

DropMessage:统一的图神经网络随机Dropping方法
描述
主要贡献
文本提出了一个全新的随机Dropping方法,该方法在消息传递的过程中直接对被传递的消息进行dropping操作,统一了图神经网络的随机dropping架构。
第一章 摘要
图神经网络是图表示学习的重要工具。但尽管图神经网络的研究发展迅速,我们依然面临着很多挑战,例如:过拟合、过平滑和低鲁棒性这些问题。以前的工作表明这些问题可以通过随机droppping方法得到缓解,即通过随机遮掩掉部分输入来将增强数据喂给模型。然而,在图神经网络上应用随机dropping方法仍有很多问题待被解决。首先,考虑到不同数据集和模型的差异,找到一种适用于所有情况的通用方法是很困难的。其次,在图神经网络中引入增强数据会导致参数覆盖不完全和训练过程不稳定的现象。第三,现今没有在理论层面上分析随机dropping方法在图神经网络上的有效性。
在本文,我们提出了一个全新的随机droppping方法——DropMessage,该方法在消息传递过程中直接对被传递的消息进行dropping操作。更重要的是,我们发现DropMessage为大多数现有的随机dropping方法提供了一个统一的框架,并在此基础上我们还对其有效性进行了理论分析,以进一步阐述了DropMessage的优越性:它通过减小样本方差来稳定训练过程;从信息论的角度来看,它保持了信息的多样性,这使其成为其他方法的理论上限。为了评估所提出的DropMessage方法,我们在五个公共数据集和两个工业数据集上进行了多个任务的实验。实验结果表明:DropMessage有效性且泛化性强,能够显著缓解上述提到的问题。
第二章 简介及背景
图在现实世界里面无处不在,被用于在许多领域中呈现各种事物之间的复杂关系,图神经网络更是研究图表示学习的重要工具。图神经网络使用信息传递的方法并可以应用到大量的下游任务中。其中消息传递就是图神经网络在每个卷积层中的各个节点都会聚合其邻居信息的行为。
但是图神经网络的训练面临着很多挑战。因为与其他数据形式相比,为图数据收集标签是昂贵的并且会有必然的偏差,这限制了图神经网络的泛化能力。此外,由于递归地聚合来自其邻居的信息,图神经网络中不同节点的表示往往变得越来越相似。
使用随机dropping方法可以缓解上述问题,但是摘要中所提到的三大问题依然存在着。在本文,我们提出的全新的随机Dropping方法DropMessage可以有效解决这些问题。
第三章 数学符号和预备知识
第一节 符号
1. 表示图
2. ={ }表示图中的节点
3. 表示边
4. 结点特征表示为矩阵 ,其中 是结点 的特征向量, 是结点特征的维数
5. 邻接矩阵表示为 ,其中 表示邻接矩阵的第 行, 表示结点 和 之间的关系
6. 结点的度表示为 ,其中 表示为连接到结点 的度权重之和 7. 信息传递矩阵表示为 ,其中 是消息的维数
第二节 消息传递的图神经网络
图神经网络大多采用信息传递框架,消息在结点及其邻居之间传递。在传递的过程中,结点的表示不断更新,下面是它的更新公式: 其中 表示结点 在第 1 层的特征表示; 表示结点 的邻居; 和 是可微分的函数;AGG代表聚合操作。从信息传递的角度来看,我们可以将所有传播的消息集合到一个消息矩阵 中,其表示为:
