

文本处理技巧之正则表达式
描述
在LabVIEW开发过程中,有很多地方都需要处理文本数据,比如数据通讯、报表生成、协议解析、文件I/O、界面交互等,那有没有一个工具可以帮助我们快速处理文本数据呢?答案是有的,那就是:“正则表达式”!
正则表达式(Regular Expression)是强大、高效和便捷的文本处理工具。正则表达式搭配一种编程语言,可以赋予开发人员描述和分析文本的能力。它能够添加、删除、拆分、插入和修改各种类型的文本数据。掌握正则表达式,可能带来超乎你想象的文本处理能力。
接下来请跟随小编一起学习正则表达式的相关知识并且了解在LabVIEW中处理文本数据时如何使用正则表达式吧!
本文分享:
正则表达式—文本处理技巧
一、 正则表达式的组成
为了方便大家理解,小编先给大家举个例子:huasui.exe是一个文件名,Windows文件对话框输入[*.exe]可以选择多个文件,这类文件名通常被称作“文件群组”或“通配符”,其实这就是一种正则表达式,[*.exe]能够匹配以字符「*」开头,以普通文本「.exe」结尾的字符串,它的意思是:选择以任意文本开头,以 .exe结尾的所有文件。
就像上面的例子那样,一个完整的正则表达式由两种字符构成,其中特殊字符(如刚才例子中的*)称为“元字符”,其它部分(如刚才例子中的.exe)叫作“普通字符”。正则表达式其实远不止于此,它可以为很多高级应用提供十分丰富且描述力极强的元字符。
二、 在LabVIEW中使用正则表达式
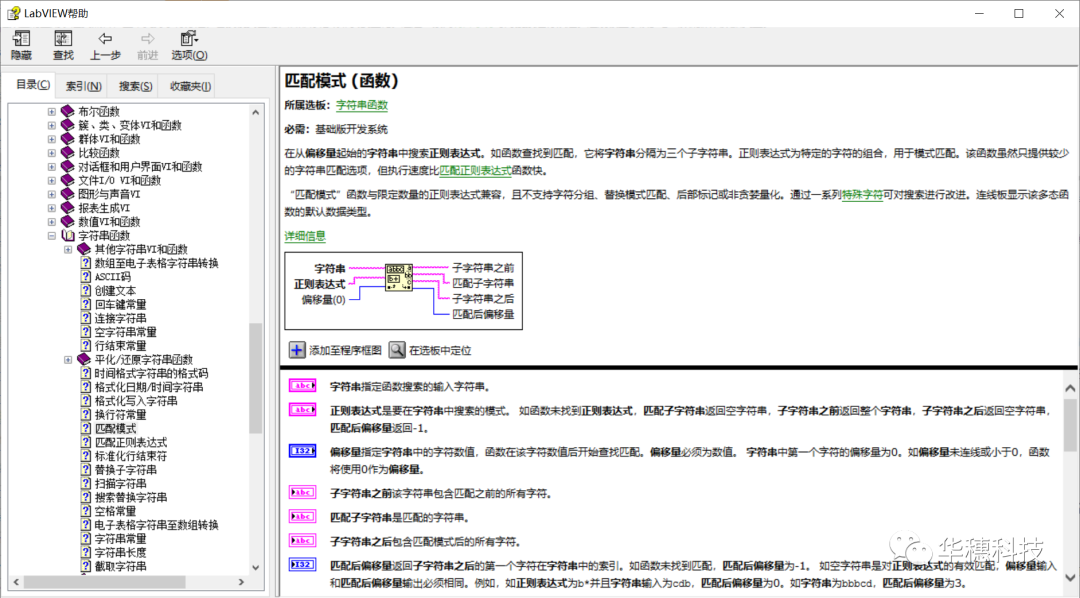
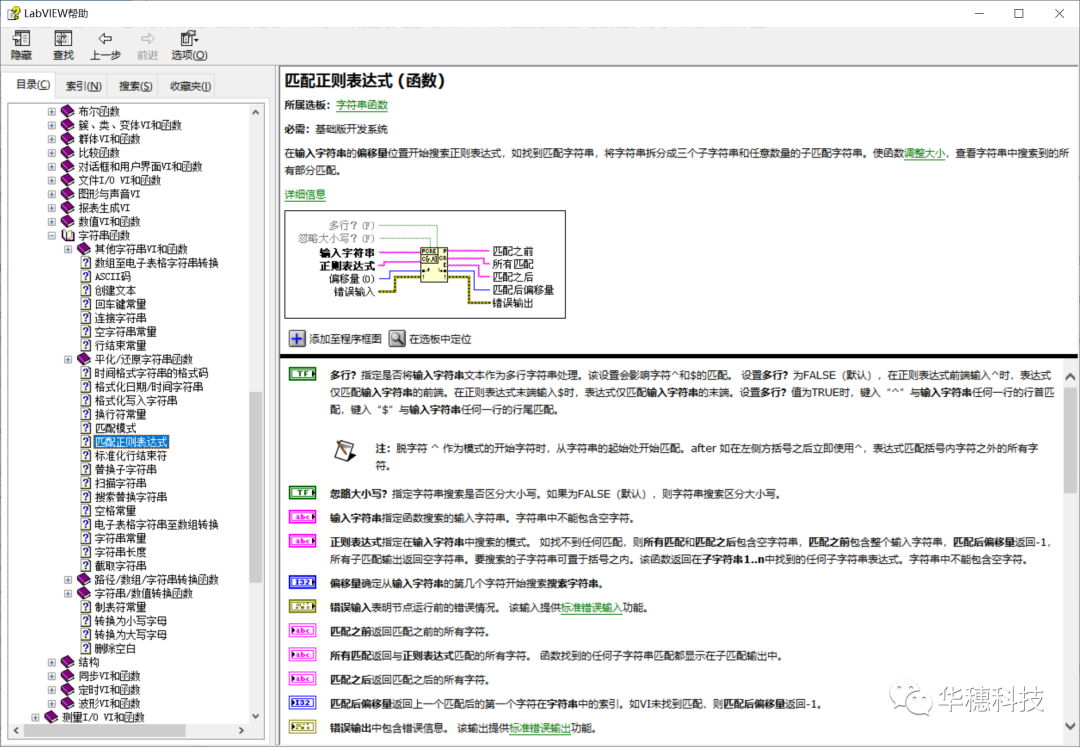
