

为Spark ML算法提供GPU加速度
电子说
描述
Spark MLlib是Apache Spark用于大规模machine learning并且提供了许多流行的机器学习算法的内置实现。这些实现创建于十年前,但没有利用现代计算加速器,如 NVIDIA GPU 。
为了解决这一差距,我们最近开源了 Spark RAPIDS ML(NVIDIA/spark-rapids-ml) ,一个 Python 包,为 Py Spark ML 应用程序提供 GPU 加速。通过这样做,我们实现了以下关键目标:
应用程序编程接口:完全保留 Py Spark MLlib 基于 DataFrames 的 APISpark ML algorithms,保持与 Spark 的 Pipeline API 、 CrossValidation 等的兼容性。允许在基线 Spark ML 实现和 GPU 加速实现之间切换,只需最少的代码更改(即最多更改 Python 包导入语句)。
加快速度并节省成本:为 Spark ML 算法展示 GPU 加速带来的显著性能提升和成本节约。
体系结构:利用 NVIDIA 已经完成的大量工作来加速传统的 ML 算法。
您可以从NVIDIA/spark-rapids-mlApache v2 许可证下的 GitHub 存储库。初始版本为以下 Spark ML 算法提供了 GPU 加速度:
主成分分析
K- 均值聚类
带脊和弹性网正则化的线性回归
随机森林分类和回归
该版本还包括以下内容的 Spark ML API 兼容版本:
K 最近邻
我们之所以最初选择算法,是因为我们的第三个目标:尽可能使用现有的 NVIDIA 加速 ML 库。
具体而言,我们选择在OSS RAPIDS cuML library并为 Spark ML 中也提供的算法的现有 cuML 分布式实现提供 Py Spark API 包装器。
RAPIDS cuML 还对 Spark ML 中没有的一些流行算法进行了 GPU 加速的分布式实现,我们已经包括了 k 个最近邻居,作为为这些算法提供 Spark ML API 兼容性的概念证明。
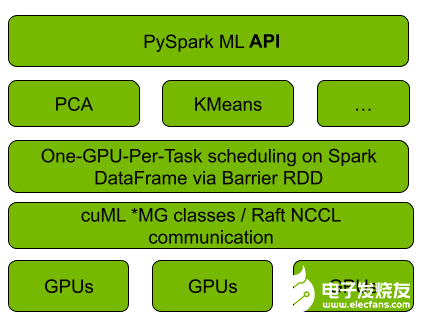
图 1 。 Spark RAPIDS ML 和 cuML 集成
图 1 显示, GPU cuML ML 与 cuML 的集成使用 Spark 的 Barrier RDD 同步和通信机制,在正在运行的 Spark cluster 上引导 cuML s 的分布式算法实现,每个 RAPIDS 工作者映射到每个 Spark 一个 Spark ]任务上。算法计算和工作人员之间的通信被推迟到 cuML 。对于后者, cuML 依赖于 NCCL 和 UCX 库来加速 GPU 之间的通信, Spark RAPIDS ML 也使用这些通信。
易于采用的 API
作为核心设计目标, Spark RAPIDS ML API 旨在将代码更改降至最低,以方便 Spark ML 开发人员采用,并促进现有 Spark ML 应用程序的迁移。
以下代码示例用于 KMean 的基线 Spark ML 和 Spark RAPIDS ML ,其中只有 Python 导入语句被更改.