第四章 方法
第一节DropMessage第一小节 算法描述
不同于现有的随机dropping方法,DropMessage在消息矩阵 上工作而不是邻接矩阵,即DropMessage直接在消息矩阵M上以概率 执行drop操作。具体来说,我们会根据伯努利分布 生成一个和消息矩阵同大小的掩码矩阵,消息矩阵中的每个元素由对应位置的掩码矩阵中的值来决定以多大的程度被drop,drop之后的消息矩阵 表示为:
第二小节 具体实现
在具体实现的过程中,我们不需要额外的时间或空间复杂度来执行DropMessage,因为消息矩阵中的每一行都表示图中的一条不同的有向边,并且DropMessage方法可以独立地在每个有向边上执行。这个特性使得DropMessage可以有效地并行化。
第三小节 统一随机dropping方法
引理1 Dropout DropEdge DropNode DropMessage都依据着各自的规则在消息矩阵上执行随机掩码对于Dropout方法,Dropping在特征矩阵 中的元素 等价于遮掩掉消息矩阵 中的元素 ,其中 表示 所对应的特征矩阵 中的那个元素。
对于DropEdge方法,Dropping在邻接矩阵 中的元素 等价于遮掩掉消息矩阵 中元素 ,其中 表示 所对应的边。
对于DropNode方法,Dropping在特征矩阵X中的元素等价于遮掩掉消息矩阵 中的元素 ,其中 表示 所对应的特征矩阵 中那一行。
那么根据以上的描述,我们发现DropMessage是对消息矩阵进行了最细粒度的屏蔽,这使得它成为最灵活的dropping方法,并且其他方法可以看作是DropMessage的一种特殊形式。
第四小节 DropMessage有效性的理论分析
理论1 图神经网络中无偏的随机dropping将一个额外的正则化项引入到了目标函数中,这使得模型更加鲁棒。
证明:为了简化分析,我们假设下游任务是一个二分类任务,并且我们应用一个简单的图卷积神经网络层 ,其中 是消息矩阵, 是转移矩阵, 表示那些应被每个结点聚合的消息且是规模化之后的形式。最后,我们采用一个sigmoid作为激活函数来生成分类的预测结果 。并使用交叉熵损失
作为目标函数,于是目标函数的公式如下:
当我们使用随机dropping的时候,被扰动的 代替了原来的消息矩阵 。此时目标函数的期望为:
正如上述公式所示,在图上的随机dropping方法引入了一个额外的正则化项,这使得模型预测的结果趋近于0或1,因此会有更加清晰的分类判断。通过减小 的方差,随机dropping方法激励模型提取更重要的高级表示以提升模型的鲁棒性。
第二节 DropMessage的优势第一小节 减小样本方差
所有的随机dropping方法都面临着训练不稳定的问题。现有的工作表明,不稳定是由每个训练轮次的时候引入的随机噪声导致的,这些噪声增加了参数覆盖的难度和训练的不稳定性。一般来说,样本方差被用来衡量稳定程度。而相比于其他方法,DropMessage可以有效减少样本方差。
理论2 在现有的随机dropping方法中以相同概率进行drop的情况下,DropMessage表现出最小的样本方差
