

用TensorFlow2.0框架实现BP网络
描述
熬过了上一篇漫长的代码,稍微解开了一丢丢疑惑,使得抽象的BP有一点具体化了,可是还是有好多细节的东西没有讲清楚,比如,为什么要用激活函数?为什么随机梯度下降没有提到?下面我们来一一解开疑惑。
首先是为什么要使用激活函数?这要回顾一下我们在学习BP之前学习的感知器模型。它模仿的是人类体内的信号传导的过程,当信号达到一定的阈值时,就可以继续向后传播。
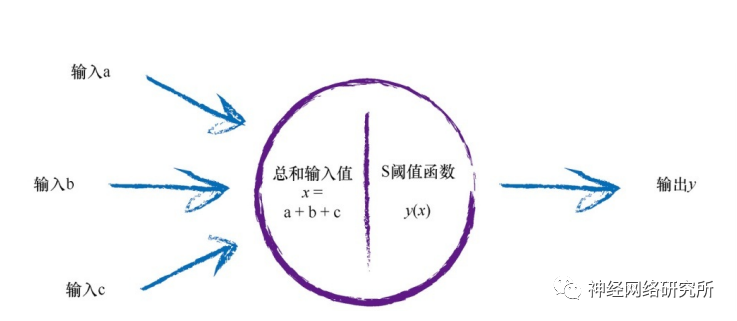
那这个感知器模型和BP网络有什么关系呢?在我们所看到的BP网络的结构图中,其实是被简化了的,下面小编画了一个逻辑更清晰一点的图:
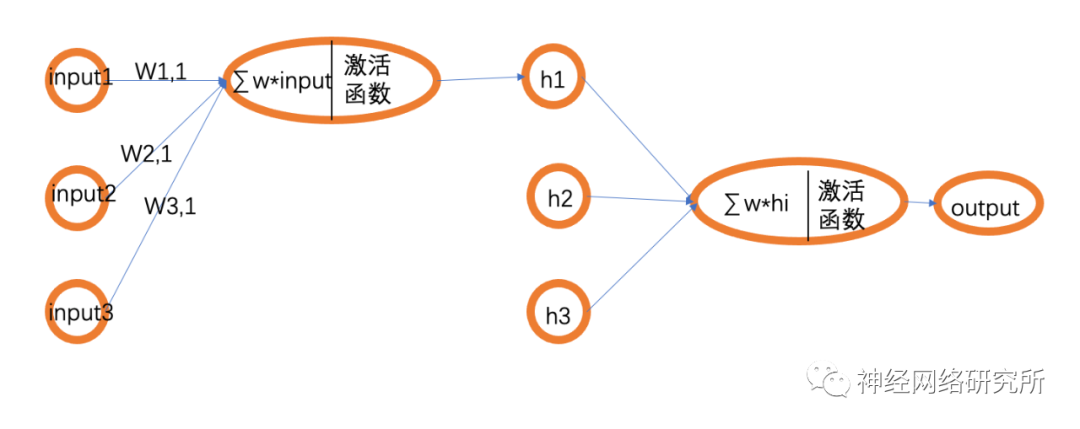
这样我们就可以看出来,其实BP网络是由一个一个的感知器组成,也就构成了一个真正的神经网络,自然就能理解为什么要使用激活函数了。
接下来我们来看一下TensorFlow实现BP神经网络到底有多简单!
#构建一个结构为[10,15,1]的BP神经网络
model = tf.keras.Sequential([tf.keras.layers.Dense(15,activation='relu',input_shape=(10,)),
tf.keras.layers.Dense(1)])
model.summary() #显示网络结构
model.compile(optimizer='SGD',loss='mse') #定义优化方法为随机梯度下降,损失函数为mse
#x->训练集,y——>bia标签,epochs=10000训练的次数,validation_data=(test_x,test_y)——>验证集
history = model.fit(x,y,epochs=10000,validation_data=(test_x,test_y))
上面就是一个最简单的BP网络的网络结构,小编还准备好了完整的通用框架代码,不用总是修改隐藏层,可以直接使用哦!公众号发送“BP源码”就可以获取!是不是非常惊讶!昨天的百行代码完全消失了,这短短几行代码就可实现一个BP网络。
这里解释一下validation_data,这是验证集,作用和测试集是一样的,只不过验证集是在训练过程中对模型进行测试,这样方便观察模型的准确性。loss函数的作用是计算模型的预测误差,也就是是衡量模型的准确度,常用的误差函数还有mse,mae,rmse,mape等等,模型中有很多误差函数不能直接调用,但是可以自己定义。
SGD就是我们所说的随机梯度下降算法了,但是现在我们普遍认为“adam”是目前最好的优化算法,当然这也根据不同的神经网络做不同的选择。想要研究理论的读者可以去查一查资料,小编作为实战派就不对理论做过多的阐述了!
另外再列出来同样强大的pytorch框架的代码,大家可以自行选取。
class Model(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Sequential(
nn.Linear(10, 15),
nn.ReLU(),
nn.Dropout(), #防止过度拟合,TensorFlow也有
nn.Linear(15, 2)
)
def forward(self, x):
x = self.fc(x)
return x
关于选择哪一个框架的问题,在TensorFlow2.0出现之前,小编会推荐pytorch,现在的TensorFlow2.0和pytorch代码风格已经越来越接近了,但是TensorFlow2.0可以支持的平台更多,所以这里推荐TensorFlow2.0。
有什么问题,欢迎大家留言讨论!
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 信号
- 阈值
- 函数
- BP网络
- tensorflow
-
TensorFlow2.0特性(1)#神经网络未来加油dz 2023-05-17
-
求利用LABVIEW 实现bp神经网络的程序2012-11-26 0
-
labview BP神经网络的实现2017-02-22 0
-
深度学习框架TensorFlow&TensorFlow-GPU详解2018-12-25 0
-
TensorFlow是什么2020-07-22 0
-
TensorFlow的特点和基本的操作方式2020-11-23 0
-
TensorFlow的框架结构解析2018-04-04 6912
-
CapsNet入门系列番外:基于TensorFlow实现胶囊网络2018-03-16 9421
-
机器学习框架Tensorflow 2.0的这些新设计你了解多少2018-11-17 3005
-
TensorFlow2.0终于问世,Alpha版可以抢先体验2019-03-08 3449
-
IJCAI 2019上的一个TensorFlow2.0实操教程,117页PPT干货分享2019-09-01 3215
-
tensorflow能做什么_tensorflow2.0和1.0区别2020-12-04 7703
-
神经网络原理简述—卷积Op求导2022-02-07 194
-
深度学习框架tensorflow介绍2023-08-17 1497
全部0条评论

快来发表一下你的评论吧 !
