

GPU平台生态,英伟达CUDA和AMD ROCm对比分析
描述
成熟且完善的平台生态是 GPU 厂商的护城河。相较于持续迭代的微架构带来的技术壁垒硬实力,成熟的软件生态形成的强大用户粘性将在长时间内塑造 GPU厂商的软实力。以英伟达 CUDA 为例的软硬件设计架构提供了硬件的直接访问接口,不必依赖图形 API 映射,降低 GPGPU 开发者编译难度,以此实现高粘性的开发者生态。目前主流的开发平台还包括 AMD ROCm 以及 OpenCL。
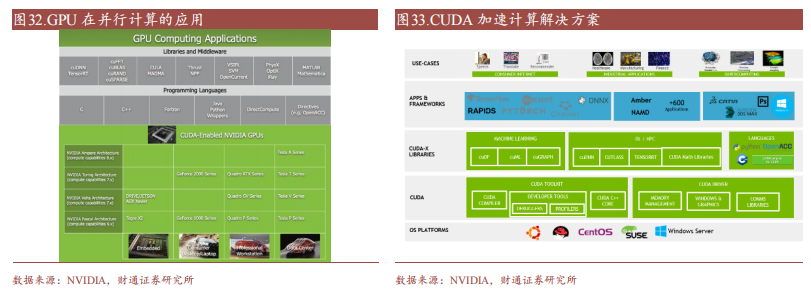
CUDA(Compute Unified Device Architectecture),是 NVIDIA 于 2006 年推出的通用并行计算架构,包含 CUDA 指令集架构(ISA)和 GPU 内部的并行计算引擎。该架构允许开发者使用高级编程语言(例如 C 语言)利用 GPU 硬件的并行计算能力并对计算任务进行分配和管理,CUDA 提供了一种比 CPU 更有效的解决大规模数据计算问题的方案,在深度学习训练和推理领域被广泛使用。
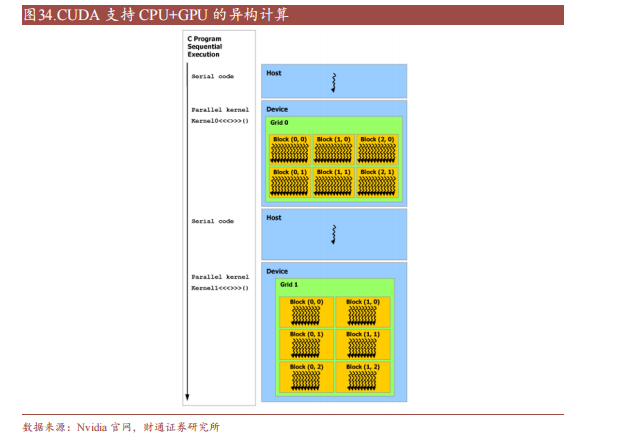
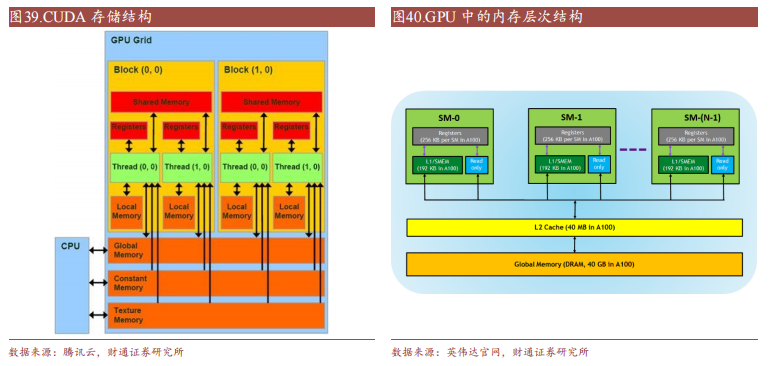
CUDA 除了是并行计算架构外,还是 CPU 和 GPU 协调工作的通用语言。在CUDA 编程模型中,主要有 Host(主机)和 Device(设备)两个概念,Host 包含 CPU 和主机内存,Device 包含 GPU 和显存,两者之间通过 PCI Express 总线进行数据传输。在具体的 CUDA 实现中,程序通常划分为两部分,在主机上运行的 Host 代码和在设备上运行的 Device 代码。Host 代码负责程序整体的流程控制和数据交换,而 Device 代码则负责执行具体的计算任务。
一个完整的 CUDA程序是由一系列的设备端函数并行部分和主机端的串行处理部分共同组成的,主机和设备通过这种方式可以高效地协同工作,实现 GPU 的加速计算。
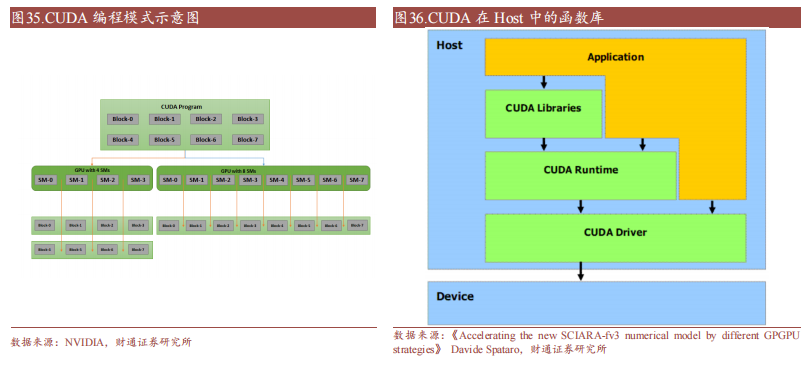
CUDA 在 Host 运行的函数库包括了开发库(Libraries)、运行时(Runtime)和驱动(Driver)三大部分。其中,Libraries 提供了一些常见的数学和科学计算任务运算库,Runtime API 提供了便捷的应用开发接口和运行期组件,开发者可以通过调用 API 自动管理 GPU 资源,而 Driver API 提供了一系列 C 函数库,能更底层、更高效地控制 GPU 资源,但相应的开发者需要手动管理模块编译等复杂任务。