证明:随机dropping方法的样本方差可以通过计算消息矩阵的范数 来衡量。在不失一般性的前提下,我们假设原始的消息矩阵 是 ,即每个元素都是1。因此,我们可以通过消息矩阵的1-范数来计算其样本方差。
我们认为消息传递的GNN没有结点sampler和边sampler,这意味着每个有向边都等价于消息矩阵M中的一个行向量。为了简化分析,我们假设图是无向图,每个结点的度都是 。在本例中,消息矩阵的总行数为 。所有的随机dropping方法都可以看作多个独立的伯努利采样。整个过程是符合二项分布的,因此我们可以计算出 的方差。
对于Dropout来说,执行 次的伯努利采样,在特征矩阵中遮掩一个元素会遮掩消息矩阵中的 个元素,方差为
对于DropEdge来说,执行nc次的伯努利采样,在邻接矩阵中遮掩一个元素会遮掩消息矩阵中的 个元素,方差为
对于DropNode来说,执行n次的伯努利采样,在边集合中遮掩一个元素会遮掩消息矩阵中的 个元素,方差为
对于DropMessage来说,执行 次的伯努利采样,在消息矩阵中遮掩一个元素会遮掩消息矩阵中的1个元素,方差为
综上,DropMessage的方差最小。
直觉上,DropMessage独立地决定了在消息矩阵中的元素掩码与否,这恰好是随机dropping消息矩阵的最小伯努利迹。通过减小样本方差,DropMessage减小了不同训练轮次的消息矩阵差异,这稳定了训练并加快了收敛速度。DropMessage具有最小样本方差的原因是它是GNN模型中最细粒度的随机dropping方法。在应用DropMessage时会独立判断每个元素 是否需要屏蔽。
第二小节 保持信息多样性
我们将从信息论的角度比较不同随机dropping方法损失信息多样性的程度。
定义1 信息多样性包含特征多样性和拓扑多样性。我们定义特征多样性为 ,这里 , 指的是对应于来自 的边的行号的切片。信息多样性定义为 ,这里 , 表示信息矩阵, 表示集合中元素的个数。
换而言之,特征多样性被定义为来自不同源结点的保留特征维度的总数;拓扑多样性被定义为传播至少一个维度消息的有向边的总数。根据上述的定义,我们认为只有在随机dropping后特征多样性和拓扑多样性都不减少的方法才具有保持信息多样性的能力。
引理2 Dropout DropEdge DropNode 都不具有保持信息多样性的能力
根据定义1,当我们drop掉特征矩阵X中的一个元素时,所有在消息矩阵中对应的元素都会被遮掩掉并且特征多样性降低1. 当我们drop掉邻接矩阵中的一条边时,对应的在消息矩阵无向图的两行也会被遮掩掉并且拓扑多样性降低2.同理,当drop掉一个结点时特征多样性和拓扑多样性都会降低。
理论3 当drop率小于等于 时,DropMessage可以保持信息多样性。其中是结点的出度, 是特征维度。
证明:DropMessage直接对消息矩阵 进行随机丢弃。为了保持拓扑多样性,我们期望消息矩阵 中每一行至少保留一个元素:
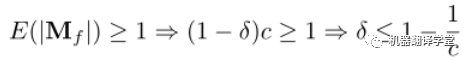
为了保持特征多样性,我们期望对于特征矩阵 中的每个元素,消息矩阵 中至少保留一个其对应的元素:
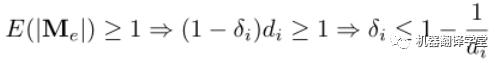
