

CPU与GPU密集型应用程序
人工智能
描述
CPU 与 GPU 密集型应用程序
计算在我们的日常生活和整个社会中变得越来越重要。虽然晶体管数量每两年翻一番的趋势(称为摩尔定律)可能即将结束,但计算继续发挥着至关重要的作用。但我们指的不是运行占用资源的后台应用程序或玩视觉最密集的游戏。
我们正在谈论计算在世代发现中的生产应用。计算已成为许多职业中必不可少的工具,具有计算生物学、人工智能和机器学习等专业子领域,以及金融、天气等行业的复杂计算算法。其中一些领域是在过去十年中出现的。
计算硬件的进步与计算应用程序的实际影响之间存在相关性。对更强大的计算的需求推动了对更好硬件的研发,这反过来又使开发更强大的应用程序变得更加容易。值得注意的是,游戏行业在开发图形处理单元(GPU)等专用硬件方面发挥了重要作用,它已成为机器学习等领域当代进步的重要组成部分。
在数据科学、机器学习、建模和其他生产性任务中使用 GPU 进行一般处理的作用越来越大,这反过来又促使改进硬件迎合这些应用程序,并提供更好的软件支持。NVIDIA 开发的张量核心极大地改进了训练神经网络和在现实世界、实时应用程序以及各个领域的其他机器学习任务中执行 AI 推理中的矩阵乘法。
考虑到所有这些,它应该很简单:购买尽可能多的 GPU。但是,要利用GPU的计算性能,我们必须考虑其他因素。
最先进的GPU不仅要花费数千美元,而且对于某些应用程序,它们可能无法很好地扩展。应用程序的并行性、软件支持和规模(以及预算)都会影响 CPU 和 GPU 规格的权重,以满足用户的计算需求。
并行化基础知识
CPU擅长通用计算,可以计算我们编程的任何内容。高性能CPU可以快速给我们一个答案,这个特征就是所谓的延迟:从原因到结果所需的时间。
另一方面,GPU 通常被简洁地描述为以更低的延迟换取更高的吞吐量:衡量随着时间的推移将“原因”(即数据)转化为结果的数量。
虽然时钟速度不是一切,但它们确实让我们了解指令通过设备的速度。请注意,现代 CPU 的时钟速度大约是最新和最伟大的 GPU 的两倍。
虽然 GPU 中的内核单独速度不如 CPU 中的内核快得多,而且更专业,但它们的数量要多得多(NVIDIA 高端消费类 RTX 16 中有 384,4090 个 CUDA 内核),因此对于可以并行化的操作来说,吞吐量很高。
现代CPU也接受了多核计算(尽管比它们的GPU表亲要极端得多)。这在一定程度上是出于达到芯片制造中缩放现象的S曲线的平坦部分而采取的举措。简而言之,现代 CPU 内核如果不遇到严重的散热问题,就无法获得更快的速度。
对于应用程序是否优先考虑 GPU 或 CPU,基本经验法则是 GPU 更适合并行工作。但是,如前所述,CPU 具有较小程度的并行性,并且并非工作负载中的所有并行化类型都是平等的。
从某种意义上说,矩阵运算和进化算法都是令人尴尬的平行的;虽然矩阵操作非常适合 GPU 加速,但后者最适合在多个 CPU 内核上执行。最终,许多实际应用程序的部件严重依赖 CPU 和 GPU 密集型。巧妙地平衡和优化两者可以在速度和计算可访问性方面提供额外的收益,正如我们将在现已解散的Uber AI实验室开发的深度神经进化策略的例子中看到的那样。
并行化的类型
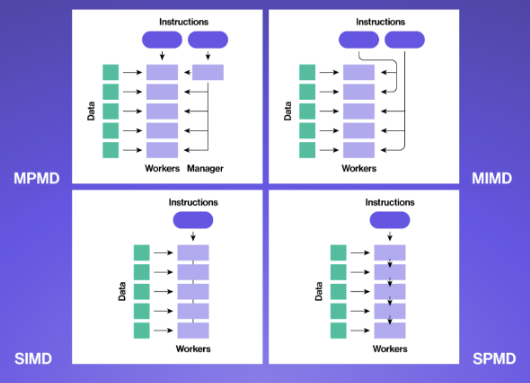
通常,当任务可以分解为不依赖于彼此输出的独立组件时,可以更容易地并行。根据问题的内在特征,并行化有几种不同的风格。我们可以将弗林的计算机体系结构分类法用作脚手架。
多程序多数据
在 MPMD 中,多个程序在不同的数据集上并行运行。每个程序都独立于其他程序运行,它们可以在群集中的不同处理器或节点上运行。这种类型的并行化通常用于高性能计算应用程序,其中需要同时执行多个程序才能实现所需的性能。
多指令多数据
MIMD 类似,但可以通过缺少中央控制过程来区分。多个处理器同时在不同的数据集上执行不同的指令。每个处理器都是独立的,可以执行自己的程序或指令序列。这种类型的并行化通常用于分布式计算,其中不同的处理器处理问题的不同部分。
