

详解图神经网络的数学原理3
电子说
描述
流行图神经网络总结
上面我们介绍完了古神经网络的基本流程,下面我们总结一下流行图神经网络,并将它们的方程和数学分为上面提到的3个GNN步骤。许多体系结构将消息传递和聚合步骤合并到一起执行的一个函数中,而不是显式地一个接一个执行,但为了数学上的方便,我们将尝试分解它们并将它们视为一个单一的操作!
1、消息传递神经网络
https://arxiv.org/abs/1704.01212
消息传递神经网络(MPNN)将正向传播分解为具有消息函数Ml的消息传递阶段和具有顶点更新函数Ul的读出阶段
MPNN将消息传递和聚合步骤合并到单个消息传递阶段:
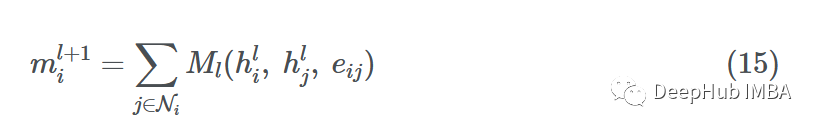
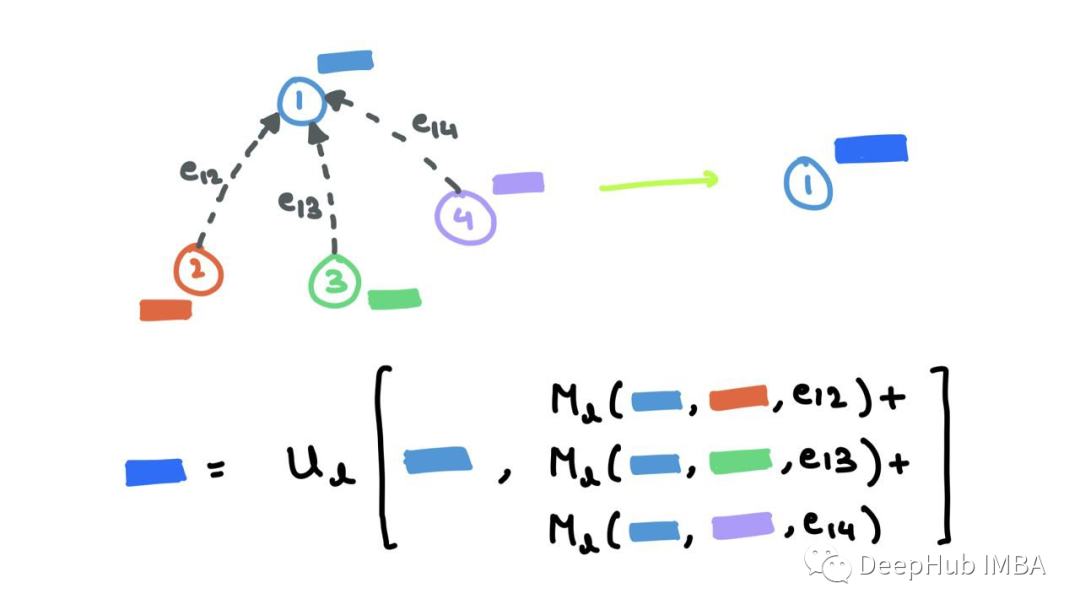
读取阶段是更新步骤:

其中ml+1v是聚合的消息,hl+1v是更新的节点嵌入。这与我上面提到的过程非常相似。消息函数Ml是F和G的混合,函数Ul是k,其中eij表示可能的边缘特征,也可以省略。
2、图卷积
https://arxiv.org/abs/1609.02907
图卷积网络(GCN)论文以邻接矩阵的形式研究整个图。在邻接矩阵中加入自连接,确保所有节点都与自己连接以得到~A。这确保在消息聚合期间考虑源节点的嵌入。合并的消息聚合和更新步骤如下所示:

其中Wl是一个可学习参数矩阵。这里将X改为H,以泛化任意层l上的节点特征,其中H0=X。
