

In-context learning介绍
描述
1 简介
随着大规模预训练语言模型(LLM)能力的不断提升,in-context learning(ICL)逐渐成为自然语言处理领域一个新的范式。ICL通过任务相关的若干示例或者指令来增强上下文,从而提升语言模型预测效果,通过探索ICL的性能来评估跟推断LLM能力也成为一种新的趋势。
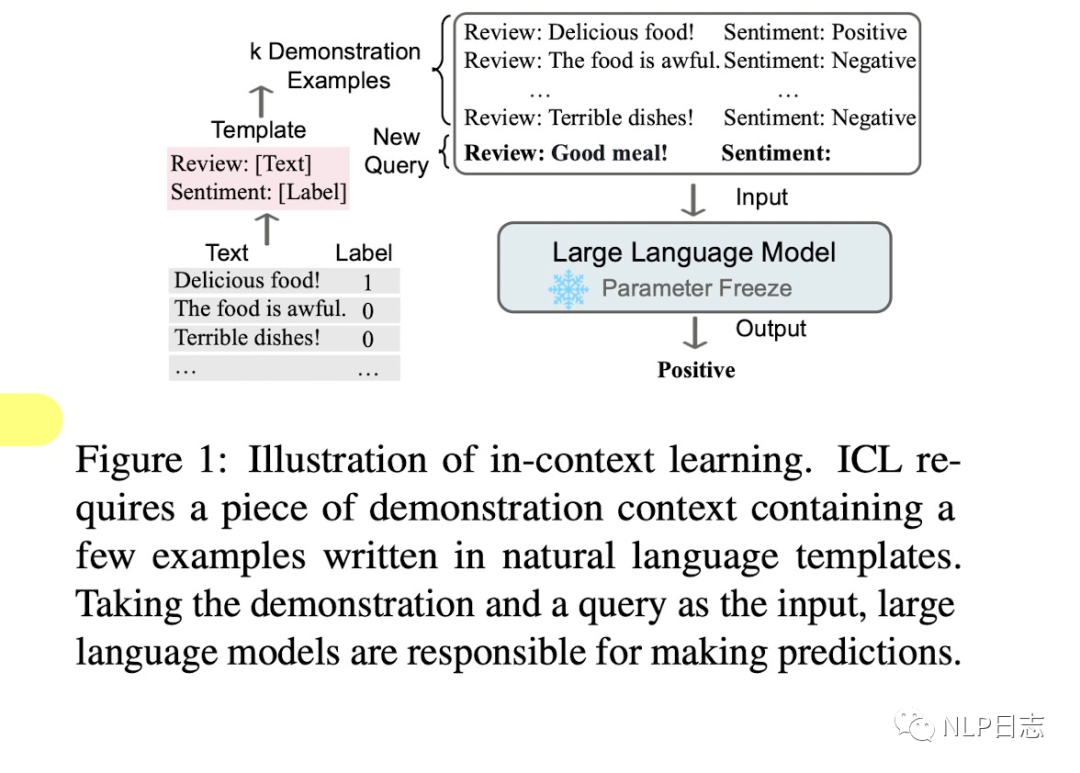
图1: In-context learning示例
2 介绍
In-context learning是一种学习范式,它允许语言模型通过以演示形式组织的若干个示例或者指令来学习任务。In-context learning的核心在于从任务相关的类比样本中学习,ICL要求若干示例以特定形式进行演示,然后将当前输入x跟上述示例通过prompt拼接到一起作为语言模型的输入。本质上,它利用训练有素的语言模型根据演示的示例来估计候选答案的可能性。简单理解,就是通过若干个完整的示例,让语言模型更好地理解当前的任务,从而做出更加准确的预测。
从定义上可以发现in-context learning跟其他相关概念的差异,比如prompt learning跟few-shot learning。Prompt learning是通过学习合适的prompt来鼓励模型预测出更加合适的结果,而prompt既可以是离散型,也可以是连续型。严格来讲,in-context learning可以视为prompt learning中的一小部分,如果将in-context learning中的若干示例的演示视作prompt的话。Few-shot learning指的是在给定少量监督数据下利用参数更新来学习最佳模型参数的训练方法,但in-context learning则不然,它不要求参数更新。
In-context learning有以下几个优势,
a) 若干示例组成的演示是用自然语言撰写的,这提供了一个跟LLM交流的可解释性手段,通过这些示例跟模版让语言模型更容易利用到人类的知识。
b) 类似于人类类比学习的决策过程,举一反三。
c) 相比于监督学习,它不需要模型训练,减小了计算模型适配新任务的计算成本,更容易应用到更多真实场景。
3 方法
In-context learning可以分为两部分,分为作用于Training跟inference阶段
3.1 Training
在推理前,通过持续学习让语言模型的ICL能力得到进一步提升,这个过程称之为warmup,warmup会优化语言模型对应参数或者新增参数,区别于传统的finetune,finetune旨在提升LLM在特定任务上的表现,而warmup则是提升模型整理的ICL性能。
Supervised in-context training
通过构建对应的in-context的监督数据跟多任务训练,进行对应的in-context finetune,从而缩小预训练跟下游ICL的差距。除此之外,instruct tuning通过在instruction上训练能提升LLM的ICL能力。
Self-supervised in-context training
根据ICL的格式将原始数据转换成input-output的pair对数据后利用四个自监督目标进行训练,包括掩码语言,分类任务等。
Supervised training跟self-supervised training旨在通过引入更加接近于in-context learning的训练目标从而缩小预训练跟ICL之间的差距。比起需要示例的in-context finetuning,只涉及任务描述的instruct finetuning更加简单且受欢迎。另外,在warmup这个阶段,语言模型只需要从少量数据训练就能明显提升ICL能力,不断增加相关数据并不能带来ICL能力的持续提升。从某种角度上看,这些方法通过更加模型参数可以提升ICL能力也表明了原始的LLM具备这种潜力。虽然ICL不要求warmup,但是一般推荐在推理前增加一个warmup过程。
