

线性判别分析LDA背后的数学原理
电子说
描述
线性判别分析(LDA)是一种降维技术,其目标是将数据集投影到较低维度空间中。线性判别分析也被称为正态判别分析(NDA)或判别函数分析,是Fisher线性判别的推广。
线性判别分析(LDA)和主成分分析(PCA)都是常用的线性变换技术,用于降低数据的维度。
PCA可以描述为“无监督”算法,因为它“忽略”类别标签,其目标是找到最大化数据集方差的方向(所谓的主成分)。
与PCA不同,LDA是“有监督的”,它计算出能够最大化多个类别之间间隔的轴(“线性判别”)。
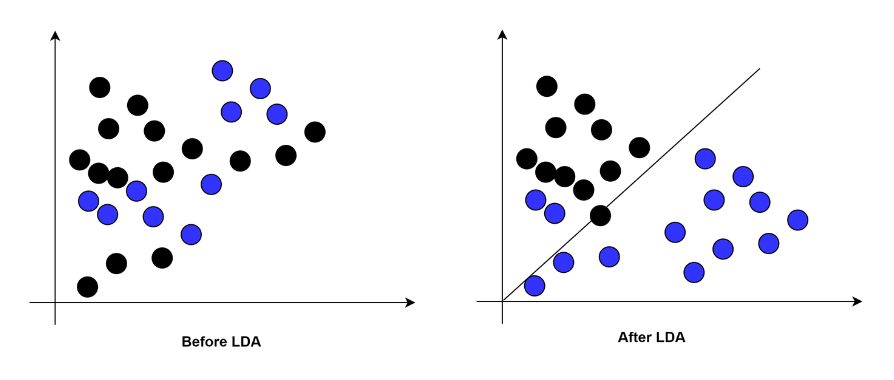
LDA是如何工作的?
LDA使用Fisher线性判别方法来区分类别。
Fisher线性判别是一种分类方法,它将高维数据投影到一维空间中,并在这个一维空间中进行分类。
投影最大化类别均值之间的距离,同时最小化每个类别内部的方差。
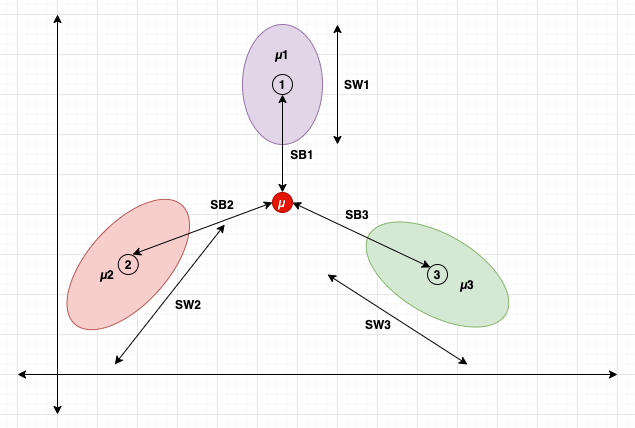
类别:1、2和3
类别均值:µ1、µ2和µ3
类别间散布:SB1、SB2和SB3
类别内散布:SW1、SW2和SW3
数据集均值:µ
它的思想是最大化类别间散布SB,同时最小化类别内散布SW。
数学公式