单指令多数据
在 SIMD 中,多个处理器同时对不同的数据集执行相同的指令。这种类型的并行化通常用于需要并行处理大量数据的应用程序,例如图形处理和科学计算。例如,在图像处理中,可以使用 SIMD 将相同的操作应用于图像中的所有像素。
单程序多个数据
在SPMD中,多个处理器同时在不同的数据集上执行相同的程序。每个处理器可以独立地对自己的数据进行操作,但它们都执行相同的代码。这种类型的并行化通常用于集群计算,其中单个程序在集群中的多个节点上执行,每个节点处理输入数据的不同部分。它类似于 MIMD,但所有处理器都执行相同的程序。
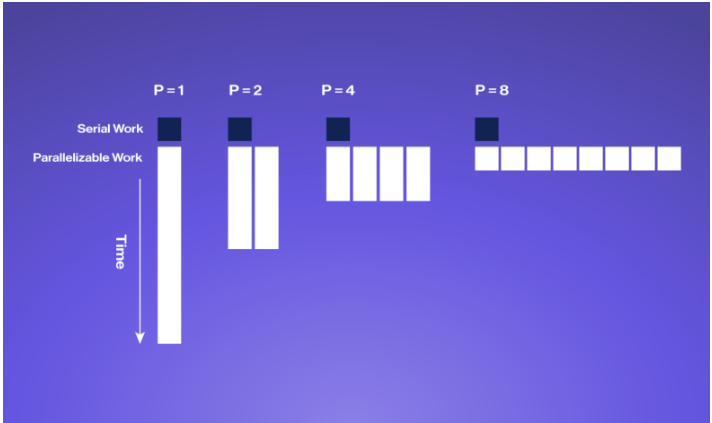
阿姆达尔定律:并行化的极限
并行化可以为密集型算法带来显著的加速和节能,但算法中无法并行化的部分(称为阿姆达尔定律)可以获得多少是有限的。
阿姆达尔定律是一个公式,描述了当程序在多个处理器上并行运行时可以实现的最大加速比。它考虑了可以并行化的程序百分比和必须按顺序运行的百分比。
该公式指出,可以实现的最大加速比受程序的顺序部分的限制。换句话说,如果一个程序有 80% 的代码可以并行运行,20% 的代码必须按顺序运行,那么即使使用无限数量的处理器,也可以实现的最大加速比为 5 倍。这是因为无论使用多少处理器,20% 的顺序部分将始终花费相同的时间来执行。
为了实现可能的最大加速,重要的是要确定程序的哪些部分可以并行化并相应地优化它们。此外,所使用的硬件应设计为最小化程序顺序部分的影响。
总体而言,阿姆达尔定律是使用并行计算时需要理解的重要概念,因为它有助于为可以实现的潜在加速设定切合实际的期望,并指导优化工作。
何时使用 CPU 与 GPU 的示例:最佳用例
在理想情况下,在为给定用例规划计算硬件时是否强调 GPU 或 CPU 的清单非常简短:“是否有适用于此用例的高效 GPU 实现?
某些 GPU 实现比其他实现更好,在某些情况下,强制具有大量不可并行化组件的算法在 GPU 上运行弊大于利,尤其是在 GPU VRAM 内存和系统 RAM 之间移动数据存在大量开销的情况下。
编译源代码:专注于CPU(和内存)
编译源代码是 GPU 通常不会发挥作用的一个领域。在规划主要用于构建大型代码库的系统时,CPU 性能更为重要,拥有足够的内存 (RAM) 尤为重要。
在构建具有大量专用于读取/写入磁盘的开销的大型代码库时,不要忘记投资像 NVMe 存储这样的快速存储技术。
最好的英特尔CPU通常具有比AMD系列略好于单线程性能,但这有时只等同于更好的构建时间。查看各种语言的 CPU 编译基准测试 openbenchmarking.org。请记住,更多内核并不总是意味着更多更好;以最佳预算价位找到最佳 CPU,不仅可以节省时间和金钱,还可以降低能耗和 TCO。
深度学习:GPU 主导
现代机器学习的特点是深度学习,具有多层非线性转换的模型,大多以点积和卷积等矩阵运算的形式实现。这些操作本质上是可矢量化的:我们可以将许多此类操作批处理在一起,并在一次正向传递中执行它们。换句话说,现代神经网络的构建块在很大程度上是可并行化的。
GPU 当之无愧地成为深度学习管道(尤其是训练)的黄金标准和常见做法。NVIDIA GPU 拥有超过十年的研发经验,强调深度学习。GPU 硬件对神经网络的适用性引发了良性循环的缩影,因为它激励了对改进线性代数基元、专门的低精度数据类型和张量核等功能开发更好的支持。
训练全尺寸 AI 模型需要分布式计算、大量财务和超级计算机访问方面的专业知识。微调小型或中型LLM可以使用具有大量板载VRAM的高端消费类或专业GPU。
进化算法:多核 CPU 重点
虽然深度学习和反向传播可能是当今最著名的机器学习类型,但仍存在进化算法更有效的情况。
进化算法涉及计算许多不同变体的“适应性”,这些变体被称为个体。对于这类问题,进化算法已被证明与传统的强化学习方法一样好。