3.2 Inference
很多研究表明LLM的ICL性能严重依赖于演示示例的格式,以及示例顺序等等,在使用目前很多LLM模型时我们也会发现,在推理时,同一个问题如果加上不同的示例,可能会得到不同的模型生成结果。
Demonstration Selection
对于ICL而言,那些样本是好的?语言模型的输入长度是有限制的,如何从众多的样本中挑选其中合适的部分作为示例这个过程非常重要。按照选择的方法主要可以分为无监督跟有监督两种。
其中无监督的方法分为以下几种,首先就是根据句向量距离或者互信息等方式选择跟当前输入x最相似的样本作为演示例,另外还有利用自使用方法去选择最佳的示例排列,有的方法还会考虑到演示示例的泛化能力,尽可能去提高示例的多样性。除了上述这些从人工撰写的样本中选择示例的方式外,还可以利用语言模型自身去生成合适的演示示例。
至于监督的方法也有几种,第一种是先利用无监督检索器召回若干相似的样本,再通过监督学习训练的Efficient Prompt Retriever进行打分,从而筛选出最合适的样本。此外还有基于prompt tuning跟强化学习的方式去选择样本。
Demonstration ordering
挑选完演示示例后,如何对其进行排序也非常重要。排序的方法既有不需要训练的,也有根据示例跟当前输入距离远近进行排序的,也可以根据自定义的熵指标进行重排。
Demonstration Formatting
如何设计演示示例的格式?最简单的方式就是将示例们的x-y对按照顺序直接拼接到一起。但是对于复杂的推理问题,语言模型很难直接根据x推理出y,这种格式就不适用了。另外,有的研究旨在设计更好的任务指令instruction作为演示内容,上述的格式也就不适用了。对于这两类场景,除了人工撰写的方式外,还可以利用语言模型自身去生成对应的演示内容。
4 总结
上面关于in-context learning的介绍可能会让人感到些许困惑,instruction tuning也算是其中一种,但是instruction里不一定有演示示例,我个人想法也是如此,如果大多数instruction里也会提及对应的任务示例,但是不排除部分instruction只涉及到任务定义,所以前面将in-context learning跟任务示例强绑定可能就不太严谨了。但是大家能理解其中的含义即可,也没必要深究其中的某些表述。
毋庸置疑,在大规模语言模型能力快速提升的今天,in-context learning的热度还将持续一段时间,如何通过构建合适的in-context来进一步激发语言模型在特定任务下的表现是值得思考的问题,如果能让语言模型自身去写对应的任务示例或者指令,让模型自己指导自己执行任务,不就进一步解放生产力了嘛。细品下autoGPT,不也是ai自己指导自己完成任务嘛。
审核编辑:刘清
-
LEARNING_ROBOTICS_USING_PYTHON2016-09-28 0
-
Learning ROS for Robotics Programming - Second Edition2016-09-28 0
-
Ensemble Learning Task2021-07-07 0
-
基于双估计器的Speedy Q-learning算法2021-05-18 499
-
一文解析In-Context Learning2023-03-22 1541
-
In-context learning如何工作?斯坦福学者用贝叶斯方法解开其奥秘2023-04-11 1095
-
In-Context-Learning在更大的语言模型上表现不同2023-06-12 476
-
首篇!Point-In-Context:探索用于3D点云理解的上下文学习2023-07-13 433
-
关于GO CONTEXT机制实现原则2023-11-16 184
全部0条评论

快来发表一下你的评论吧 !
