

XGBoost超参数调优指南
电子说
描述
对于XGBoost来说,默认的超参数是可以正常运行的,但是如果你想获得最佳的效果,那么就需要自行调整一些超参数来匹配你的数据,以下参数对于XGBoost非常重要:
etanum_boost_roundmax_depthsubsamplecolsample_bytreegammamin_child_weightlambdaalpha
XGBoost的API有2种调用方法,一种是我们常见的原生API,一种是兼容Scikit-learn API的API,Scikit-learn API与Sklearn生态系统无缝集成。我们这里只关注原生API(也就是我们最常见的),但是这里提供一个列表,这样可以帮助你对比2个API参数,万一以后用到了呢:
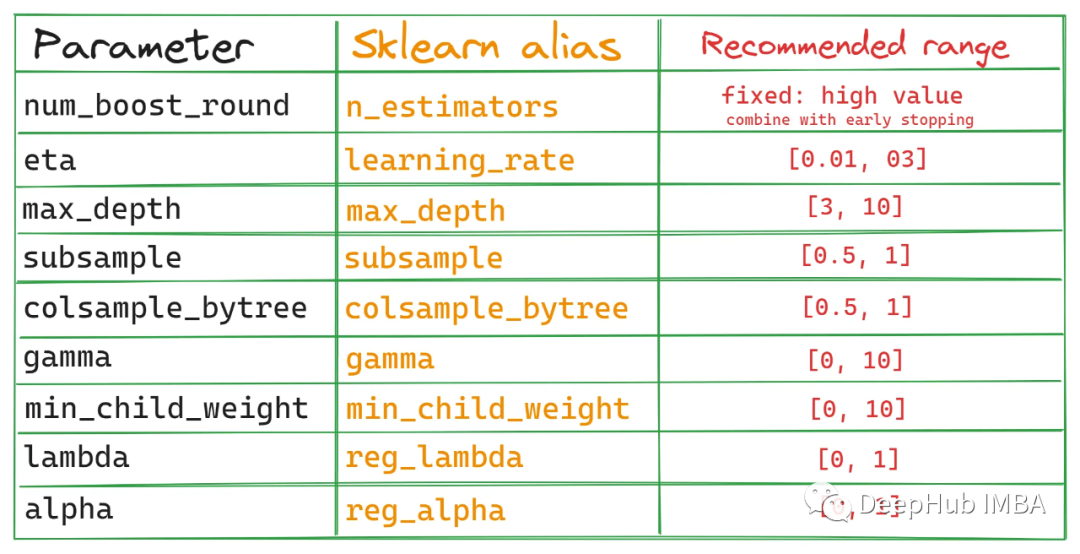
如果想使用Optuna以外的超参数调优工具,可以参考该表。下图是这些参数对之间的相互作用:
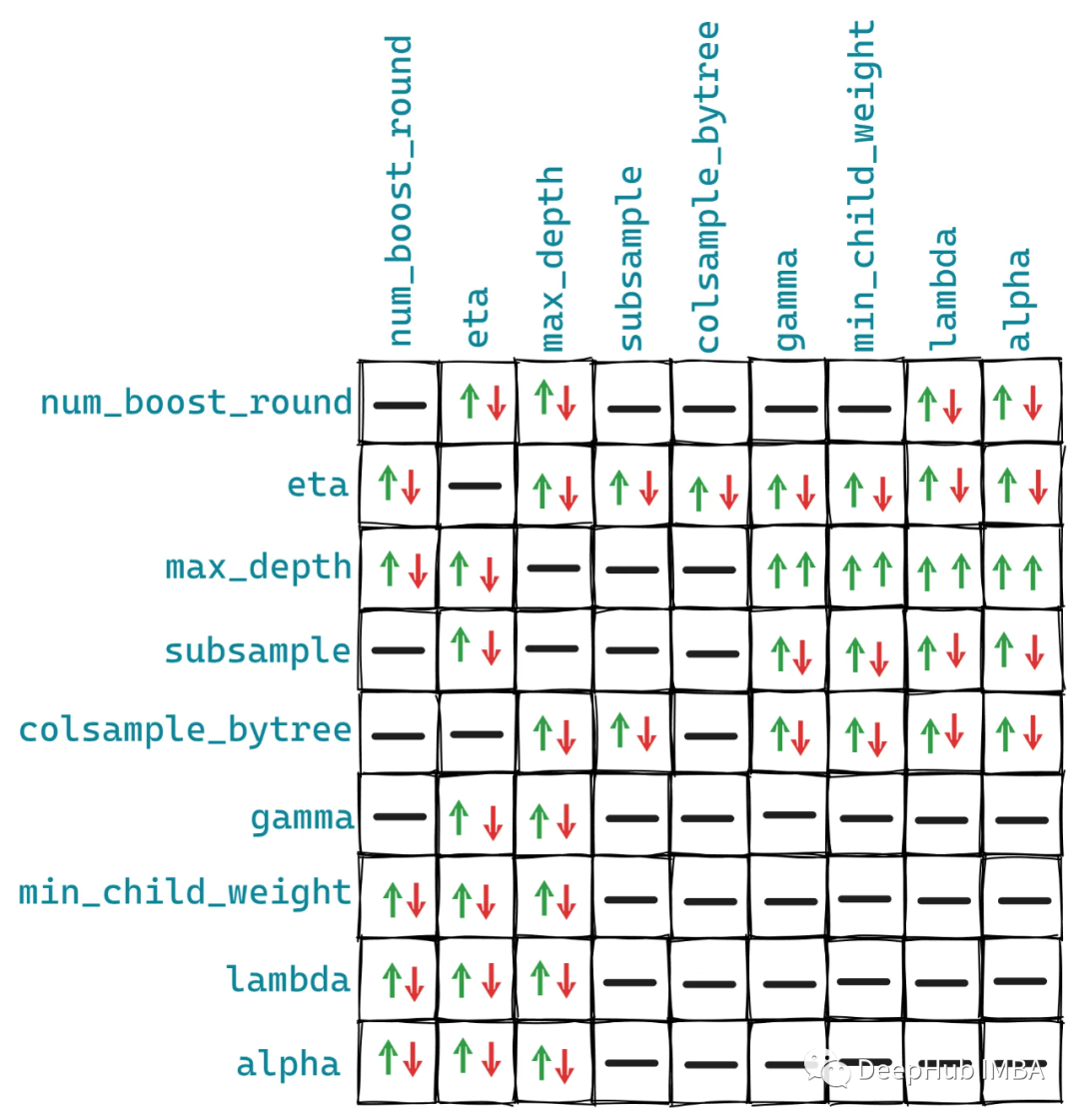
这些关系不是固定的,但是大概情况是上图的样子,因为有一些其他参数可能会对我们的者10个参数有额外的影响。
1、objective
这是我们模型的训练目标
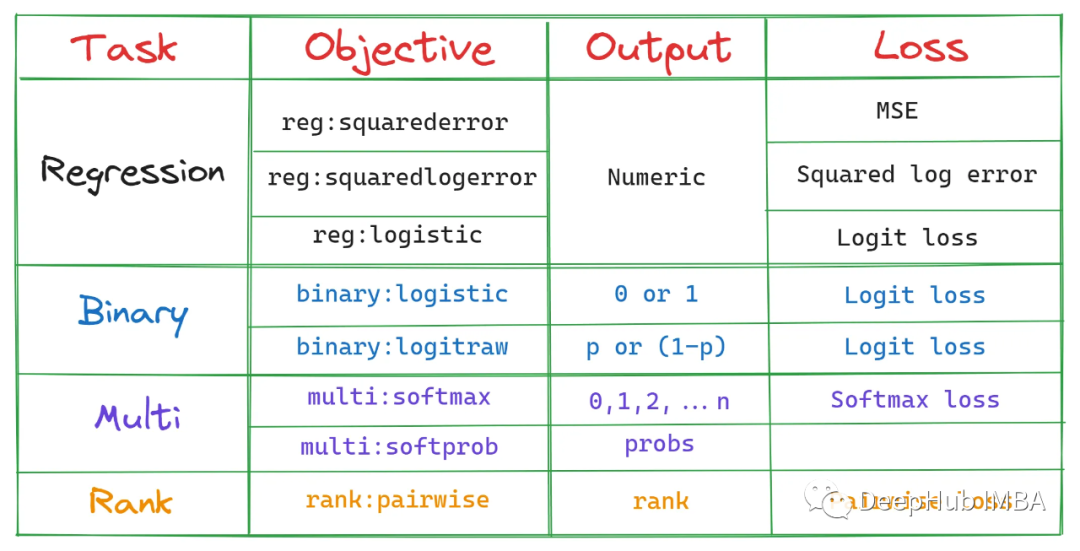
最简单的解释是,这个参数指定我们模型要做的工作,也就是影响决策树的种类和损失函数。
2、num_boost_round - n_estimators
num_boost_round指定训练期间确定要生成的决策树(在XGBoost中通常称为基础学习器)的数量。默认值是100,但对于今天的大型数据集来说,这还远远不够。
增加参数可以生成更多的树,但随着模型变得更复杂,过度拟合的机会也会显著增加。