LabVIEW中提供了两个可以使用正则表达式的函数,一个是“匹配模式”,一个是“匹配正则表达式”,它们在函数选板>>字符串中可以找到。
这两个函数的使用方法大同小异。“匹配模式”函数类似于搜索及替换VI,该函数虽然只提供较少的字符串匹配选项(例如,该函数不支持括号和竖直线),但执行效率比“匹配正则表达式”函数高。具体使用差别可以参考LabVIEW自带的帮助文档。
三、 常用的正则表达式
在了解了以上LabVIEW和正则表达式的基础知识之后,我们来一起看看正则表达式中常用的一些元字符及其含义,以下正则表达式都用一对左右角括号「 」括起来。
1. 行的起始和结束
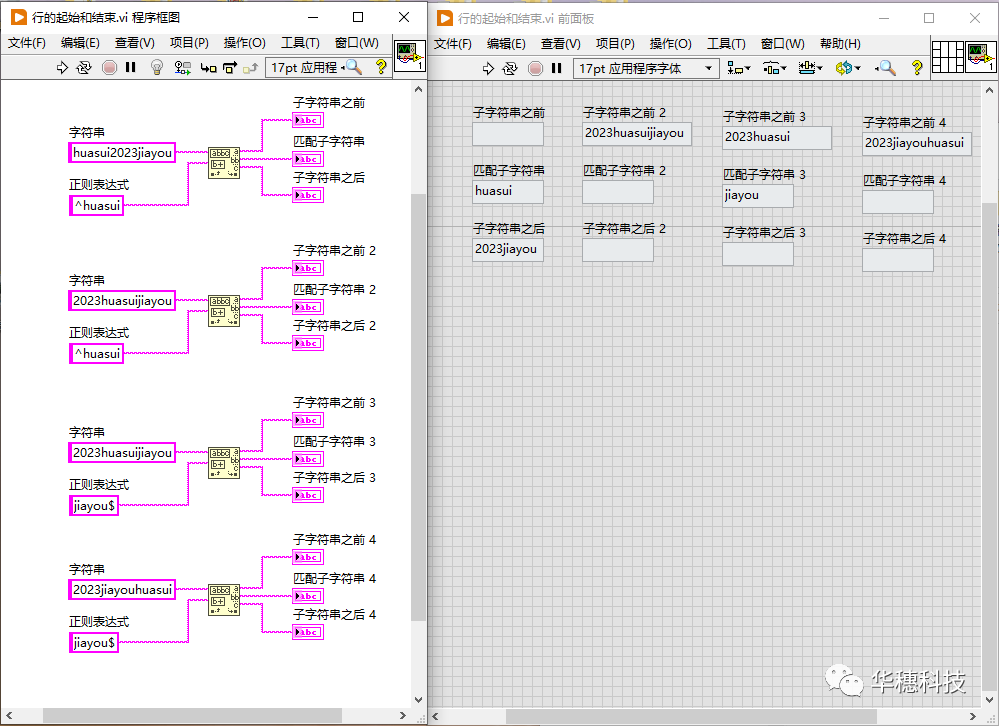
在正则表达式中,符号「^」代表一行的开始,符号「$」则代表结束。比如正则表达式「huasui」寻找的是一行文本中任意位置的 huasui,而「^huasui」只寻找行首的 huasui,同样「huasui$ 」只寻找位于行末的 huasui。在理解时应注意,元字符作用的是其紧挨着的一个字符。不要把「 ^huasui 」理解成匹配以 huasui开头的行,而应该理解成匹配的是以h作为一行的第一个字符,紧接一个 u,然后接一个a,再接一个s,之后接一个u,最后接一个i的文本。虽然在这个例子中,这两种理解的结果没有差异,但是按照作用于字符来解读更易于理解正则表达式的内部逻辑。
2. 匹配若干字符之一
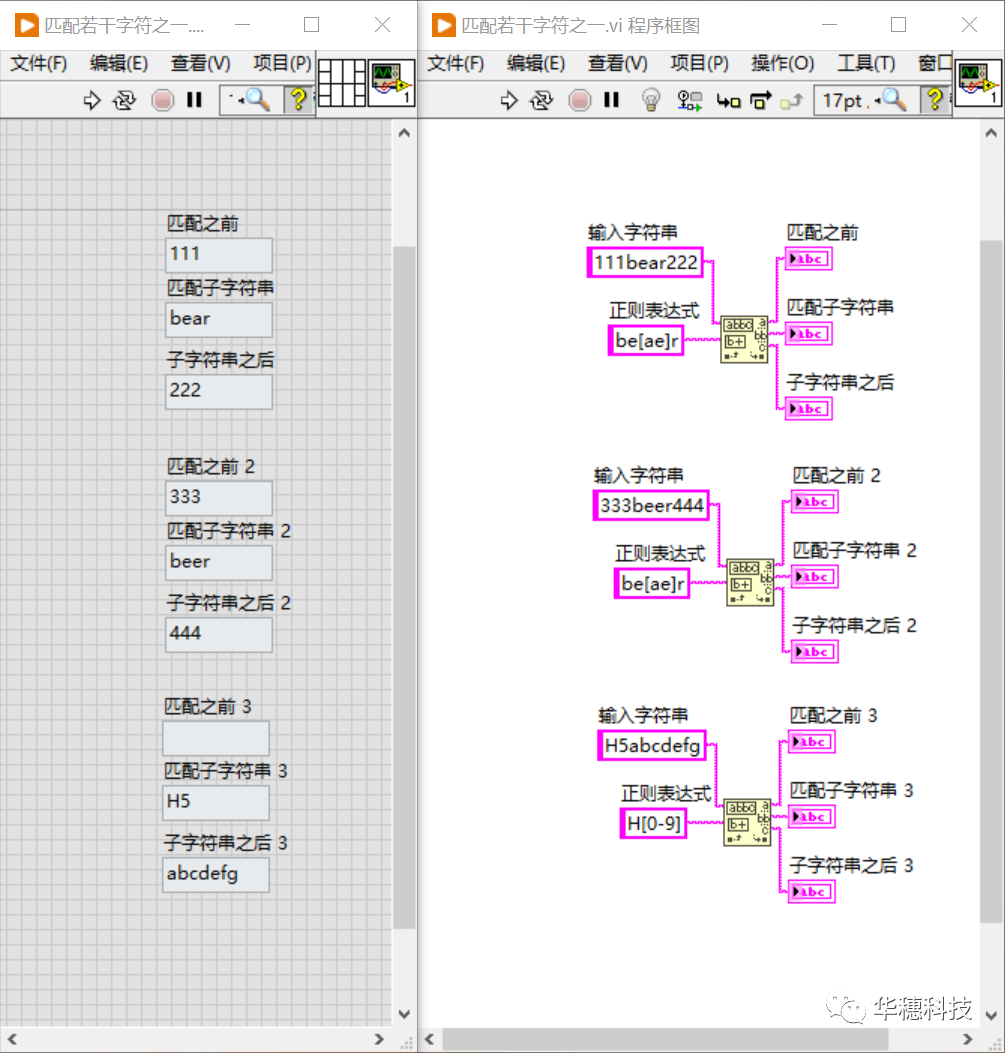