由于矩阵乘法的结合律(A(BC)=(AB)C),我们在哪个序列中乘矩阵并不重要(要么是AHl先乘,然后是Wl后乘,要么是HlWl先乘,然后是A)。作者Kipf和Welling进一步引入了度矩阵~D作为"renormalisation"的一种形式,以避免数值不稳定和爆炸/消失的梯度:

“renormalisation”是在增广邻接矩阵^A=D−12A~D−12上进行的。新的合并消息传递和更新步骤如下所示:

3、图注意力网络
https://arxiv.org/abs/1710.10903
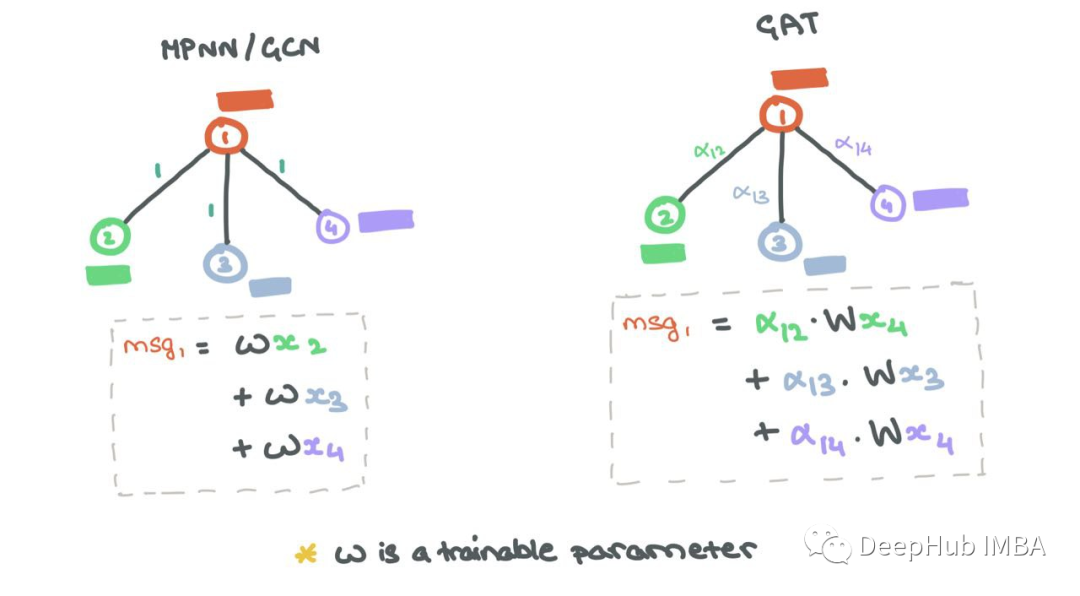
聚合通常涉及在和、均值、最大值和最小值设置中平等对待所有邻居。但是在大多数情况下,一些邻居比其他邻居更重要。图注意力网络(GAT)通过使用Vaswani等人(2017)的Self-Attention对源节点及其邻居之间的边缘进行加权来确保这一点。
边权值αij如下。
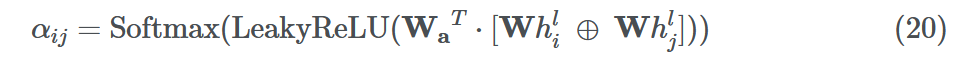
这里的Wa∈R2d '和W⊆Rd ' ×d为学习参数,d '为嵌入维数,⊕是向量拼接运算。
虽然最初的消息传递步骤与MPNN/GCN相同,但合并的消息聚合和更新步骤是所有邻居和节点本身的加权和:
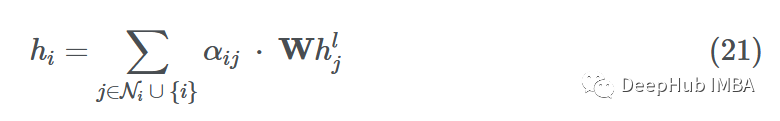
边缘重要性加权有助于了解邻居对源节点的影响程度。与GCN一样,添加了自循环,因此源节点可以将自己的表示形式考虑到未来的表示形式中。
4、GraphSAGE
https://arxiv.org/abs/1706.02216
GraphSAGE:Graph SAmple and AggreGatE。这是一个为大型、非常密集的图形生成节点嵌入的模型。
