

通过几个实例说明如何减轻CPU负担
描述
CPU运行时间是宝贵的资源,我们要把有限的CPU时间投入到更有意义的事情中去。
在我们进行嵌入式开发的过程中,你一定干过这几件事:用GPIO模拟某种通信接口,比如SPI等;用空循环来实现延时delay;空等寄存器的关键状态位。也许是出于无奈,比如所使用的芯片没有硬件SPI或通道不够,亦或者此时CPU除了空转并没有其它事情要作,但是我们一定要有这样的意识:这是在浪费CPU资源。
CPU是嵌入式系统的核心,但是它不必深入参与到每一个细节中去。记住:CPU是片上所有硬件资源的统领者,而非事必躬亲的苦力。我们要学会尽最大可能充分利用片上硬件资源,甚至在芯片外部扩展一些专门的硬件电路来完成功能设计。
本章振南将通过几个实例来向大家说明如何减轻CPU负担,而用片内片外的硬件来实现我们想要的功能。
1. 石油测井仪器
0x01
背景知识
在我的职业生涯中,有5年多的时间在作石油仪器。这是一个很传统的行业,但也是非常综合性和吃技术的行业。
有人说:“你这一章似乎要讲的是CPU的利用率问题,怎么又讲起石油仪器来了?”别急,振南自有用意。
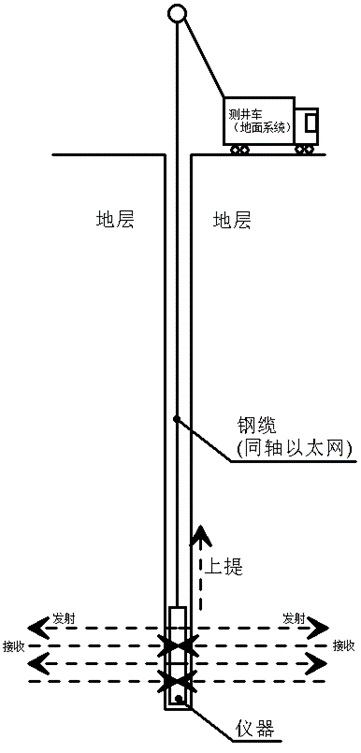
上图所示为石油测井系统的简易拓扑示意图。工作时测井车通过轮盘拉动钢缆上提,与此同时仪器向外发射信号(电或超声),并接收返回信号经过计算将结果通过同轴以太网上传到地面系统,由上位机绘制出曲线。最终曲线将交给解释工程师,来判断油气储层的位置。
上提的速度是一定的,我们当然希望在某一个深度上多采集一些数据,即尽量提高采样率。这样最终的测井曲线上就能体现出更多的细节。
OK,这就是最基本的原理和背景。
0x02
测井数据采传的实现
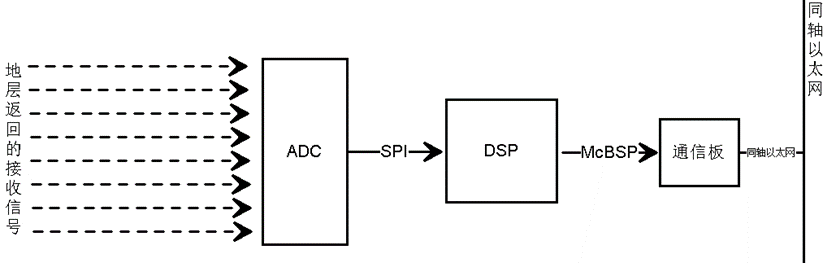