从Kaggle中学到的一个技巧是为num_boost_round设置一个高数值,比如100,000,并利用早停获得最佳版本。
在每个提升回合中,XGBoost会生成更多的决策树来提高前一个决策树的总体得分。这就是为什么它被称为boost。这个过程一直持续到num_boost_round轮询为止,不管是否比上一轮有所改进。
但是通过使用早停技术,我们可以在验证指标没有提高时停止训练,不仅节省时间,还能防止过拟合
有了这个技巧,我们甚至不需要调优num_boost_round。下面是它在代码中的样子:
# Define the rest of the params
params = {...}
# Build the train/validation sets
dtrain_final = xgb.DMatrix(X_train, label=y_train)
dvalid_final = xgb.DMatrix(X_valid, label=y_valid)
bst_final = xgb.train(
params,
dtrain_final,
num_boost_round=100000 # Set a high number
evals=[(dvalid_final, "validation")],
early_stopping_rounds=50, # Enable early stopping
verbose_eval=False,
)
上面的代码使XGBoost生成100k决策树,但是由于使用了早停,当验证分数在最后50轮中没有提高时,它将停止。一般情况下树的数量范围在5000-10000即可。控制num_boost_round也是影响训练过程运行时间的最大因素之一,因为更多的树需要更多的资源。
