

TECS资源池上报存储设备离线的问题处理
描述
某资源池在运行过程中出现存储设备离线告警,通过底层cinder service-list命令查看,确认存储state为down状态。
登录控制节点虚拟机,执行source keystonerc_admin命令进入OpenStack环境,执行cinder service-list命令查看存储状态,如下图所示。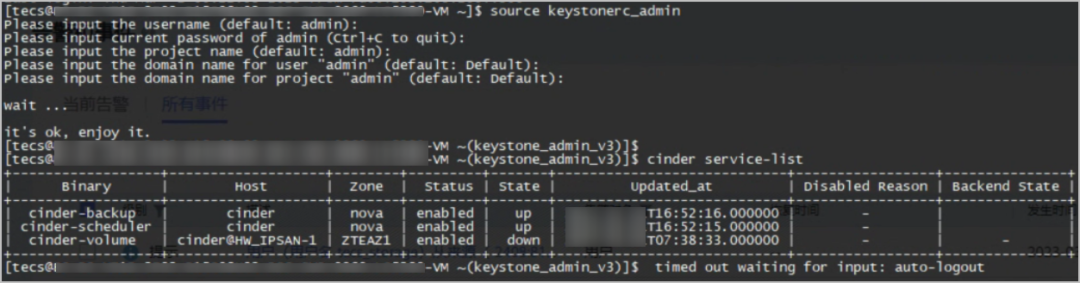
当云平台通过存储管理面无法获取存储设备上报的状态,则上报告警。
当云平台能够正常通过存储管理面获取存储设备上报的状态,则恢复告警。
存储失去控制,磁阵不可用,存在如下3种情况:
存储掉电。
网络不通。
对接问题。
问题分析过程如下:
1.检查存储设备当前状态是否正常。
通过登录存储设备管理页面,检查存储设备告警信息,未发现异常内容。
2.检查存储网和管理网的连通性。
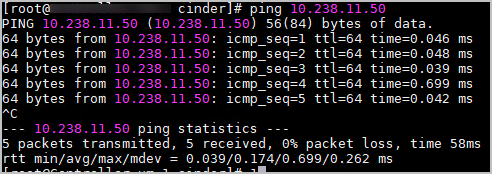
登录控制节点虚拟机,通过Ping操作确认磁阵的管理网和存储网的连通性,网络正常,如下图所示。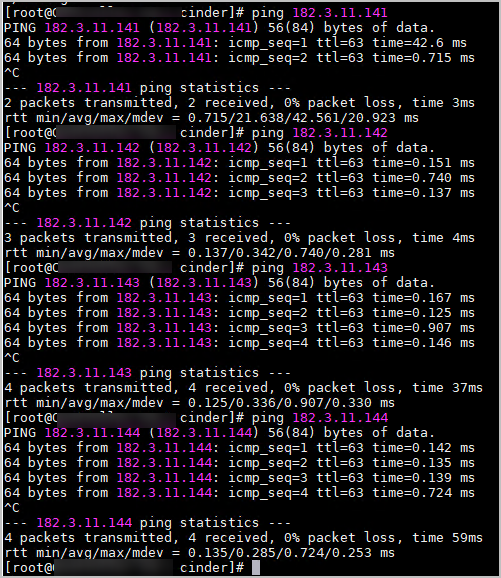
3.检查控制节点虚拟机/var/log/cinder/volume.log日志,分析详细原因。
通过volume.log日志检查,原因为访问的IP地址被锁定,如下图所示。需要登录磁阵做详细的安全日志检查。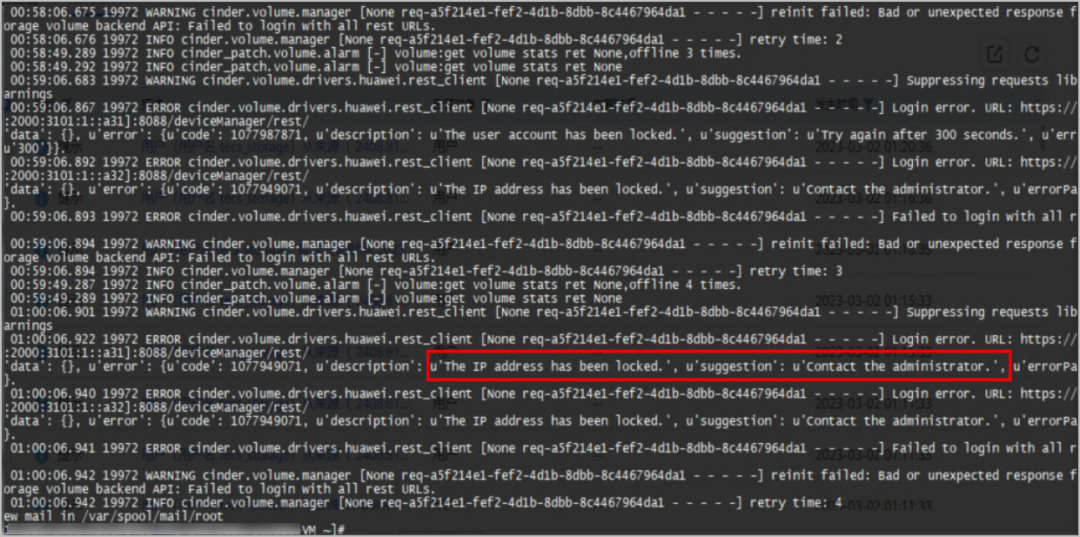
4.登录磁阵页面,检查存储侧记录的所有事件,记录为连续多次登录失败,IP和账号被锁定5分钟,循环登录失败并持续锁定。
5.通过磁阵管理页面解锁IP和账号锁定。
6.观察5分钟,IP和账号再次被锁定,可能原因是密码错误导致多次登录失败,继而被锁定。
1.登录控制节点虚拟机,检查/etc/cinder/cinder_huawei_conf_file_HW_IPSAN-1. xml配置,获取用户名和密码的密文。 2. 在控制节点虚拟机下,执行如下命令解读密文:
a.执行echo 'dGVjc19zdG9yYWdl'| base64 -d命令,得到对接账号tecs_storage。
b.执行echo 'Z0s5WUltc3k5SmRJQ1JWWmpmSHdfcW5kU2JaQnZCbG0waEZlUUJUSXZFQ2c2NGNlNTAxZGIyMDAwODllY2Q0YzgyOA=='| base64 -dse64 -d命令,得到密文为gK9YImsy9JdICRVZjfHw_qndSbZBvBlm0hFeQBTIvECg64ce501db2308a21fee00089ecd4c828,需要再次解密。