电路上比较清晰,下图为测井仪器数据采传原理框图:
最直接的初级方案
最直接的方案是所有人都能想到的方案,就是采集、计算、发送按部就班的进行,如下图所示。
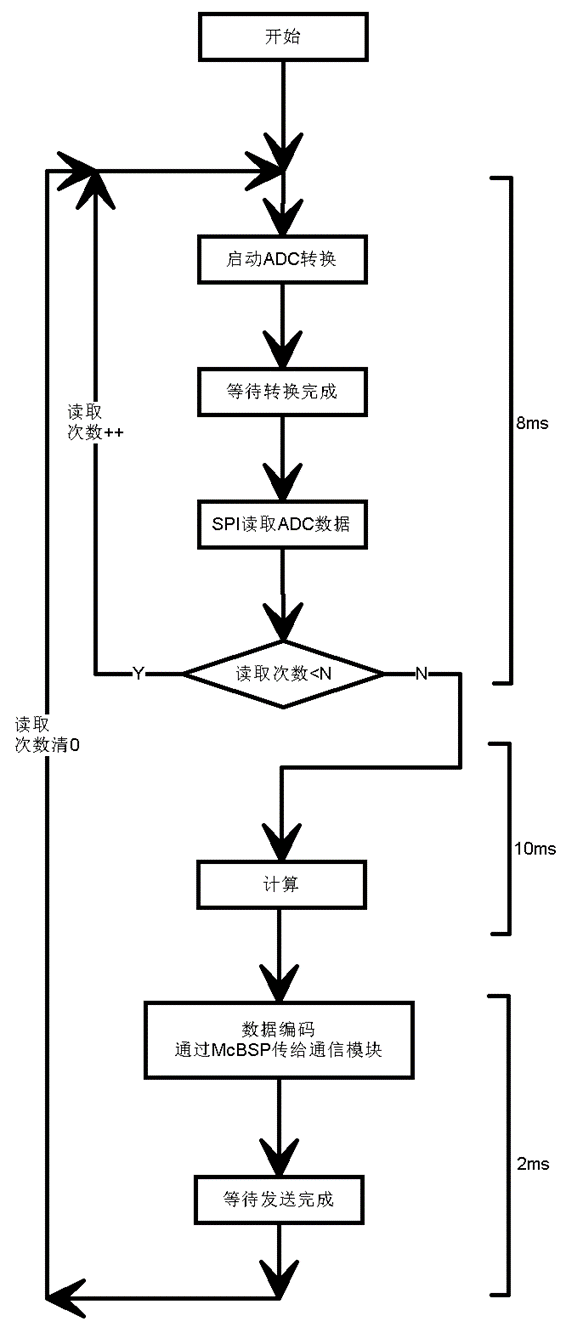
每一个周期要作的事情就是:ADC采集一段波形,然后进行计算,主要是一些数字滤波、FFT、DPSD之类的数字信号处理,最终将结果数据按协议格式打包通过McBSP(TI DSP专有的通信接口)发送给同轴以太网通信模块。我们当然希望这个周期越短越好,这需要将一些步骤优化压缩。
加入DMA的优化方案
上面的方案,仔细看一下就会发现,它的所有操作都是需要CPU参与的,大量的时间都在等待外设。如何降低CPU的参与度,把其宝贵的时间不要浪费在空等上,而放在核心算法的计算上,如下图所示:
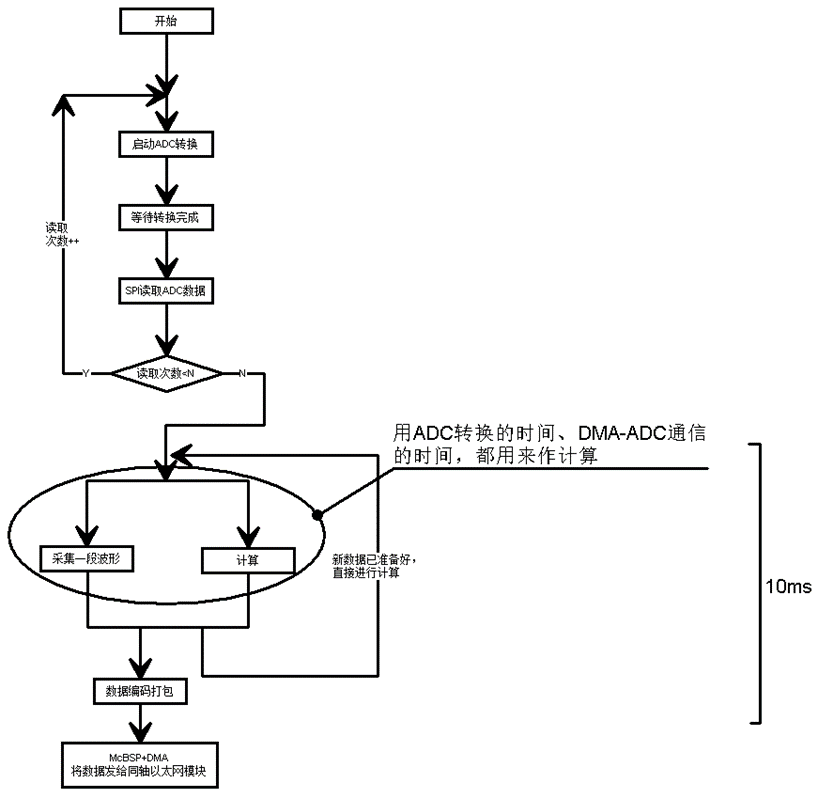
我们首先由CPU参与完成一次波形采集,然后开始针对采集数据进行计算,因为涉及大量浮点数据的数字信号处理,所以计算过程会比较花时间,一次计算大约需要花费10ms。与此同时,我们适时的不断启动ADC转换,在其转换的时间间隙里进行计算,然后直接启动SPI-DMA传输来读取ADC的转换数据,而CPU不用去等DMA传输完成,可以利用DMA传输的时间进行计算,最后回过头来立即进行下一次计算,因为此时新的波形已经准备好了。这样,一个周期的时间可以压缩到10ms,采样率比原来提高了一倍。
振南是想通过这个实例来告诉大家:CPU的运行时间是宝贵的,将片上的硬件资源充分的利用起来将可以释放出更多的CPU时间来作更有意义的事情。一些技巧和DMA的合理运用是行之有效的办法。
其实很多时候能被用来发挥的硬件资源并不只限于片内,我们自己设计一些简单的片外电路加以辅助,有时候可以达到意想不到的效果,请往下看。