3、eta - learning_rate
在每一轮中,所有现有的树都会对给定的输入返回一个预测。例如,五棵树可能会返回以下对样本N的预测:
Tree 1: 0.57 Tree 2: 0.9 Tree 3: 4.25 Tree 4: 6.4 Tree 5: 2.1
为了返回最终的预测,需要对这些输出进行汇总,但在此之前XGBoost使用一个称为eta或学习率的参数缩小或缩放它们。缩放后最终输出为:
output = eta * (0.57 + 0.9 + 4.25 + 6.4 + 2.1)
大的学习率给集合中每棵树的贡献赋予了更大的权重,但这可能会导致过拟合/不稳定,会加快训练时间。而较低的学习率抑制了每棵树的贡献,使学习过程更慢但更健壮。这种学习率参数的正则化效应对复杂和有噪声的数据集特别有用。
学习率与num_boost_round、max_depth、subsample和colsample_bytree等其他参数呈反比关系。较低的学习率需要较高的这些参数值,反之亦然。但是一般情况下不必担心这些参数之间的相互作用,因为我们将使用自动调优找到最佳组合。
4、subsample和colsample_bytree
子抽样subsample它将更多的随机性引入到训练中,从而有助于对抗过拟合。
Subsample =0.7意味着集合中的每个决策树将在随机选择的70%可用数据上进行训练。值1.0表示将使用所有行(不进行子抽样)。
与subsample类似,也有colsample_bytree。顾名思义,colsample_bytree控制每个决策树将使用的特征的比例。Colsample_bytree =0.8使每个树使用每个树中随机80%的可用特征(列)。
