来源于企业的内部系统(如企业ERP、POS 终端系统、网上支付系统等);互联网数据包括:QQ、微信、微博、网站数据;物联网数据来源于物联网硬件设备(如射频识别装置、全球定位设备、传感器设备、视频监控设备等)。
大数据的数据类型可分为三种:结构化数据、半结构化数据、非结构化数据。其中,结构化数据是关系数据库中的数据,可直接被使用和存储;半结构化数据可通过一定规律存储,如excel表格中的数据;非结构化数据是杂乱无章的,如邮件、网页的文字和图像,需要进行相应的处理才可被存储。
数据采集技术是数据科学的重要组成部分,技术是大数据处理的关键技术之一。常用的采集方法包括两种:ETL工具采集、网页数据采集。
一、ETL工具采集
ETL工具采集是将业务系统的数据通过抽取、清洗转换后加载至数据仓库的过程,目的是将企业中的分散零乱、标准不统一的数据整合,为企业的决策提供分析依据。
ETL采集是商业智能项目的重要环节,目前,互联网公司会采用该技术获取相关数据。
二、网页数据采集
网页数据采集是在互联网中采集数据。网页数据具有多元异构交互性、社会性、突发性、高噪声等特点,非结构化数据比例较高,且数据实时性较强。
目前,网页数据主要通过爬虫采集。爬虫采集需编写爬虫程序或爬虫脚本,爬虫流程是访问一个url(根据网络资料理解:url的中文名称是统一资源定位符,统一资源定位符是互联网资源位置和访问方法的一种简洁的表示,俗称网址),并通过模仿HTTP请求(根据网络资料:HTTP请求是指从客户端到服务器端的请求消息)获取网页。爬虫过程类似于通过浏览器查看并获取网页的信息。
因为Python运行效率较高,且具有较成熟的爬虫框架和网页解析库文件,所以可快速处理网络数据。后文通过Python介绍爬虫(网络爬虫)。
网络爬虫(Web crawler) 是按照一定规则,自动抓取万维网(英文名称为World Wide Web,简称WWW)信息的程序或脚本,一般可分为数据采集,处理,储存三部分。
其中,数据采集是通过模仿HTTP请求获取网页,数据处理是对网页中非结构化的数据进行处理,数据存储包括将新URL放置于URL队列中和将爬取的数据存储至数据存储介质中。 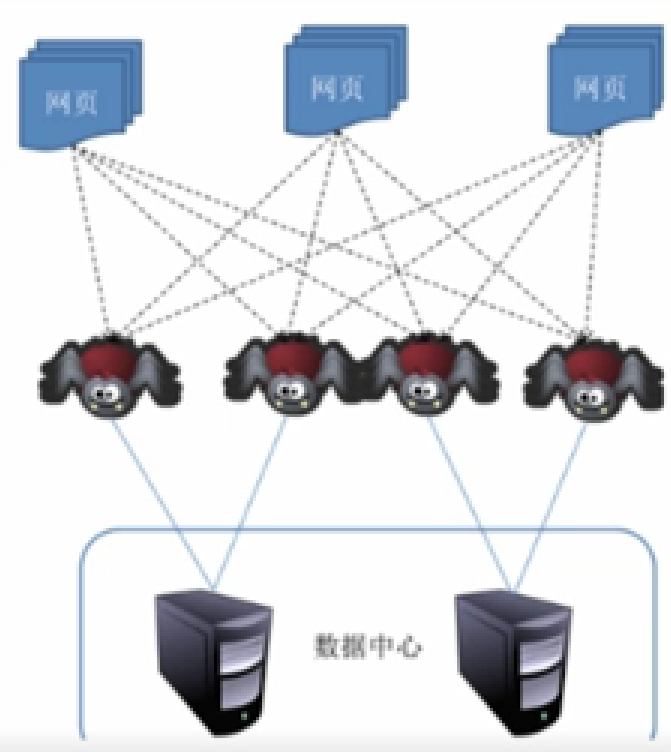
图片来源:学堂在线《大数据导论》
网络爬虫的系统结构如下:首先启动爬虫应用程序。一般,爬虫应用程序具有初始化队列,初始化队列中具有种子URL。然后,下载种子URL所对应的网页,网页中可提取新的URL并加入URL队列。再然后,将网页进行简单处理后存储至数据库中。以上爬虫过程结束后,再从URL队列中获取新URL,并下载新URL所对应的网页,重复爬虫过程。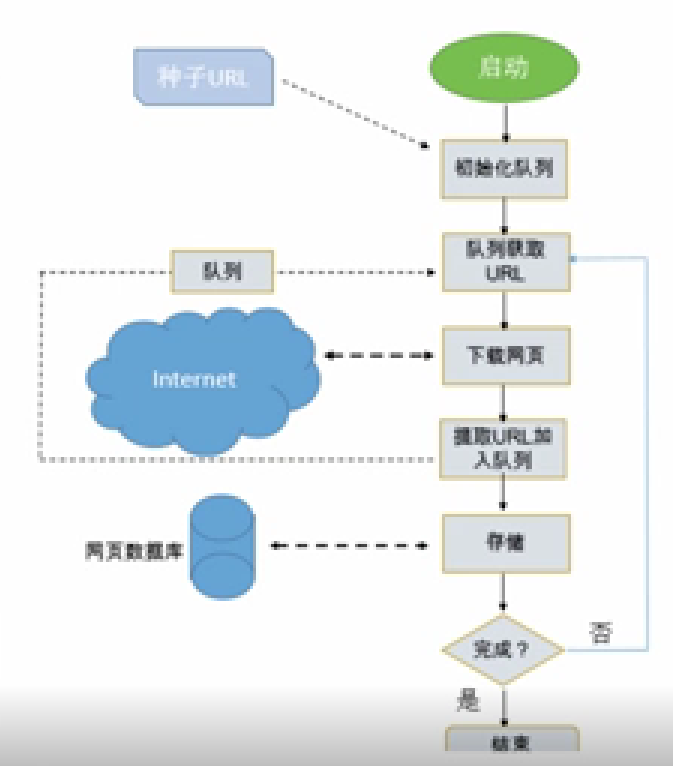
图片来源:学堂在线《大数据导论》
审核编辑:刘清
-
CANape-测量信号的添加#数据采集测量北汇信息POLELINK 2022-11-15
-
隧道监测方案包括哪几方面 数据采集传输分析预警等稳控自动化 2023-08-15
-
基于USB数据采集系统的研究与设计--ResearchandDesignofDataAequisitio2009-06-10 0
-
什么是数据采集?2016-01-28 0
-
SMT行业数据采集技术2018-10-20 0
-
常见的几种不同的高速数据采集存储系统介绍2019-07-04 0
-
实现高速数据采集有哪些方法?2019-07-31 0
-
浅谈几种主流数控机床的数据采集技术分享2021-07-02 0
-
基于PDA的核数据采集系统的研究2011-06-27 567
-
NI数据采集技术文摘_技术篇2016-01-13 674
-
数据采集技巧和技术2022-12-02 754
-
如何采集工业设备数据?工业数据采集的方法有哪些?2023-02-15 927
-
数据采集的方法有哪些2023-04-13 9303
-
AI数据采集标注类型:揭秘数据采集与标注的关键环节2023-05-16 3099
全部0条评论

快来发表一下你的评论吧 !