2. 巧驱摄像头
0x01
摄像头时序分析
我知道很多人都对摄像头模块感兴趣,想用单片机驱动一下试试效果,但是作成功的并不多,下图为比较盛行的OV7670摄像头模块和模组:
究其原因有几点:1、摄像头CMOS芯片的时序较为复杂;2、SCCB通信及相关寄存器的配置;3、时序过快,而且是按其固有频率主动输出,难于捕捉和采集数据。
它的时序有多快,我们来看下图所示的OV7670的时序图:
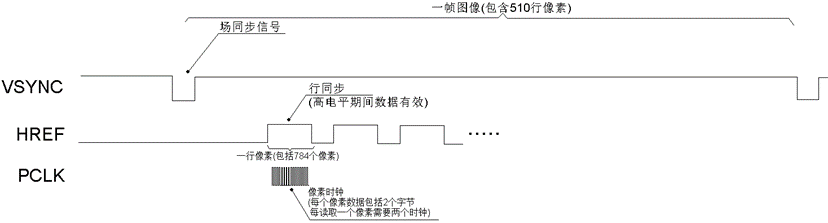
OV7670在VGA模式下可达到的最高帧率30fps,即每秒钟产生30帧640X480尺寸的图像。从官方资料上得知VGA模式下实际输出的行数为510,每行输出的像素数为784(多出来的行数与像素数是多余的,其数据是无效的,我们只关注HREF为高电平期间的像素数据)。这样,PCLK的时钟周期为1/(30510784*2)=41.7ns。想要用一般单片机的GPIO来直接采集像素数据,几乎是不可能的,因为IO与CPU的速度都不够快。
0x02
使用DCMI+DMA
要读取摄像头如此高速的数据,必须要有专门的硬件。我们可以选用ST的STM32F4系列单片机,它内置了DCMI(数字摄像头模块接口),使用它将可以很轻松的完成图像获取的功能。它要配合DMA来工作,如下图示:
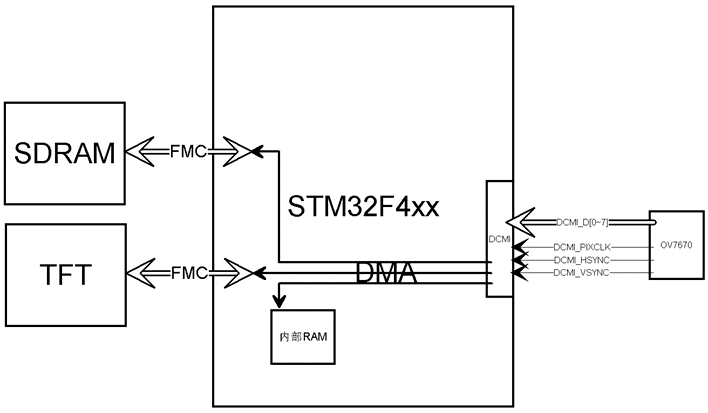
DCMI获取摄像头数据,可以通过DMA直接将数据保存到内部RAM或外部的SDRAM,甚至直接写入到TFT中,实现图像的实时动态显示。而在整个过程中,CPU只不过在作一些配置性的工作,并没有参与图像数据采集和传输。所以,用高端芯片会使我们的开发工作如虎添翼,事半功倍。就是因为它有更强大的硬件外设来为我们完成特定的功能实现。当然,更强大的硬件也意味着更多的学习成本,我们需要仔细学习如何正确的使用它来达到想要的效果。