动机
-
寻找一个方向,可以放大类间差异。
-
最大化投影后的均值之间的(平方)差异。
(通过找到最大化类别均值之间差异的方向,LDA可以有效地将数据投影到一个低维子空间中,其中类别更容易分离)
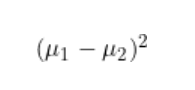
-
最小化每个类别内的投影散布
(通过找到最大化类别均值之间差异的方向,LDA可以有效地将数据投影到一个低维子空间中,其中类别更容易分离)
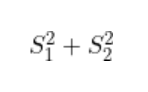
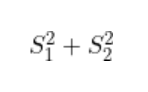
散布
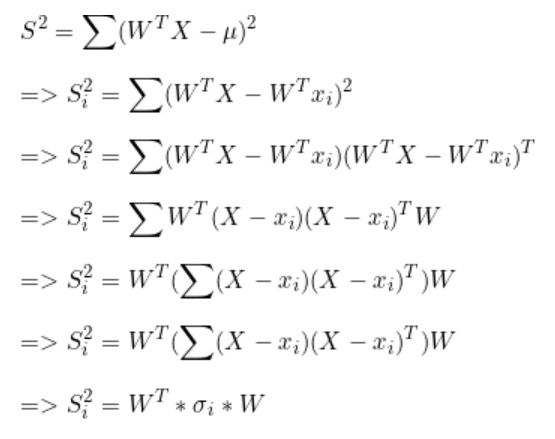

均值差异
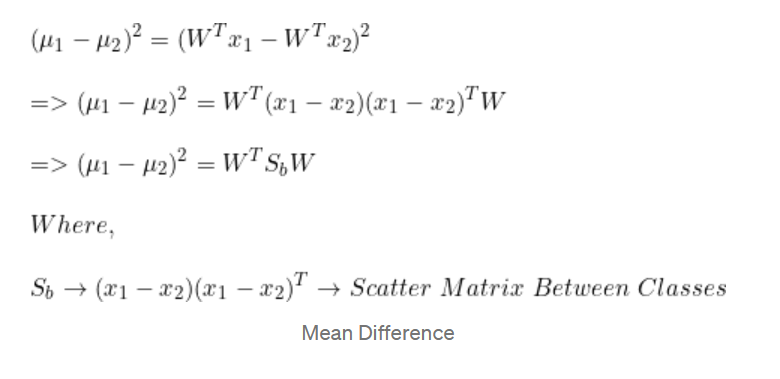
散布差异

Fischer 指数
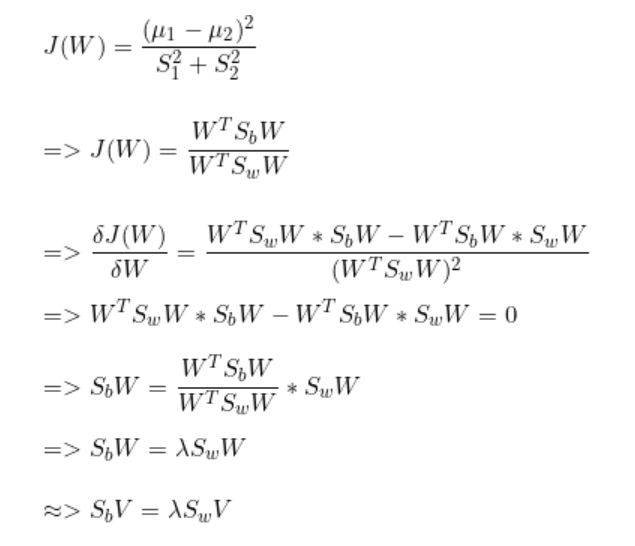

这意味着在选择特征值时,我们将始终选择C-1个特征值及其相应的特征向量。其中,C为数据集中的类别数。
例子
**数据集
**
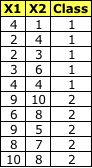
步骤1:计算类内散布矩阵(SW)

计算每个类别的协方差矩阵
类别1:
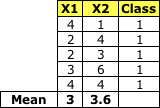
Class 1
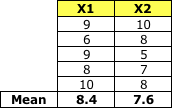
均值矩阵:

协方差:

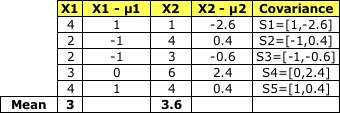
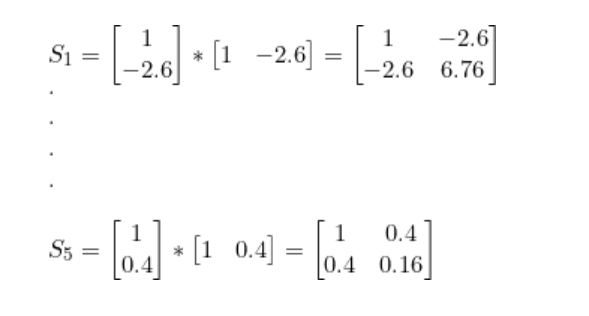
将S1到 S5加在一起就得到了 Sc1
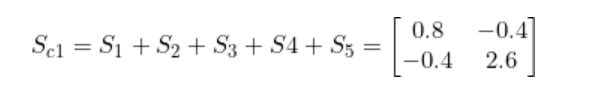
类别2:
Class 2
均值矩阵:
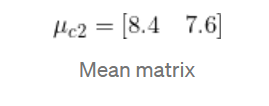
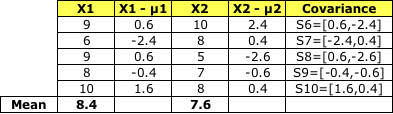
和 Sc1一样, 将S6 到S10加到一起, 就得到了协方差 Sc2 -
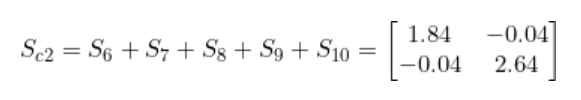
将Sc1和Sc2相加就得到了类内散布矩阵Sw。
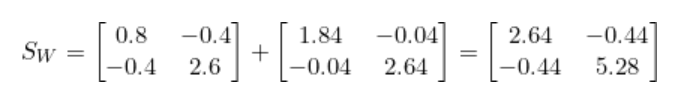
步骤2:计算类间散布矩阵(SB)
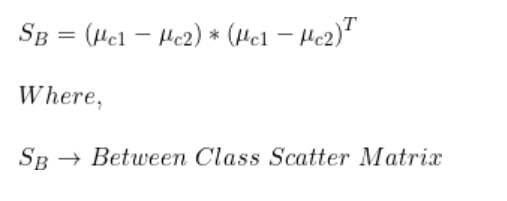
我们已经有了类别1和类别2每个特征的均值。
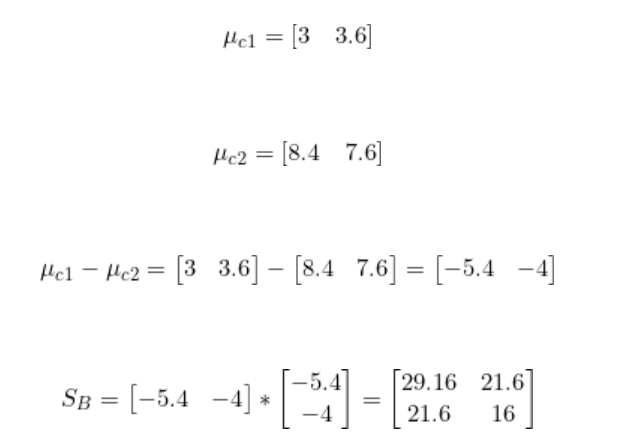
步骤3:找到最佳LDA投影向量
与PCA类似,我们使用具有最大特征值的特征向量来找到最佳投影向量。该特征向量可以用以下形式表示。
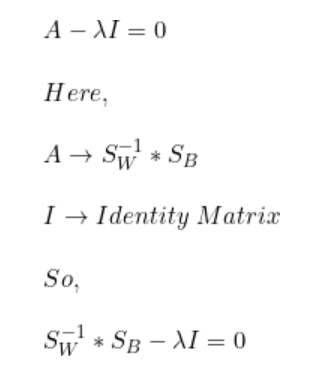
我们已经计算得到了SB和SW。
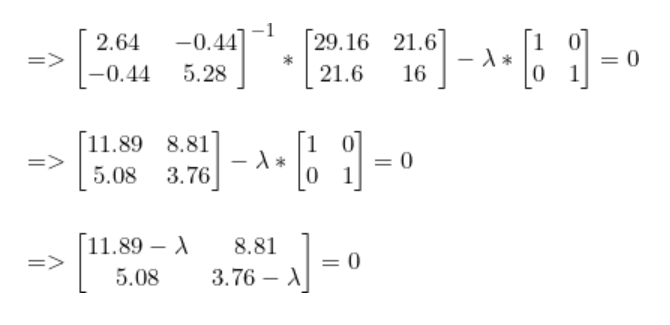
解出lambda后,我们得到最高值lambda = 15.65。现在,对于每个lambda值,解出相应的向量。