调整这两个参数可以控制偏差和方差之间的权衡。使用较小的值降低了树之间的相关性,增加了集合中的多样性,有助于提高泛化和减少过拟合。
但是它们可能会引入更多的噪声,增加模型的偏差。而使用较大的值会增加树之间的相关性,降低多样性并可能导致过拟合。
5、max_depth
最大深度max_depth控制决策树在训练过程中可能达到的最大层次数。
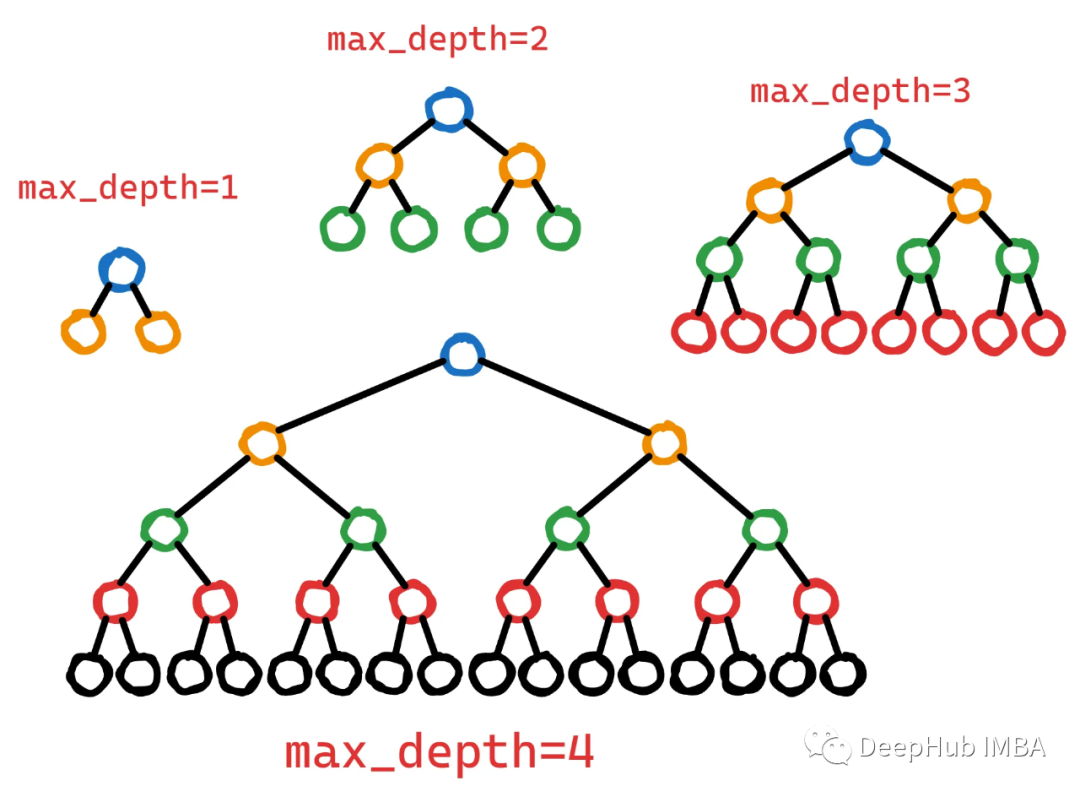
更深的树可以捕获特征之间更复杂的相互作用。但是更深的树也有更高的过拟合风险,因为它们可以记住训练数据中的噪声或不相关的模式。为了控制这种复杂性,可以限制max_depth,从而生成更浅、更简单的树,并捕获更通用的模式。
Max_depth数值可以很好地平衡了复杂性和泛化。
6、7、alpha,lambda
这两个参数一起说是因为alpha (L1)和lambda (L2)是两个帮助过拟合的正则化参数。
与其他正则化参数的区别在于,它们可以将不重要或不重要的特征的权重缩小到0(特别是alpha),从而获得具有更少特征的模型,从而降低复杂性。
alpha和lambda的效果可能受到max_depth、subsample和colsample_bytree等其他参数的影响。更高的alpha或lambda值可能需要调整其他参数来补偿增加的正则化。例如,较高的alpha值可能受益于较大的subsample值,因为这样可以保持模型多样性并防止欠拟合。
8、gamma
如果你读过XGBoost文档,它说gamma是:
在树的叶节点上进行进一步分区所需的最小损失减少。
英文原文:the minimum loss reduction required to make a further partition on a leaf node of the tree.