假如我们要找的单词是"bear",但又不确定它是不是写成"beer",那么就可以使用正则表达式结构体 「 [...] 」,它允许使用者列出在某处可能匹配的字符,通常被称作字符组,比如正则表达式「 be[ae]r」的意思是:先找到 b,然后跟着一个 e,再跟着一个 a 或 e,最后是一个r,所以该正则表达式可以匹配"bear"也可以匹配"beer"。 在字符组内可以使用字符组元字符 [-](连字符)来表示一个范围区间,比如正则表达式「 H[123456] 」与「 H[1-6] 」是等价的。「 [0-9] 」、「 [a-z] 」和 「 [A-Z] 」是常用的匹配数字、大小写字母的简洁表示。当然在一个字符组中也支持多重范围,比如「 [0123456789abcdef] 」可以写作「 [0-9a-f] 」。 需要注意的是:连字符[-]只有出现在字符组内部,且不处于开头处时,它才是一个元字符,否则就是普通的连字符号。
3. 排除型字符组
使用「 [^...] 」替代「 [...] 」,这个正则表达式可以匹配任何没有出现的字符,例如「 [^0-4] 」可以匹配除了0-4以外的任何字符。表达式中开头的 '^' 表示排除,所以它后面出现的字符都是不想匹配到的。
同样的元字符出现在不同的地方有不同的含义,这就像同一个语句用在不同的语境中,它要表达的意思是不同的。比如 '^' 在表达式外最开头的地方时表示一个行起始点,然而当它在表达式内部开头处时就表示排除。
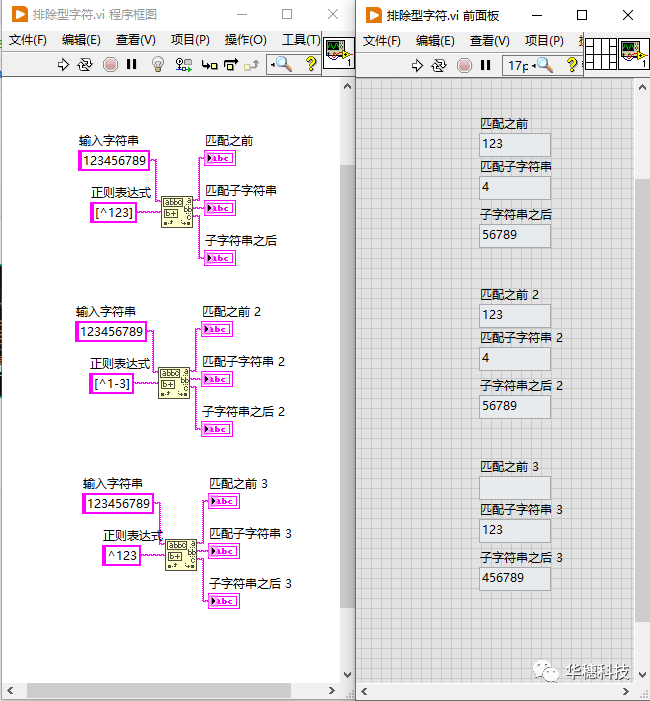
4. 匹配任意字符
元字符「 . 」可以用来匹配任意字符。如果需要在正则表达式中使用一个匹配任意字符的占位符,用元字符「 . 」就十分方便。比如在一个字符串中查找 “2023/01/01” 或“2023-01-01” 或者“2023.01.01”,我们可以将正则表达式写成「 2023[-./]01[-./]01 」,当然也可以简单的写成「2023.01.01」。