有些时候,硬件外设电路甚至比CPU内核更复杂,比如有些多媒体编解码SOC,CPU内核只是51或M0,片上更大的面积是诸如H.264之类的编解码电路。所以,作嵌入式开发的工程师,首先要充分了解自己手上有哪些硬件资源,而不要所有功能都纯依靠CPU来实现。
0x03
自搭外部电路
本节的名字是“巧驱摄像头”,上面所介绍的方案都不算不上一个“巧”字。上述方案中必须要求单片机有DCMI之类的专用硬件,那不用DCMI可不可以?比如拿普通的51或低端的M0单片机,可不可以实现对摄像头的驱动。答案是肯定的,不过这需要我们在外部电路上作些手脚,如下图所示为通过片外并行FIFO+时序调理实现图像采集:
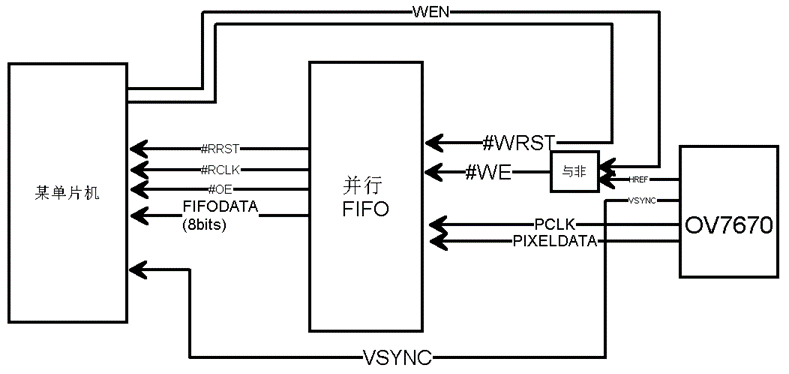
配合下面的流程图,大家就知道其巧妙之处了,如下图所示为通过片外并行FIFO实现一帧数据的获取:
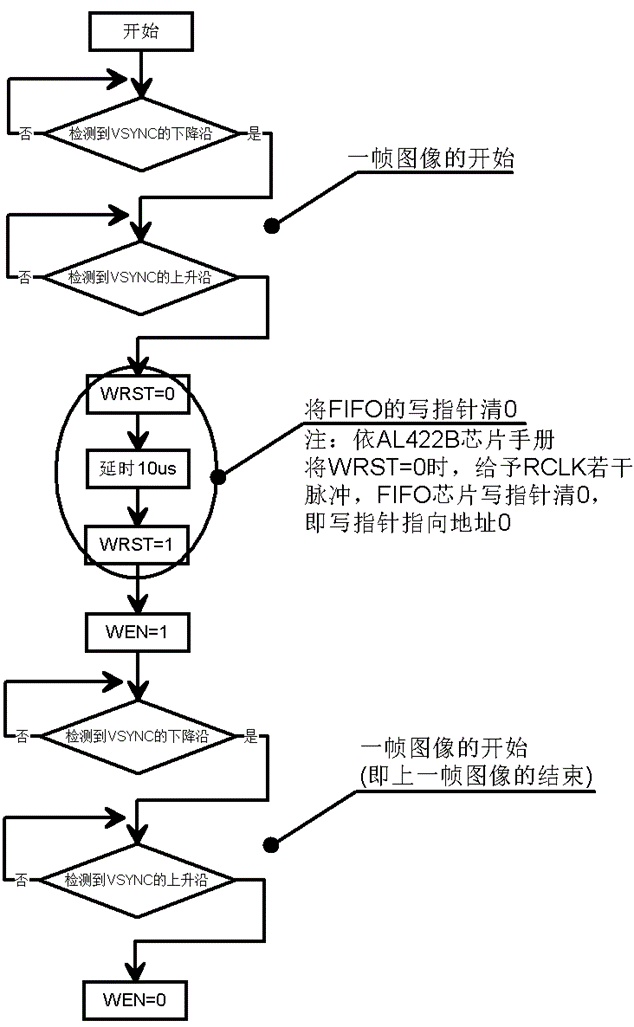
程序按上图描述的逻辑运行之后,一帧图像就存到FIFO中了。此时单片机可以慢慢从读取端(并行FIFO分为写入端与读取端,分别对应的有写指针与读指针)读到图像数据了。这样CPU和IO的速度就再也不是瓶颈。通过这样的机制,任何单片机都可以轻松实现图像采集了。
在此过程中,CPU都干了什么?似乎只有等待帧同步信号VSYNC和操作几个IO。这种方式比DCMI+DMA更省CPU(DMA实际上会占用一半的片内数据总线带宽,使CPU的运行效率降低),而且更灵活,对单片机硬件的依赖更小。
3. 单片机巧驱7寸大液晶屏
通过上面几个实例,大家应该知道振南所谓“巧驱”的路数了吧,对,就是多让硬件说话,我们要作“软硬兼施”的工程师。