这项工作在节点的邻域上引入了学习聚合器。不像传统的gat或GCNs考虑邻居中的所有节点,GraphSAGE统一地对邻居进行采样,并对它们使用学习的聚合器。
假设我们在网络(深度)中有L层,每一层L∈{1,…,L}查看一个更大的L跳邻域w.r.t.源节点。然后在通过MLP的F和非线性σ传递之前,通过将节点嵌入与采样消息连接来更新每个源节点。
对于某一层l
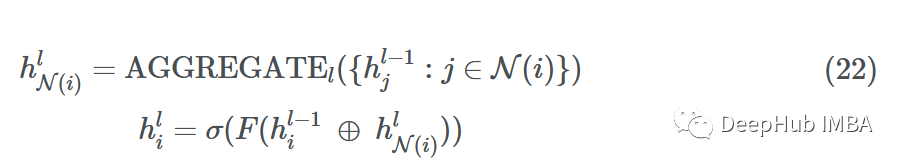
其中⊕是向量拼接运算,N(i)是返回所有邻居的子集的统一抽样函数。如果一个节点有5个邻居{1,2,3,4,5},N(i)可能的输出将是{1,4,5}或{2,5}。
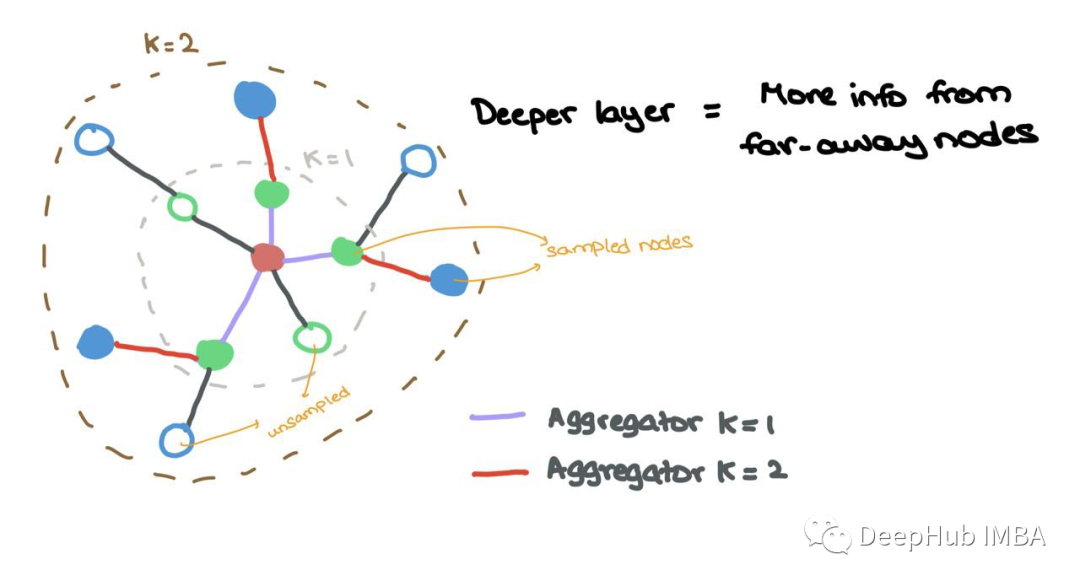
Aggregator k=1从1-hop邻域聚集采样节点(彩色),而Aggregator k=2从2 -hop邻域聚集采样节点(彩色)
论文中用K和K表示层指数。但在本文中分别使用L和L来表示,这是为了和前面的内容保持一致性。此外,论文用v表示源节点i,用u表示邻居节点j。
5、时间图网络
https://arxiv.org/abs/2006.10637
到目前为止所描述的网络工作在静态图上。大多数实际情况都在动态图上工作,其中节点和边在一段时间内被添加、删除或更新。时间图网络(TGN)致力于连续时间动态图(CTDG),它可以表示为按时间顺序排列的事件列表。
论文将事件分为两种类型:节点级事件和交互事件。节点级事件涉及一个孤立的节点(例如:用户更新他们的个人简介),而交互事件涉及两个可能连接也可能不连接的节点(例如:用户a转发/关注用户B)。