写正则表达式是一个寻求平衡的过程,它不是一味追求精简,比如上面的例子「2023[-./]01[-./]01」这种写法就要比「2023.01.01」表达的意思更加明确,但是写起来也更麻烦,而后面这种写法更加简单,但是匹配的不够精细。那么我们平时应该如何抉择?其实这取决于你对需要检索的文本的了解程度,以及你需要匹配的准确程度,在这二者之间寻求一个平衡。如果你确定在被检索的文本中使用「2023.01.01」去匹配不会得到其他非预期的结果,那么使用它就是简洁且合理的一种表示,但是当你不确定(比如被检索的文本中可能有一串数字2023001001),那么匹配就会得到非预期结果,此时应该选择更加精确的匹配方式「2023[-./]01[-./]01」。
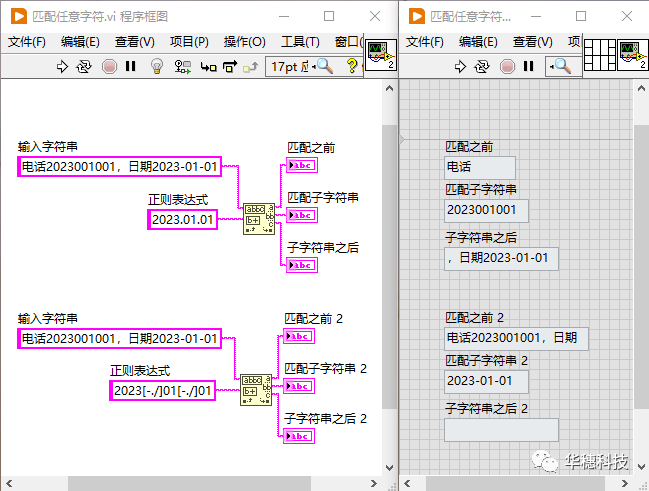
5. 匹配任意子表达式
元字符「 | 」可以让我们把不同的子表达式组合成一个总的表达式,并且这个总表达式又能匹配任意一个子表达式,所有的子表达式都被称为“多选分支”。举例说明:上面提到的正则表达式「be[ae]r」还能写作「bear|beer」或者写作「 be(a|e)r」。
使用「be(a|e)r」这种方式时圆括号是必要的,否则「 bea|er 」的含义就变成了匹配 “bea” 或 “er”,很显然这不是我们预期的,圆括号的作用是可以限制元字符「 | 」的生效范围。
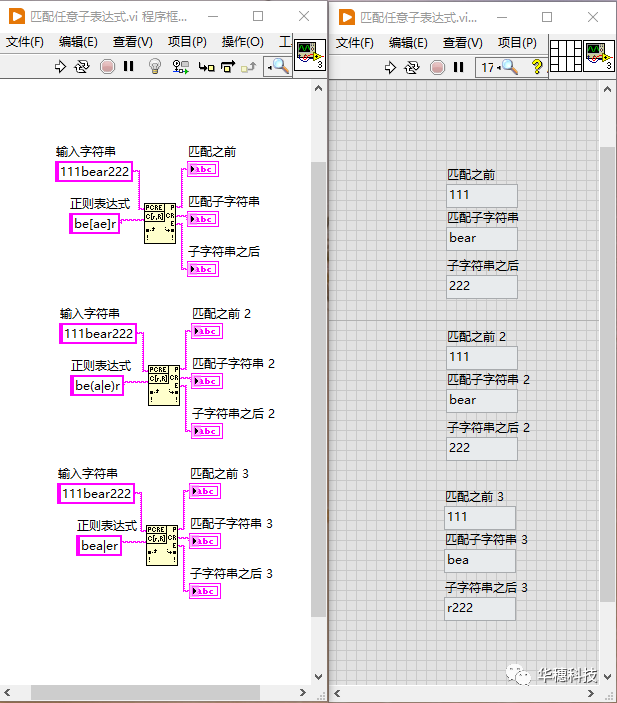
6. 可选项元素
元字符「 ? 」表示可选项,把它加在某个字符后面,就表示这里允许出现这个字符,但该字符并不是匹配成功的必要条件。该元字符只作用于它之前紧邻的一个元素。