OK,如果我问大家:“我能用51或M0单片机,驱动7寸大屏液晶(800*480),如图6.10,并且流畅播放视频,你信不信?”你一定会说:“不太可能吧,刷屏速率不够。”但我既然这么问,那振南一定是已经实现了,这里我就把实现过程给大家讲一下。
先来看原理图,下图为巧驱7寸液晶屏原理图之MCU部分:
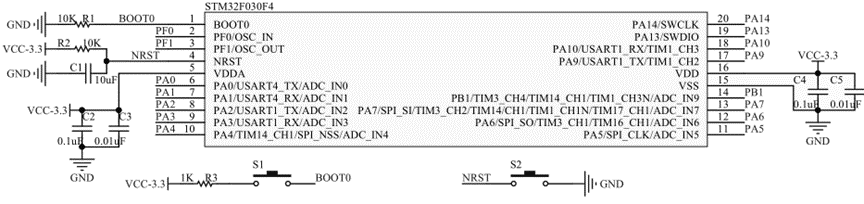
下图为巧驱7寸液晶屏原理图之74HC595串转并部分:
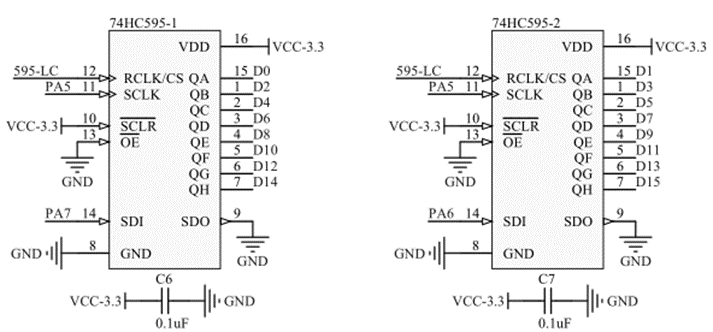
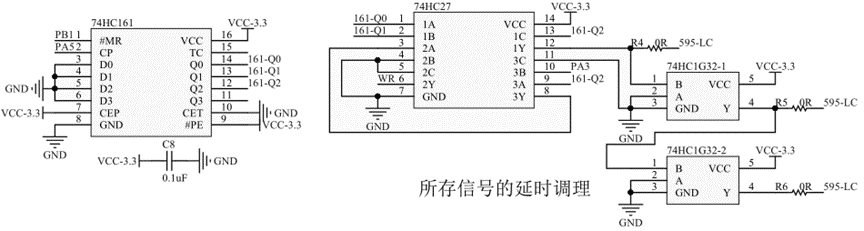
下图为巧驱7寸液晶屏原理图之八8进制计数与时序调理部分:
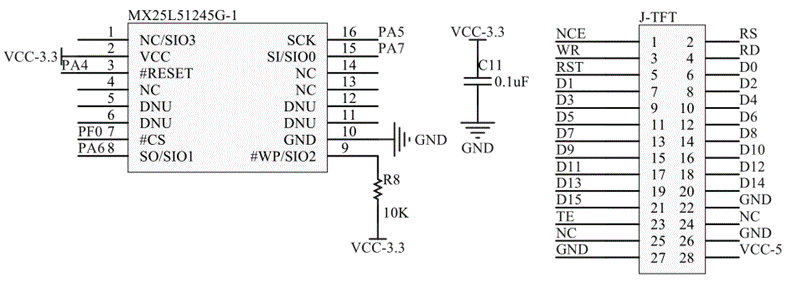
下图为巧驱7寸液晶屏原理图之spiFlash与7寸TFT接口部分:
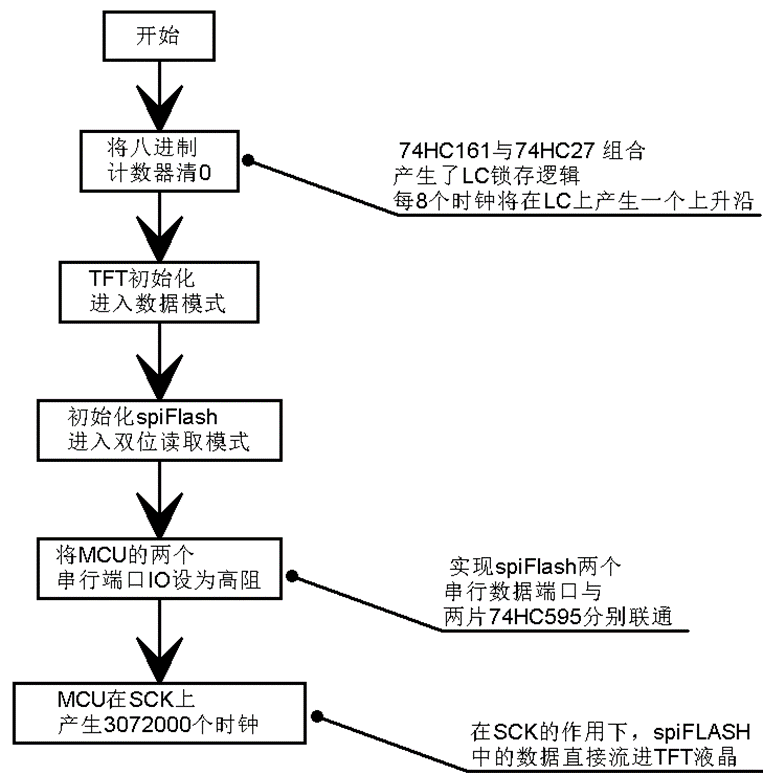
基本的实现逻辑如图6.15所示。
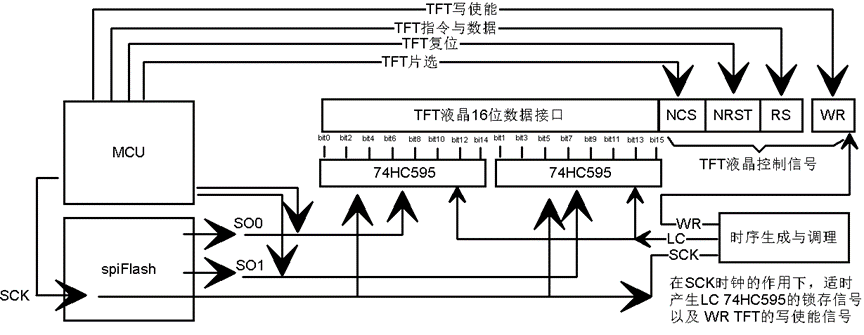
仔细观察上面的原理图与逻辑框图,估计很多人已经明白了振南的意思,振南再给出配套的流程图,逻辑就更清晰了,如下图所示:
两片74HC595用于将16位串行数据转换为并行,与TFT液晶的16位数据接口相连。74HC595的串行数据输入同时与MCU的两个GPIO以及spiFlash的两个串行数据端口相连。当spiFlash失能时(即CS置高),其数据端口呈现高阻,此时74HC595可由MCU操作;而当MCU的GPIO设置为高阻时,两片74HC595可分别接收来自spiFlash的双位串行数据。这样的复用设计,可以使MCU对TFT液晶进行预先的初始化,使其工作在纯像素数据写入的模式;而在高速数据写入的阶段,MCU退出而让TFT接收来自spiFlash的数据。