计算群体中每个个体的适应度通常可以并行完成,而无需等待其他个体完成。SPMD 和 MPMD 算法不需要管理器或中央控制器,通常用于这些类型的计算。像AMD的EPYC或Ryzen Threadripper这样的CPU,特别适合运行这些类型的算法,并且可以使用消息传递接口(MPI)标准相互通信。
寻找平衡:优化 GPU 和 CPU 的使用以实现深度神经进化
虽然深度神经网络非常适合在强大的GPU上进行矢量处理,而进化算法也有利于在多核CPU上并行实现,但有时我们两者都需要。优化 GPU 和 CPU 资源的使用对于提高深度神经进化的性能至关重要,深度神经进化涉及用于优化深度神经网络的进化算法。
我们在 CPU 上同时利用进化算法的 SPMD/MPMD 范式,在 GPU 上同时利用神经网络的 SIMD 数学原语。利用 CPU 和 GPU 功能可确保实现这些最佳性能和效率。
除了优化 GPU 和 CPU 的使用外,选择优化算法的正确超参数也很重要。群体大小、突变率和交叉率等超参数会显著影响优化过程的性能。通常需要仔细调整才能获得最佳结果。
哪些应用程序是 GPU 密集型应用程序,哪些应用程序是 CPU 密集型应用程序?
除了 GPU 对神经网络的适用性之外,HPC 中许多感兴趣的问题都基于物理学,例如计算流体动力学或粒子模拟。物理学具有局部性的便利性,即物体仅受其附近其他物体的影响。
这样做的计算结果是,物理相互作用的许多方面都可以并行建模,例如在更新粒子状态之前计算粒子云上的力。这意味着许多基于物理的应用程序的大部分都可以在GPU上有效实现。
对于基于物理的问题,GPU 实现的存在通常是确定给定应用程序是否可以从强调 GPU 硬件的系统中受益所需的唯一考虑因素。大多数主要的分子动力学软件包现在都具有良好的GPU支持,包括AMBER,GROMACS等。
正如AlphaFold和其他深度学习突破所表明的那样,神经网络可以很容易地补充计算生物学。
另一方面,CPU 密集型应用程序源于数据库管理和虚拟机。CPU 对于代码编译非常重要,例如运行我们的操作系统,这是一个大型代码网络,使我们的系统能够运行,更不用说指示哪些任务将转到我们的 GPU。CPU 充当计算机的委派人和工头。
虽然并非所有 GPU 实现都是平等的,但许多 HPC 应用程序现在都受益于并行化。有了良好的GPU支持,在大多数领域加速算法的重要部分在很大程度上要归功于专用于在屏幕上显示数百万像素的硬件。随着深度学习的进步,GPU 通用计算的进步进一步加速。
随着其他领域强大的GPU增强模拟成为普遍做法,我们可以期待硬件专业化和算法改进,即使面对摩尔定律和Dennard缩放的崩溃。随着更先进的指令集和高效架构的开发,计算的转变将是CPU和GPU之间的结合。
审核编辑:郭婷
-
鸿蒙原生应用开发-ArkTS语言基础类库多线程CPU密集型任务TaskPool2024-03-19 0
-
鸿蒙原生应用开发-ArkTS语言基础类库多线程I/O密集型任务开发2024-03-21 0
-
什么是DWDM密集型光波复用?DWDM产品有哪些?2018-03-30 0
-
计算密集型的程序简析2021-09-07 0
-
什么样的程序适合在GPU上运行呢2021-09-07 0
-
ARM Mali-T600系列GPU OpenCL开发人员指南2023-08-24 0
-
HarmonyOS CPU与I/O密集型任务开发指导2023-09-26 0
-
软件密集型装备故障的静态检测2009-06-21 350
-
新型处理器的数据密集型计算2018-01-10 757
-
数据中心依靠服务器为其计算密集型架构提供支持2020-04-28 2484
-
FPGA执行计算密集型任务性能表现及优势有哪些2022-11-10 728
-
GPU工作原理 如何提高集成GPU的工作频率2023-03-19 1146
-
为什么需要专门出现GPU处理图形工作?2023-07-08 429
-
鸿蒙OS开发实例:【ArkTS类库多线程CPU密集型任务TaskPool】2024-04-01 328
全部0条评论

快来发表一下你的评论吧 !