比如6月份的英文是“June”,也能简写为“Jun”,所以我们既可以用「June|Jun」来匹配,也可以用「June?」来匹配。使用正则表达式来解决实际问题时,可能有很多不同的思路和方法,我们需要在其中寻找平衡。正则表达式不是死记硬背的公式,它其实灵活的像是一门艺术。
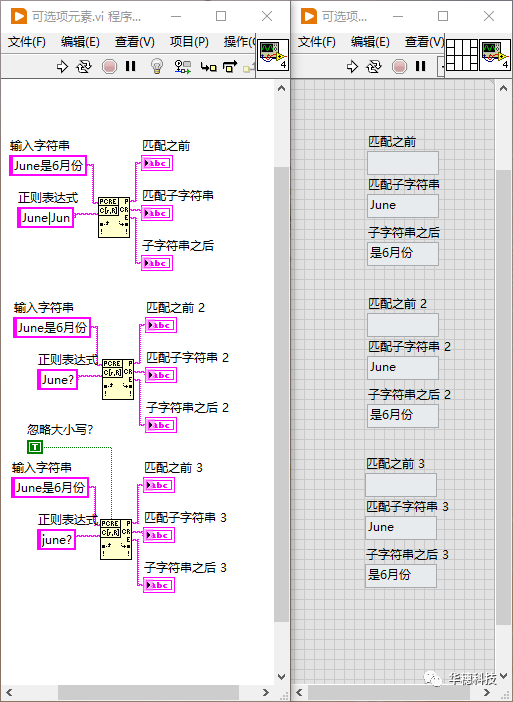
7. 重复出现
「 + 」和「 * 」的功能和「 ? 」类似,元字符「 + 」代表前面紧邻的字符出现一次或多次,而「 * 」代表前面紧邻的字符没有出现或出现多次。这三个元字符称作量词,因为它们限定了所作用字符的出现次数。 默认情况下,量词匹配将尽可能多地匹配,这种匹配方式被称作“贪婪匹配”。如果你希望尽可能少的匹配,那么就在字符串的后面加上[?]进行“非贪婪匹配“(也被称作“懒惰匹配“)。

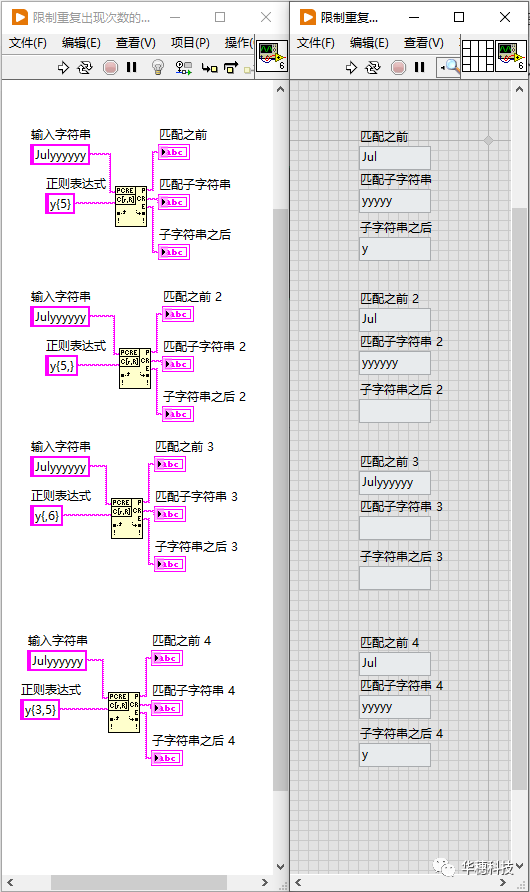
8. 限制重复出现次数的范围
元字符序列「 {min, max} 」可以表示重现次数的区间范围,所以它叫做区间量词,例如「 {2, 4} 」能够容许的重现次数在2到4之间,当然它还有其它几种用法,总结如下:
{n} 准确匹配n次
{n,} 至少匹配n次
{,n} 最多匹配n次
{n,m} 最少匹配n次,最多不超过m次
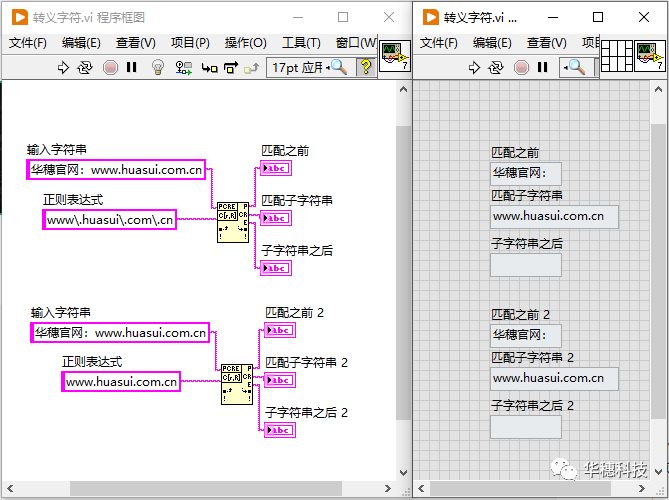
9. 转义字符
如果想匹配的某个字符本身就是一个元字符,那么就需要用到转义字符(反斜杠 '')。比如要匹配一个网址 "www.huasui.com.cn",如果不对[.]进行转义,正则表达式会认为这里的[.]是一个元字符,而不是普通的点号,所以正确的写法是「 www.huasui.com.cn 」。