两片74HC595实现串转并的要点在于LC锁存信号的产生,每产生8个SCK脉冲,则自动产生一个LC上上升沿,这是时序生成与理调逻辑的一部分。实现的根本在于74HC161与74HC27的组合运用,如图6.13。首先对74HC161复位清零,此时[Q2:Q0]=000,74HC27是三输入或非门,其输出1Y,即595-LC为1;时钟的输入后[Q2:Q0]随之自增001、010 …… 在000之前595-LC均为0,而8个时钟之后,595-LC将变为1,即产生了上升沿。这里振南给595-LC增加了两级74HC1G32作为缓冲,为的是增加一些延时,以使74HC595的存锁数据输出更稳定。
然后是液晶的WR信号的产生:从图6.12中可以看到,WR信号是一个GPIO与八位计数器输出最高位Q2的或非非(没错,是或非非)。当Q2为0时,WR受控于GPIO,此时可用于MCU对TFT预先进行初始化操作。当GPIO为0时,WR受控于Q2,每8个时钟会产生一个下降沿(前面那个或非非是为了推迟一下这个下降沿,以使16位并行数据写入液晶更稳定),并维持4个时钟周期。
基本的要点已经描述清楚了。至于时钟的产生,唯一的要求是要产生特定数量的时钟,而不能是连续不断的。比如一帧图像的数据量为800*480半字,我们要输出3072000个时钟才能让一帧图像显示到液晶上。所以我们不能用MCO或者是PWM,而要用SPI,如果是8位SPI,要写384000次,如果是16位SPI,则要写192000次。当然,为了节省更多的CPU资源,我们可以使用DMA。当时钟不断的产生,一帧帧的图像显示到液晶上时,视频就流畅的播放出来了。