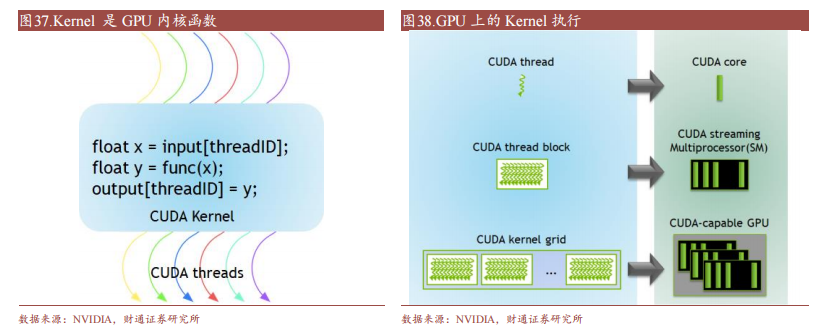
CUDA 在 Device 上执行的函数为内核函数(Kernel)通常用于并行计算和数据处理。在 Kernel 中,并行部分由 K 个不同的 CUDA 线程并行执行 K 次,而有别于普通的 C/C++函数只有 1 次。每一个 CUDA 内核都以一个声明指定器开始,程序员通过使用内置变量__global__为每个线程提供一个唯一的全局 ID。一组线程被称为 CUDA 块(block)。CUDA 块被分组为一个网格(grid),一个内核以线程块的网格形式执行。每个 CUDA 块由一个流式多处理器(SM)执行,不能迁移到 GPU 中的其他 SM,一个 SM 可以运行多个并发的 CUDA 块,取决于CUDA 块所需的资源,每个内核在一个设备上执行,CUDA 支持在一个设备上同时运行多个内核。
丰富而成熟的软件生态是 CUDA 被广泛使用的关键原因。
(1)编程语言:CUDA 从最初的 1.0 版本仅支持 C 语言编程,到现在的 CUDA 12.0 支持 C、C++、Fortran、Python 等多种编程语言。此外,NVIDIA 还支持了如 PyCUDA、ltimesh Hybridizer、OpenACC 等众多第三方工具链,不断提升开发者的使用体验。
(2)库:NVIDIA 在 CUDA 平台上提供了名为 CUDA-X 的集合层,开发人员可以通过 CUDA-X 快速部署如 cuBLA、NPP、NCCL、cuDNN、TensorRT、OpenCV 等多领域常用库。
(3)其他:NVIDIA 还为 CUDA 开发人员提供了容器部署流程简化以及集群环境扩展应用程序的工具,让应用程序更易加速,使得CUDA 技术能够适用于更广泛的领域。
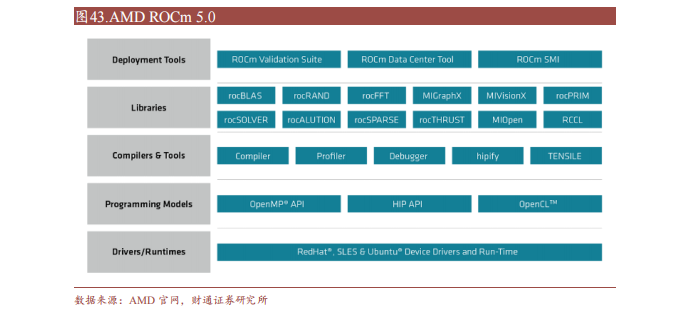
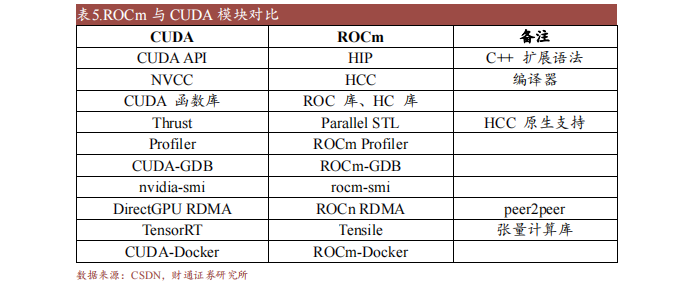
ROCm (Radeon Open Compute Platform )是 AMD 基于开源项目的 GPU计算生态系统,类似于 NVIDIA 的 CUDA。ROCm 支持多种编程语言、编译器、库和工具,以加速科学计算、人工智能和机器学习等领域的应用。ROCm还支持多种加速器厂商和架构,提供了开放的可移植性和互操作性。