TGN提供了一种模块化的CTDG处理方法,包括以下组件:
- 消息传递函数→孤立节点或交互节点之间的消息传递(对于任何类型的事件)。
- 消息聚合函数→通过查看多个时间步长的时间邻域,而不是在给定时间步长的局部邻域,来使用GAT的聚合。
- 记忆更新→记忆(Memory)允许节点具有长期依赖关系,并表示节点在潜在(“压缩”)空间中的历史。这个模块根据一段时间内发生的交互来更新节点的内存。
- 时间嵌入→一种表示节点的方法,也能捕捉到时间的本质。
- 链接预测→将事件中涉及的节点的时间嵌入通过一些神经网络来计算边缘概率(即,边缘会在未来发生吗?)。在训练过程中,我们知道边的存在,所以边的标签是1,所以需要训练基于sigmoid的网络来像往常一样预测这个。
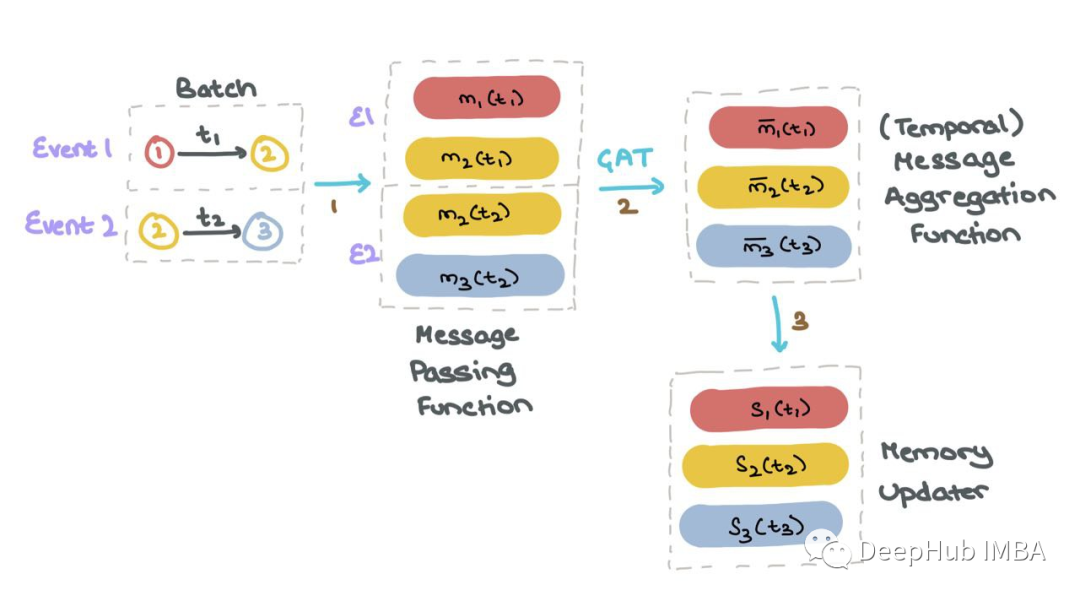
每当一个节点参与一个活动(节点更新或节点间交互)时,记忆就会更新。
对于批处理中的每个事件1和2,TGN为涉及该事件的所有节点生成消息。TGN聚合所有时间步长t的每个节点mi的消息;这被称为节点i的时间邻域。然后TGN使用聚合消息mi(t)来更新每个节点si(t)的记忆。
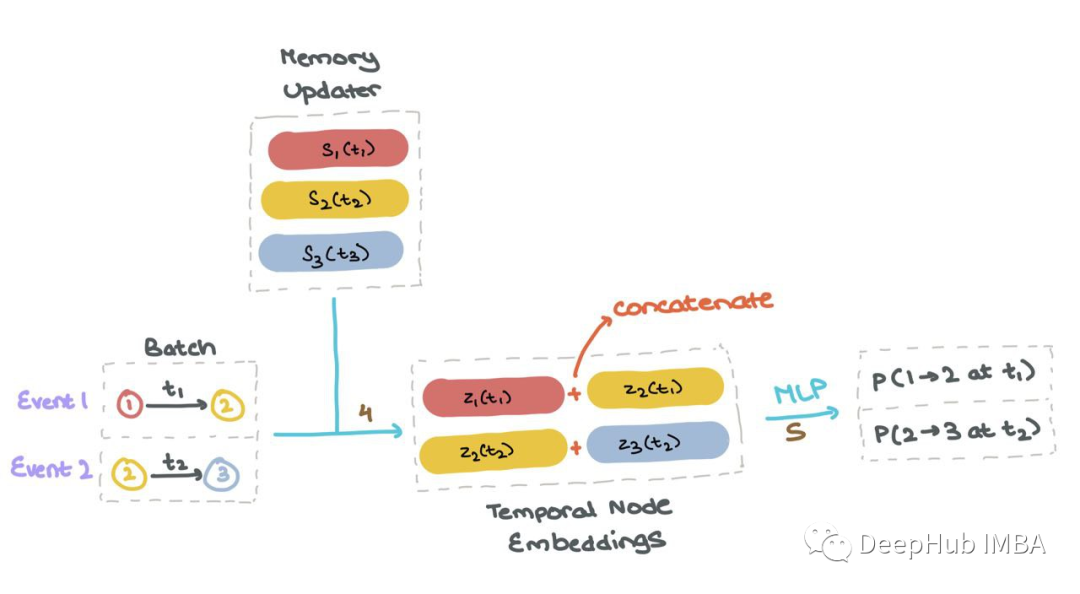
一旦所有节点的内存si(t)是最新的,它就用于计算批处理中特定交互中使用的所有节点的“临时节点嵌入”zi(t)。然后将这些节点嵌入到MLP或神经网络中,获得每个事件发生的概率(使用Sigmoid激活)。这样可以像往常一样使用二进制交叉熵(BCE)计算损失。