我觉得除了写这句话的人,其他人都看不懂。让我们看看它到底是什么,下面是一个两层决策树:
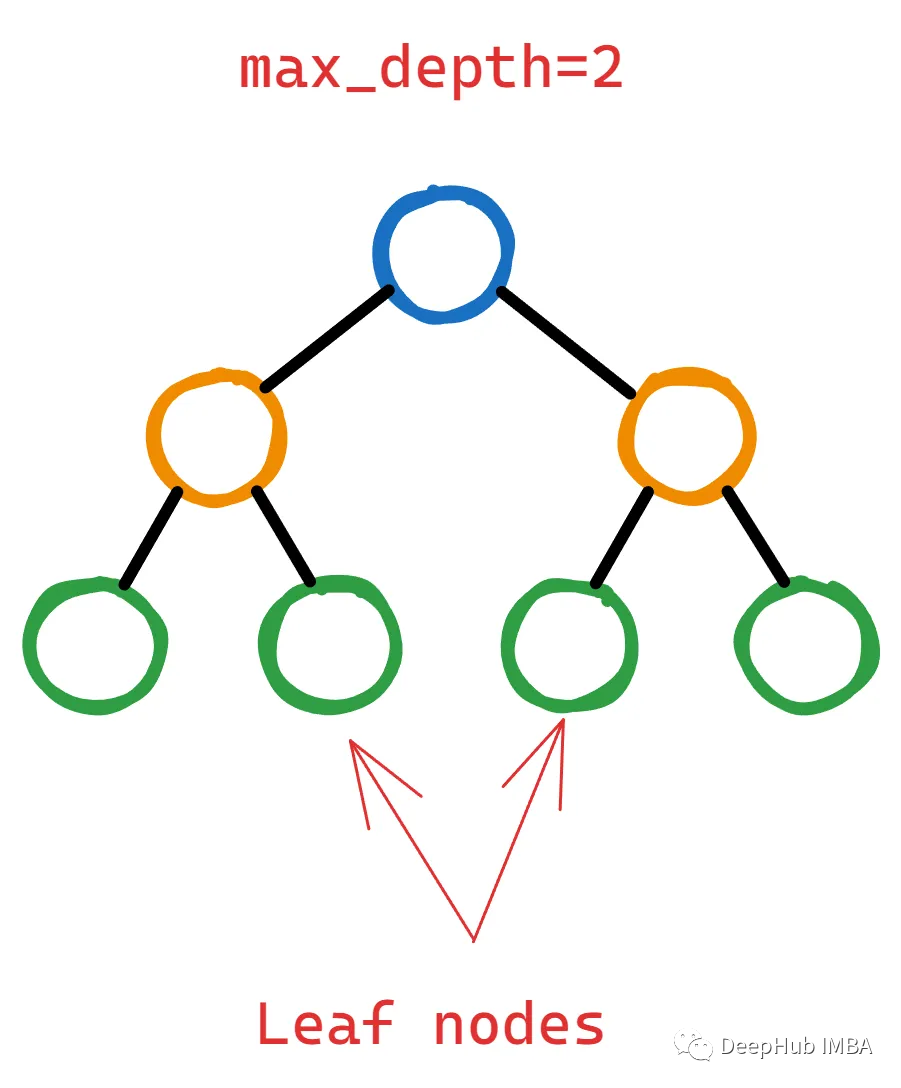
为了证明通过拆分叶节点向树中添加更多层是合理的,XGBoost应该计算出该操作能够显著降低损失函数。
但“显著是多少呢?”这就是gamma——它作为一个阈值来决定一个叶节点是否应该进一步分割。
如果损失函数的减少(通常称为增益)在潜在分裂后小于选择的伽马,则不执行分裂。这意味着叶节点将保持不变,并且树不会从该点开始生长。
所以调优的目标是找到导致损失函数最大减少的最佳分割,这意味着改进的模型性能。
9、min_child_weight
XGBoost从具有单个根节点的单个决策树开始初始训练过程。该节点包含所有训练实例(行)。然后随着 XGBoost 选择潜在的特征和分割标准最大程度地减少损失,更深的节点将包含越来越少的实例。
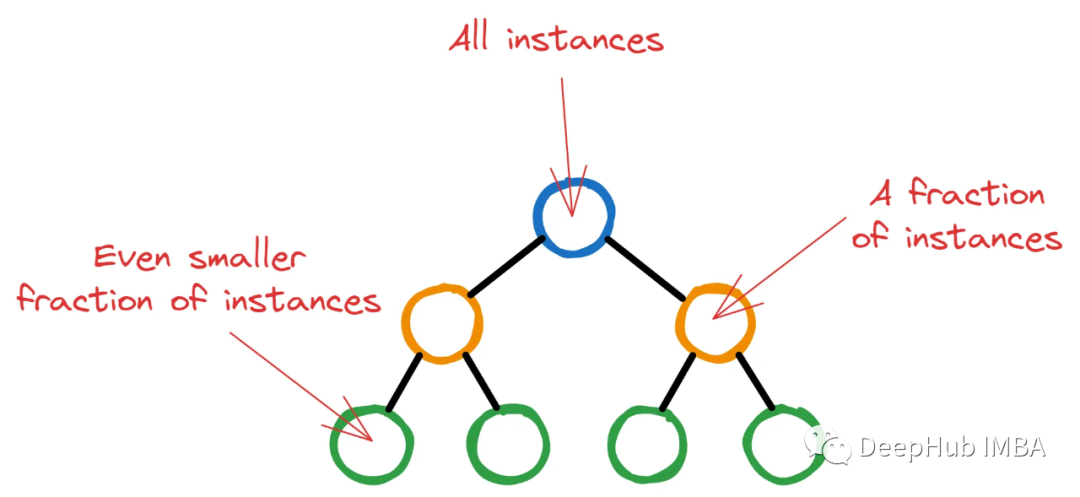
如果让XGBoost任意运行,树可能会长到最后节点中只有几个无关紧要的实例。这种情况是非常不可取的,因为这正是过度拟合的定义。
所以XGBoost为每个节点中继续分割的最小实例数设置一个阈值。通过对节点中的所有实例进行加权,并找到权重的总和,如果这个最终权重小于min_child_weight,则分裂停止,节点成为叶节点。
上面解释是对整个过程的最简化的版本,因为我们主要介绍他的概念。
总结
以上就是我们对这 10个重要的超参数的解释,如果你想更深入的了解仍有很多东西需要学习。所以建议给ChatGPT以下两个提示:
1) Explain the {parameter_name} XGBoost parameter in detail and how to choose values for it wisely.
2) Describe how {parameter_name} fits into the step-by-step tree-building process of XGBoost.
它肯定比我讲的明白,对吧。
-
60.60 作业讲解9最近邻域法的参数调优 #硬声创作季充八万 2023-07-19
-
PID参数的初始设置若干意见2016-02-01 0
-
参数寻优的迭代法的基本原理是什么?伺服控制系统常用参数寻优算法是什么?2021-10-13 0
-
HarmonyOS NEXT调优工具Smart Perf Host高效使用指南2023-11-09 0
-
通过学习PPT地址和xgboost导读和实战地址来对xgboost原理和应用分析2018-01-02 6239
-
面试中出现有关Xgboost总结2019-03-20 4356
-
XGBoost原理概述 XGBoost和GBDT的区别2019-07-16 77901
-
详细解释XGBoost中十个最常用超参数2023-06-19 928
-
XGBoost 2.0介绍2023-11-03 251
全部0条评论

快来发表一下你的评论吧 !