ROCm 支持HIP(类 CUDA)和 OpenCL 两种 GPU 编程模型,可实现 CUDA 到 ROCm 的迁移。最新的 ROCm 5.0 支持 AMD Infinity Hub 上的人工智能框架容器,包括TensorFlow 1.x、PyTorch 1.8、MXNet 等,同时改进了 ROCm 库和工具的性能和稳定性,包括 MIOpen、MIVisionX、rocBLAS、rocFFT、rocRAND 等。
OpenCL(Open Compute Language),是面向异构系统通用并行编程、可以在多个平台和设备上运行的开放标准。OpenCL 支持多种编程语言和环境,并提供丰富的工具来帮助开发和调试,可以同时利用 CPU、GPU、DSP 等不同类型的加速器来执行任务,并支持数据传输和同步。
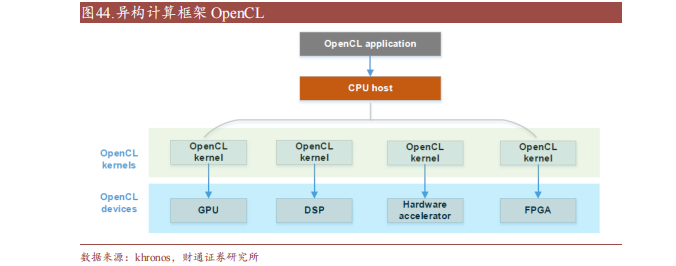
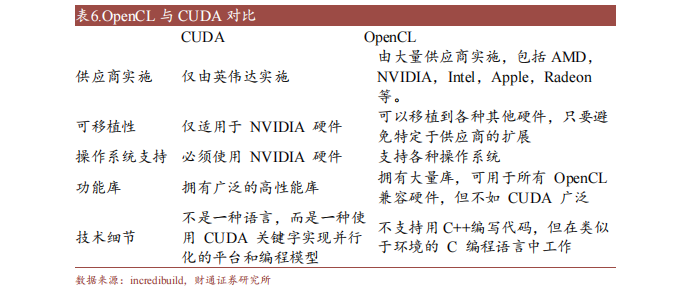
此外,OpenCL 支持细粒度和粗粒度并行编程模型,可根据应用需求选择合适模型提高性能和效率。而 OpenCL可移植性有限,不同平台和设备的功能支持和性能表现存在一定差异,与 CUDA相比缺少广泛的社区支持和成熟的生态圈。
审核编辑 :李倩
-
233.国产GPU和国外竞争对手的差距在哪里?#国产gpu#英伟达小凡 2022-10-04
-
267.英伟达对中俄出口高端GPU芯片受新限制小凡 2022-10-04
-
AI开发者福音!阿里云推出国内首个基于英伟达NGC的GPU优化容器2018-04-04 0
-
英伟达发布新一代 GPU 架构图灵和 GPU 系列 Quadro RTX2018-08-15 0
-
英伟达GPU惨遭专业矿机碾压,黄仁勋宣布砍掉加密货币业务!2018-08-24 0
-
AMD迎头猛追Intel 全球首发7nm GPU很威风!2018-11-20 0
-
自动驾驶(七十五)---------几种硬件平台对比 精选资料分享2021-07-27 0
-
恩智浦S32V/英伟达DRIVE PX2/TI的TDA4/寒武纪1M/高通SA8155对比分析哪个好?2021-09-30 0
-
英伟达DPU的过“芯”之处2022-03-29 0
-
英伟达黄仁勋:GPU加速计算是发展方向2019-12-18 2420
-
国产GPU绕不开的CUDA生态2022-11-29 2766
-
GPU平台生态:英伟达CUDA和AMD ROCm对比分析2023-06-06 1287
-
AMD将于今年秋季在部分RDNA 3 GPU上添加ROCm的支持2023-07-25 508
-
AMD 发布新的AMD ROCm 5.6开放软件平台2023-07-25 684
-
GPU技术、生态及算力分析2024-01-14 601
全部0条评论

快来发表一下你的评论吧 !