四、 常用字符及其含义
| 字符 | 含义 |
| 匹配一个词语边界,也就是词语和空格间的位置。例如,'st' 可以匹配"test" 中的 'st',但不能匹配 "string" 中的 'st' | |
| B | 匹配非词语边界。'stB' 能匹配"string" 中的 'st',但不能匹配"test" 中的 'st' |
| d | 匹配一个数字字符。等价于 [0-9] |
| D | 匹配一个非数字字符。等价于 [^0-9] |
| s | 匹配任意空白字符,包括空格、换页符、制表符等。等价于 [ f v]。 |
| S | 匹配任意非空白字符。等价于 [^ f v] |
| w | 匹配包含下划线的任意单词字符。等价于'[A-Za-z0-9_]' |
| W | 匹配任意非单词字符。等价于 '[^A-Za-z0-9_]' |
| 匹配制表符。等价于 x09 和 cI | |
| 匹配换行符。等价于 x0a 和 cJ | |
| 匹配回车符。等价于 x0d 和 cM |
五、 常用匹配组
| 匹配组 | 含义 |
| (demo) | 匹配demo并获取一个自动命名的组 |
|
(? |
匹配demo并获取组’name’ |
| (?=demo) |
demo出现在声明右侧,但demo不作为匹配结果返回。 例如: 输入:public keywod string "xyz"; 正则:w+(?=wod),返回“key”, 含义:匹配以wod结束的单词,但不返回wod |
| (?<=demo) |
demo出现在声明左侧,但demo不作为匹配结果返回 例如: 输入:public remember string "abc"; 正则:(?<=str)w+,返回“ing”, 含义:匹配以str开头的单词,但不返回str |