总结
上面就是我们对图神经网络的数学总结,图深度学习在处理具有类似网络结构的问题时是一个很好的工具集。它们很容易理解,我们可以使用PyTorch Geometric、spectral、Deep Graph Library、Jraph(jax)以及TensorFlow-gnn来实现。GDL已经显示出前景,并将继续作为一个领域发展。
-
matlab 中亮剑数学 全面掌握控制 神经网络就在脚下2013-07-30 0
-
关于开关磁阻电机的matlab BP神经网络数学建模方面的资料2014-11-17 0
-
卷积神经网络入门资料2019-02-12 0
-
【PYNQ-Z2试用体验】神经网络基础知识2019-03-03 0
-
卷积神经网络如何使用2019-07-17 0
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 0
-
BP神经网络的基础数学知识分享2020-06-16 0
-
如何构建神经网络?2021-07-12 0
-
卷积神经网络模型发展及应用2022-08-02 0
-
卷积神经网络的数学原理介绍2019-04-22 4598
-
深入卷积神经网络背后的数学原理2019-04-25 3371
-
深度:了解训练神经网络时所用到的数学过程2019-07-15 3843
-
图解:卷积神经网络数学原理解析2022-09-16 1091
-
详解图神经网络的数学原理12023-03-17 463
-
详解图神经网络的数学原理22023-03-17 387
全部0条评论

快来发表一下你的评论吧 !