py Spark 毫升
from pyspark.ml.clustering import KMeans
kmeans_estm = KMeans()
.setK(100)
.setFeaturesCol("features")
.setMaxIter(30)
kmeans_model = kmeans_estm.fit(pyspark_data_frame)
kmeans_model.write().save("saved-model")
transformed = kmeans_model.transform(pyspark_data_frame)
Spark _ RAPIDS _ ml
从 Spark _ RAPIDS _ ml 导入 KMeans
kmeans_estm = KMeans()
.setK(100)
.setFeaturesCol("features")
.setMaxIter(30)
kmeans_model = kmeans_estm.fit(pyspark_data_frame)
kmeans_model.write().save("saved-model")
transformed = kmeans_model.transform(pyspark_data_frame)
更一般地说,支持算法的 Spark RAPIDS ML 加速版本实现了 Spark ML 对应的估计器模型 API 。它们具有匹配的(在名称和数据类型上)构造函数参数、 getter 和 setter 以及模型属性和方法,在各种算法的底层 cuML 实现所支持的范围内。
相应的拟合和变换方法接受带有 VectorUDT 的 Spark 数据帧、 Spark SQL 数组或标量特征列(带有Float或Double元素类型)。目前,仅支持密集向量。
加快速度并节省成本
在本节中,我们提供了初步的基准测试结果,比较了支持算法的 GPU 加速 Spark RAPIDS ML 版本和基于 CPU 的 Spark ML 版本。
基准测试在 Databricks 的 AWS 托管 Spark 服务上的三个节点 Spark cluster (一个驱动程序,两个执行器)中运行,具有以下硬件配置:
在 CPU 集群中,m5.2xlarge执行器和驱动程序节点各有八个CPU内核和32 GB RAM。
在 GPU 集群中, g5.2x 大型执行器节点的 CPU 和 RAM 与 m5.2x 大型节点相同,还有 NVIDIA 24-GBA10GPU 。
