

 人工智能中SSD目标检测算法
人工智能中SSD目标检测算法
描述
SSD算法是在YOLO的基础上改进的单阶段方法,他给予一个前向传播的神经网络,最主要的优点是能在兼顾速度的同时确保高精度,而且由于采用了END-TO-END的训练方法,及时处理的分辨率比较低的照片,分类结果也很准确。
SSD 网络结构分为4个部分:基础网络+附加特征层+预测 +非极大值抑制
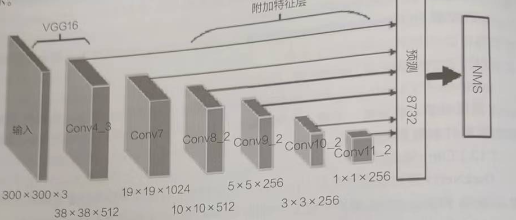
其中,基础网络是VGG-16的前4层网络,主要选取其中的Conv4_3 作为第一个特征层用于目标检测,并将VGG16中的FC7改成了卷积层Conv7。
附加特征层是在 VGG-16基础网络上添加的特征图逐渐变小的特征提取层,分别为Conv8_2、Conv9_2、Conv10 2、Conv11 2层。它们和VGG中的Conv4 3、Conv7共同组成了6层的金字塔网络。金字塔网络是 SSD的设计核心,能通过不同尺度的特征图来预测目标分类与位置,进而提高检测精度。对于每一层特征图,SSD 网络会对每个像素点预测多个边界框,(假设每个像素点预测4个边界框),然后使用不同尺寸边界框的特征进行预测,这样模拟了类似人眼从远到近观察事物的特点,较大尺寸的特征图适合于对较大物体的预测,而较小尺寸的特征图适合于对较小物体的预测。
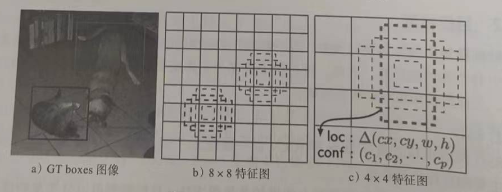
预测层(detection layer)需要对边界框中目标的类别进行预测,同时还需要对边界框的实际位置进行预测。预测层分成 cls 分支和 1oc 分支,每个分支中包含6个(因为有6个特征层)卷积层 conv,conv 的输出尺寸和输人尺寸相同。cls 分支预测每个边界框所有分类的得分;loc 分支预测4个对于边界框的位置偏移量。以SSD300 网络为例,最终可以得到8732个边界框的预测结果。
非极大值抑制(Non-Maximum Suppression,NMS)将根据设置的置信度阙值对预测层输出的预测结果进行排序和筛选,删除不符合要求的边界框,保留与真实结果匹配度较高的预测结果。
上面四层完成了 SSD 网络的整个检测流程。在训练过程中SSD 网络使用多框损失函数(MultiBoxLoss)优化网络。多框损失函数包括类别损失和位置损失两个部分。
下式中、入是通过NMS 匹配到真实结果的边界框数量;Leonr(x,c)为类别损失,是典型的softmax损失;L(,g)为位置损失,是采用Smooth L1的回归损失;a参数用于调整类别损失和位置损失之间的比例,默认 a=1。
L(x,c,l,g)=一(Lonr(x,c)+aLoc(x,l,g))
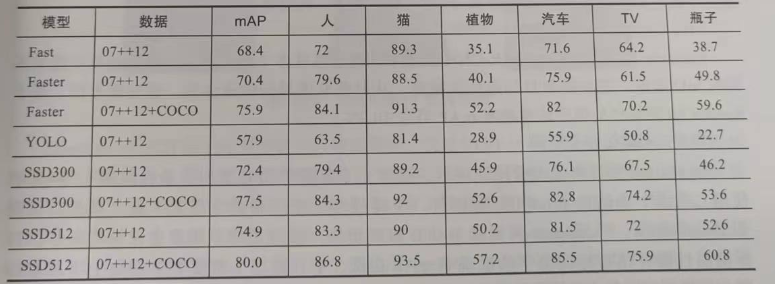
此外,SSD网络的训练过程中还使用了数据加强、匹配策略(matching strategy)、难分样本挖掘(hardnegative mining)等技术提高准确率。最终SSD网络在性能上取得了展示了SSD网络在PASCALVOC2012数据集上同其他模型的对比数据。
-
人工智能就业前景2018-03-29 0
-
人工智能技术及算法设计指南2019-02-12 0
-
人工智能:超越炒作2019-05-29 0
-
安防业再现人工智能风波之真假AI人形检测2019-07-31 0
-
PowerPC小目标检测算法怎么实现?2019-08-09 0
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 0
-
基于YOLOX目标检测算法的改进2023-03-06 0
-
改进的ViBe运动目标检测算法_刘春2017-03-19 1152
-
基于SSD网络模型的多目标检测算法2018-03-02 956
-
基于通道注意力机制的SSD目标检测算法2021-03-25 719
-
基于深度学习的目标检测算法2021-04-30 10130
-
一种改进的单激发探测器小目标检测算法2021-05-27 628
-
基于多尺度融合SSD的小目标检测算法综述2021-05-27 699
-
基于Grad-CAM与KL损失的SSD目标检测算法2022-01-21 796
-
无Anchor的目标检测算法边框回归策略2023-07-17 608
全部0条评论

快来发表一下你的评论吧 !