我曾经把我这个“巧驱大屏”的实验讲给了我的同事听,他们在赞叹的同时,还说:“你不作FPGA真是浪费了!”其实我是作过一段时间的FPGA的,那还是在2007年在Intel中国研究院实习工作的时候。
好了,本章用3个实例阐述了本章最开头的那句话:CPU时间是宝贵的,我们要把有限的CPU时间投入到更有意义的事情中去。
实际开发中,充分地利用硬件资源,自行灵活扩展一些硬件电路,通常可以达到意想不到的效果,甚至可以化不可能为可能。
永远记住:我们很多时候作的是嵌入式软件的工作,但归根结底我们搞的还是硬件。
审核编辑:汤梓红
-
如何进行CPU内部Flash读写的实例资料说明2019-05-29 818
-
初学的几个简单实例2013-06-13 0
-
介绍几个是常用的DMA传输路径2022-01-11 0
-
EOS说明及实例说明2017-04-13 1056
-
人工智能设备减轻影像科医生的工作负担2017-09-25 673
-
释放改革红利,减轻用户电费负担2018-07-04 2171
-
PMU如何通过执行任务减轻主CPU的负荷2018-10-10 4061
-
减轻家务负担,手持吸尘器哪个牌子好2019-06-25 252
-
巴士驾驶员辅助系统减轻工作负担2020-04-01 2895
-
集成电路设计助于减轻电源设计人员的负担2021-01-01 1561
-
MOSFET阵列并联放置多个功率MOSFET以减轻系统负担2020-12-21 5669
-
PCB设计实例说明2021-05-17 759
-
通过几个实例分析如何解电磁兼容ESD问题?2023-06-27 703
-
新唐Arm9微处理器降低CPU负担同时大幅提升加解密速度的秘密2023-08-10 598
-
请问DMA控制器可以减轻CPU负担吗?2024-03-28 206
全部0条评论

快来发表一下你的评论吧 !