基准测试是在适用于相应算法的 12-GB 合成数据集上运行的。它们是使用 sci-kit learn 的合成数据生成例程生成的,并以 Parquet 格式存储在 Amazon S3 上。运行时用于从 Amazon S3 加拟合方法执行端到端数据加载。我们还使用了spark-rapids plugin以加速 GPU 运行的数据加载。
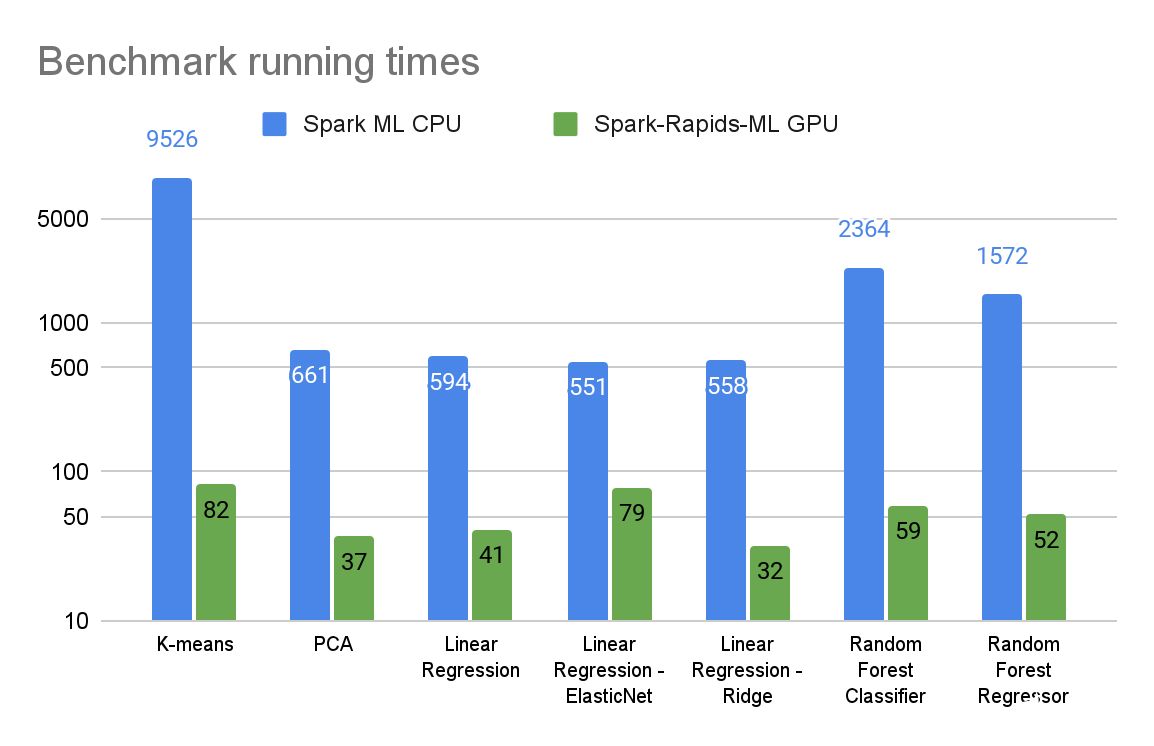 图 2 : 基于 CPU 的 Spark ML 和 GPU 加速 Spark RAPIDS ML 算法拟合方法的运行时间(秒)(对数刻度)
图 2 : 基于 CPU 的 Spark ML 和 GPU 加速 Spark RAPIDS ML 算法拟合方法的运行时间(秒)(对数刻度)
图 2 和图 3 总结了各种算法的基准测试结果。选择数据集和算法参数来表示高度计算密集型的 ML 工作负载。
图 3 中的成本效益图显示了由基准运行时间和 Databricks 的计算成本模型( DBU 加上 CPU EC2 实例成本)确定的 CPU 计算成本与 Amazon 计算成本的比率。虽然 GPU 集群每小时的成本更高,但对于这些基准测试来说,它的端到端成本效益要高得多,因为它不仅能补偿更快的运行时间。
有关更多信息和重现这些结果的步骤,请参阅NVIDIA/spark-rapids-mlGitHub。
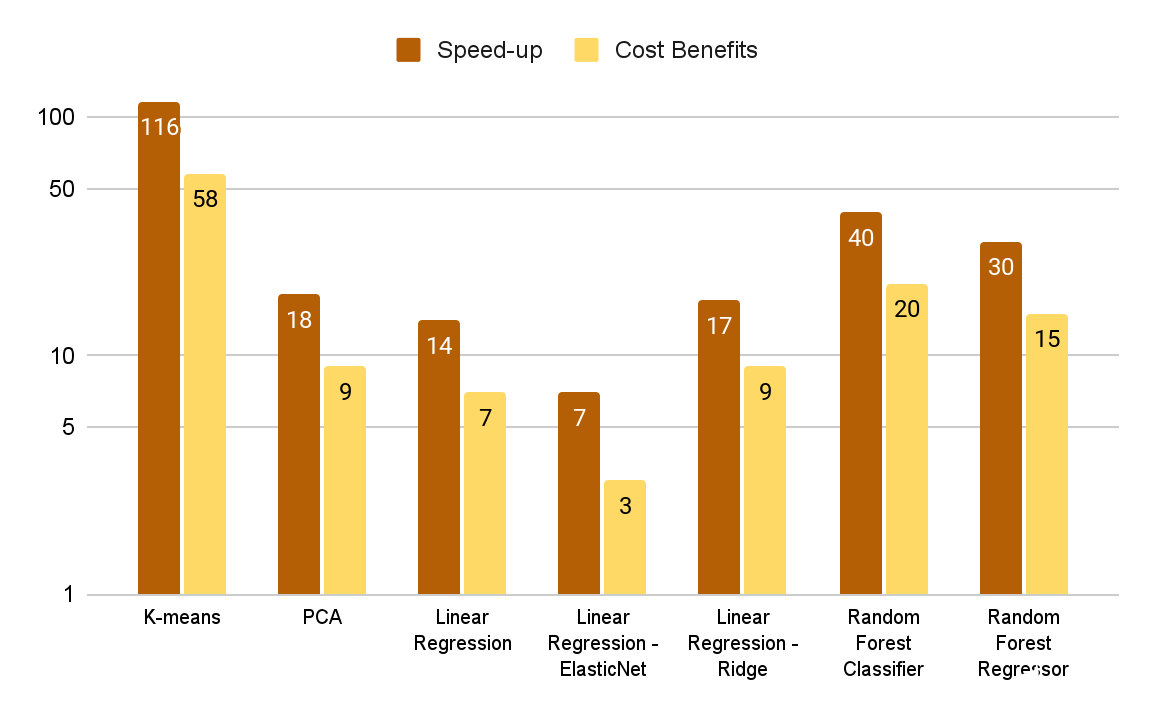 图 3 。 GPU – CPU 加速系数和相应的成本效益
图 3 。 GPU – CPU 加速系数和相应的成本效益
接下来的步骤
使用 Spark RAPIDS ML ,只需一行代码更改即可显著加快 Spark ML 应用程序的速度,并降低计算成本。
-
ADI362如何得到线性加速度的值?2024-01-01 0
-
加速度传感器的工作原理#传感器硬创客 2021-09-27
-
MMA7361 绝对加速度值2012-11-16 0
-
mpu6050如何除去重力加速度,得到实际的加速度2016-11-12 0
-
加速度、速度、位移的算法2018-01-16 0
-
请问什么是静态加速度?2018-09-28 0
-
请问ADI362如何得到线性加速度的值2018-10-09 0
-
加速度传感器的原理2018-11-08 0
-
加速度传感器原理2018-11-09 0
-
加速度传感器是什么2019-03-15 0
-
请问怎么通过MPU6050的x,,y,z轴加速度,计算出合加速度2019-04-19 0
-
加速度传感器介绍2019-05-15 0
-
介绍加速度计和陀螺仪的数学模型和基本算法2021-08-06 0
-
三轴加速度传感器原理_三轴加速度传感器应用2019-10-17 18301
全部0条评论

快来发表一下你的评论吧 !