因此,为了满足上述两式以保持信息多样性的drop比例 应满足: 从信息论的角度来看,具有保持信息多样性能力的随机dropping方法比没有这种能力的能保存更多的信息,并在理论分析上其性能也更好。因此,这也解释了为什么DropMessage比现有的其他方法都要好。实际上,我们只为整个图设置了一个drop率参数,没有为每个结点都设置。虽然这样会使DropMessage损失更多信息,但DropMessage仍然比具有相同drop率的其他方法能保留更多信息。
第五章 实验
我们在不同的图神经网络和不同数据集中比较DropMessage和其他方法,我们主要想验证:
DropMessage是否在图神经网络中优于其他drop方法?
DropMessage是否提升了鲁棒性,并让图神经网络的训练更高效?
定义1中所描述的信息多样性在图神经网络中重要吗?
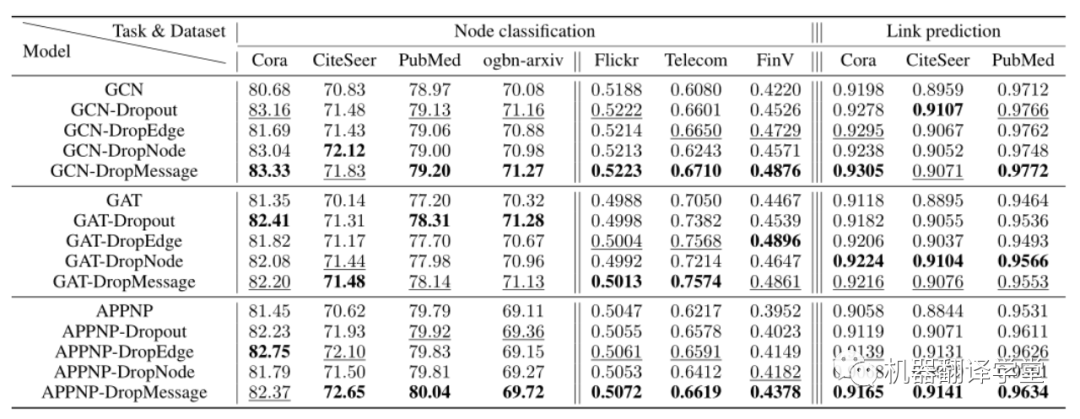
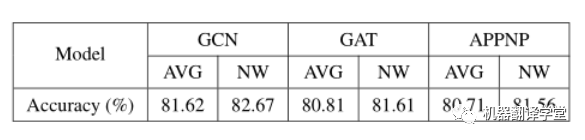
如图所示,我们使用了三种图神经网络(GCN、GAT、APPNP),每种神经网络都被应用了Dropout、DropEdge、DropNode、DropMessage这四种随机dropping方法。
通过上述实验,我们得出以下结论:
DropMessage优于其他随机dropping方法。在结点分类任务下的21个实验设置中DropMessage在15个设置中取得最好的实验结果,在剩下6个设置中取得次好的实验结果;在链路预测任务下的9个实验设置中DropMessage在5个设置中取得最好的实验结果,在剩下4个设置中取得次好的实验结果。
DropMessage 在不同的数据集中的表现十分稳定。而以DropEdge为反例,我们可以看出其在工业数据集(FinV和Telecom)上表现出色,但在其余的公开数据集上表现差劲。我们认为是得益于DropMessage细粒度的drop策略使其有更小的归纳偏置,也因此更适用于大多数的场景。
除了上述实验,我们还做了更多的实验分析:
一、 鲁棒性分析
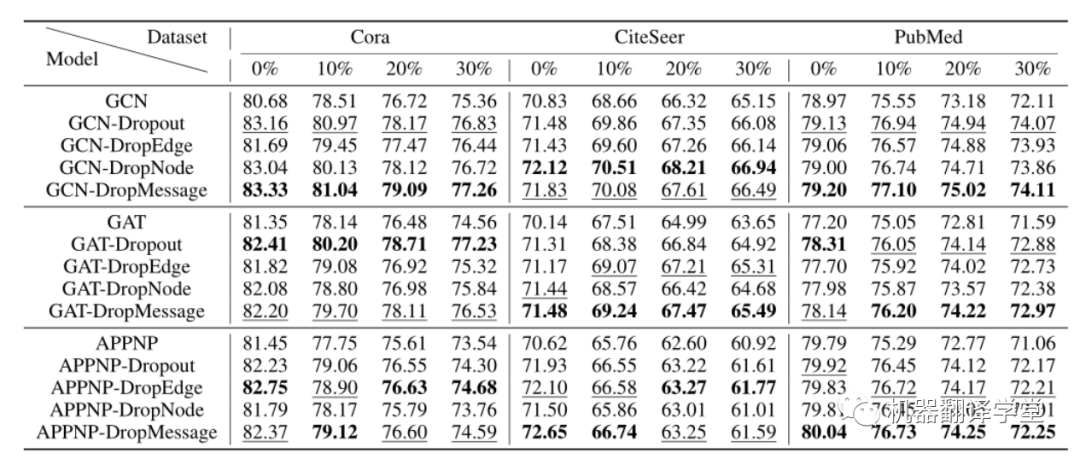
我们通过测量随机dropping方法处理每个扰动图的能力来研究它的鲁棒性。为了保证初始数据相对干净,我们在Cora、CiteSeer和PubMed这三个数据集上进行了实验。我们在这些数据集中随机添加一定比例的边,并进行节点分类任务。我们发现,当扰动率从0%增加到30%时,所有的随机掉落方法都有正向的效果。与没有摄动的情况相比,在30%扰动的情况下,平均提高了37%,这表明随机掉落方法增强了图神经网络模型的鲁棒性。此外,我们所提出的DropMessage显示了它的通用性,并优于其他方法。
二、 过平滑分析
过平滑指的是随着网络深度的增加,结点的表示越来越难以区分。在这一部分中,我们评估了各种随机dropping方法对这个问题的影响,并通过MADGap测量了过度平滑的程度(Chenet al. 2020),其值越小结点的表示越难以区分。
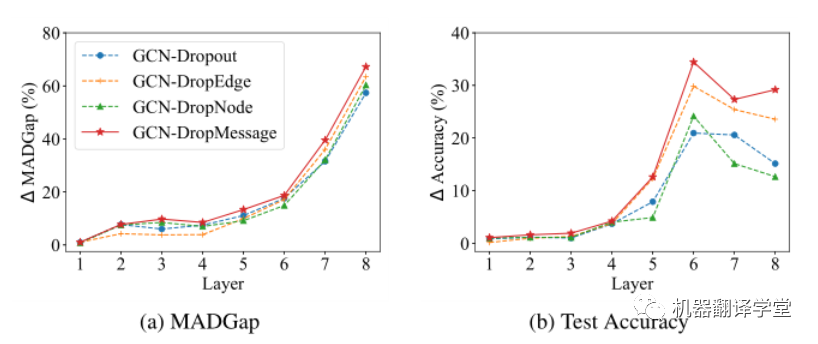