c.执行python /usr/lib/python2.7/site-packages/oslo_config/aes.py decrypt gK9YImsy9JdICRVZjfHw_qndSbZBvBlm0hFeQBTIvECg64ce501db2308a21fee00089ecd4c828命令,得到对接密码为kEYSTONE_2020。
3.登录Daisy界面,在云配置→配置→存储管理→存储设备对接界面,更新磁阵的密码。
4.登录控制节点虚拟机在cinder-volume的服务节点,执行以下命令,重启服务。
systemctl restart openstack-cinder-volume.service
5.执行source keystonerc_admin命令,进入OpenStack环境。
6.执行命令cinder service-list命令,查看存储状态。
7.总结及注意事项:
a.磁阵和平台对接建议使用非admin用户和密码,避免定期修改密码,影响对接。
b.修改磁阵的密码时需要关注TECS侧的影响。
c.由于输入账号的密码是不可见的,需要确认输入密码的正确性,避免大小写,特殊符号等问题。
审核编辑:刘清
-
网络存储设备相关介绍2012-11-12 0
-
红手指云手机【部落冲突coc辅助离线托管刷资源】玩爆COC!2017-03-30 0
-
请问如何删除路由器内存储的离线设备的信息?2018-08-17 0
-
为什么32个CAN设备同时每隔1秒进行上报会出现有些上报不成功的现象呢2023-02-10 0
-
在RISCV的生态里有没有可以离线分析MCU运行异常的工具?2023-08-12 0
-
离线语音识别及控制是怎样的技术?2023-11-24 0
-
Delphi教程会之远程数据库的离线处理2016-03-31 508
-
探析实现CAN总线数据存储回放的设备2019-02-20 3509
-
存储虚拟化的存储资源架构解析2020-07-31 2786
-
【解决方案】设备如何上报数据到ZWS云平台?2023-03-10 308
-
TECS资源池上报网络流程异常告警的问题处理2023-06-07 561
-
TECS资源池SSH控制节点虚机提示connection refused的问题处理2023-06-07 483
-
TECS资源池上报BFD会话DOWN和网络流量异常告警的问题处理2023-06-07 853
-
ZWS云平台应用(4)-设备数据上报2024-04-12 311
全部0条评论

快来发表一下你的评论吧 !