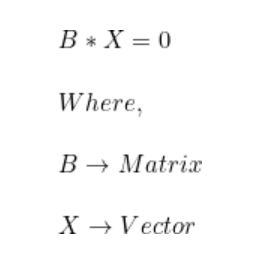
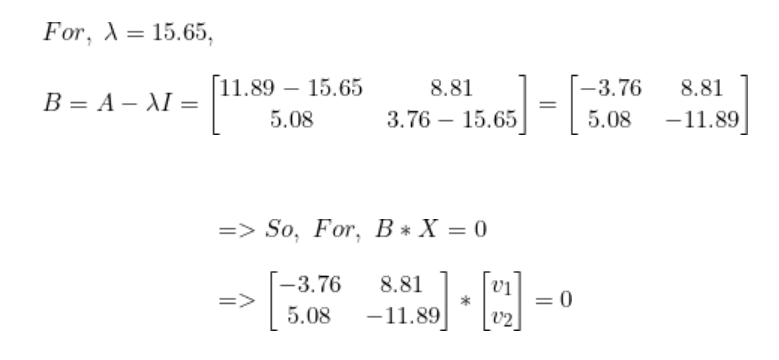
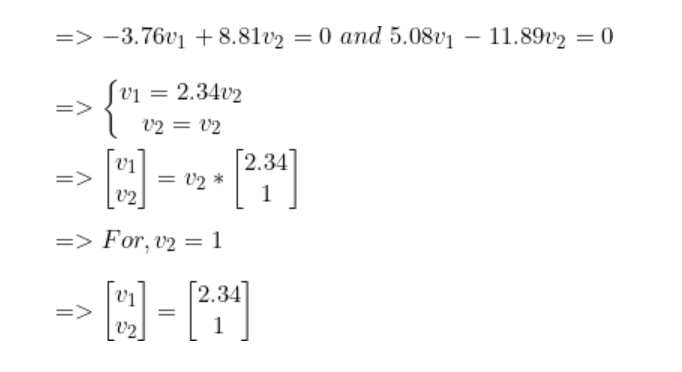
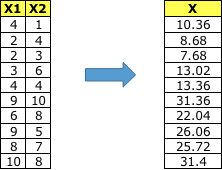
步骤4:将样本转换到新子空间上。

因此,使用LDA我们进行了如下转换。
-
GraphSAGEGNN算法的数学原理是什么?2021-06-17 0
-
变压变频调速的数学原理是什么2021-08-03 0
-
基于核函数的Fisher判别分析算法在人耳识别中的应用2009-05-30 627
-
近邻边界Fisher判别分析2009-11-21 666
-
虚电压的判别分析图2009-08-08 1417
-
dq坐标变换数学原理2016-12-20 893
-
不相关判别分析算法在人脸识别中应用2017-11-22 332
-
人脸识别经典算法三:Fisherface(LDA)2017-12-04 1617
-
核局部Fisher判别分析的行人重识别2017-12-13 782
-
基于逐步判别分析的血液气味识别2018-01-04 649
-
基于监督局部线性嵌入的中药材分类鉴别研究2018-01-14 604
-
利用基于线性判别分析的多变量分析模型对豇豆种子进行分类2019-03-29 2235
-
深入卷积神经网络背后的数学原理2019-04-25 3362
-
十大机器学习算法中的线性判别分析的详细介绍2020-02-03 7031
全部0条评论

快来发表一下你的评论吧 !