A图表明随着模型深度的增加,随机dropping方法都可以增加MADGap值;B图表明随着模型深度的增加,随机dropping方法都可以提高测试准确率。但是在这些随机dropping方法DropMessage的表现是最佳的。当层数l≥3时,与其他随机掉落方法相比,其MADGap值平均提高3.3%,测试准确率平均提高4.9%。这个结果可以说明DropMessage比其他方法生成了更多不同的消息,这在一定程度上阻止了节点收敛到相同的表示上。
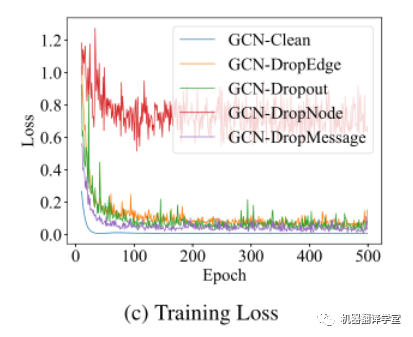
三、 训练过程分析
我们分析了不同随机dropping方法在训练过程中的损失变化。C图是Cora数据集上不同随机dropping方法应用于GCN网络的损失曲线。这个实验结果说明DropMessage有最小的样本方差,因此收敛得更快且具有更稳定的性能表现。
四、 信息多样性分析
我们用Cora数据集来验证信息多样性是否重要,Cora数据集有2708个结点,5429条边,结点的平均度接近于4。根据之前在信息多样性小节的分析,dropping率的上届由结点的度和特征维度计算得来。在Cora数据集中特征维度为1433,它比结点的度大得多,因此上届仅由度来决定。我们用两个实验设置来验证信息多样性。第一个是结点粒度实验,它对每个结点应用其dropping率上届大小的dropping率 。第二个是平均粒度实验,所有结点的dropping率都是 。根据实验,我们发现结点粒度的效果好于平均粒度,这也就验证了信息多样性的重要性。
第六章 结论
本文,我们提出DropMessage,一种更泛化的应用于图神经网络的随机dropping方法。首先,我们统一了随机dropping方法并分析了它们的性能。其次,我们从理论上说明了DropMessage在稳定训练过程和保持信息多样性方面的优势。由于其对消息矩阵做细粒度的drop操作,DropMessage在大多数情况下显示出更大的可应用性。最后,通过在五个公共数据集和两个工业数据集上进行的多任务实验,我们证明了所提方法的有效性和泛化性。
审核编辑 :李倩
-
神经网络教程(李亚非)2012-03-20 0
-
求助基于labview的神经网络pid控制2016-09-23 0
-
【PYNQ-Z2试用体验】神经网络基础知识2019-03-03 0
-
卷积神经网络如何使用2019-07-17 0
-
【案例分享】基于BP算法的前馈神经网络2019-07-21 0
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 0
-
人工神经网络实现方法有哪些?2019-08-01 0
-
如何构建神经网络?2021-07-12 0
-
卷积神经网络一维卷积的处理过程2021-12-23 0
-
神经网络移植到STM32的方法2022-01-11 0
-
卷积神经网络模型发展及应用2022-08-02 0
-
优化神经网络训练方法有哪些?2022-09-06 0
-
一种基于高效采样算法的时序图神经网络系统介绍2022-09-28 0
-
基于过拟合神经网络的混沌伪随机序列2009-12-22 625
-
一种随机的人工神经网络学习方法2017-12-05 470
全部0条评论

快来发表一下你的评论吧 !