| (?!demo) |
demo不出现在声明右侧,且demo不作为匹配结果返回 例如: 输入:remember bwa cwe "abc"; 正则:w*w(?!a)w*,返回“cwe”, 含义:匹配带w后面不是跟随a的单词 |
| (?demo) | demo不出现在声明左侧,但demo不作为匹配结果返回 |
审核编辑:汤梓红
-
使用 Linux/Unix 进行文本处理2015-11-24 0
-
shell正则表达式学习2015-07-25 0
-
初识 Python 正则表达式2022-03-17 0
-
正则表达式以及实用的匹配规则概述2022-09-16 0
-
深入浅出boost正则表达式2010-09-08 364
-
基于正则表达式的数据处理应用方斌2017-03-15 711
-
关于java正则表达式的用法详解2017-09-27 476
-
Python正则表达式的学习指南2020-09-15 644
-
Python正则表达式指南2021-03-26 601
-
python正则表达式中的常用函数2022-03-18 1570
-
在Python中使用正则表达式的一些基本语法演示2023-04-15 883
-
Linux入门之正则表达式2023-05-12 579
-
Python中的正则表达式2023-06-21 731
-
什么是正则表达式?正则表达式如何工作?哪些语法规则适用正则表达式?2023-11-03 576
-
linux正则表达式匹配字符串2023-11-23 344
全部0条评论

快来发表一下你的评论吧 !
